The bait, then the rug-pull.
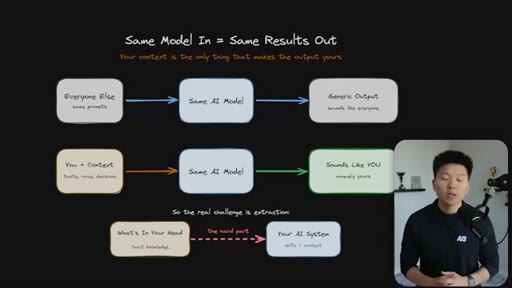
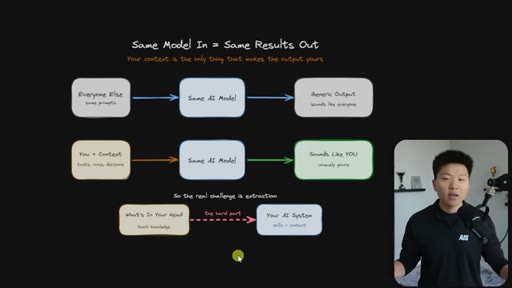
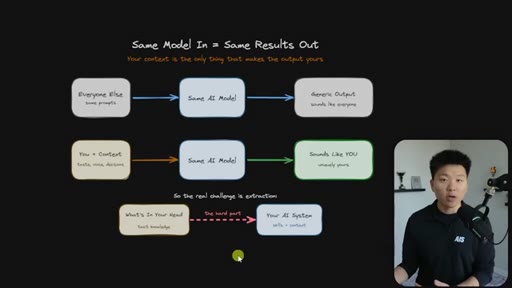
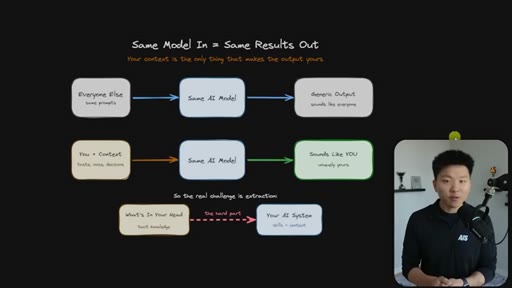
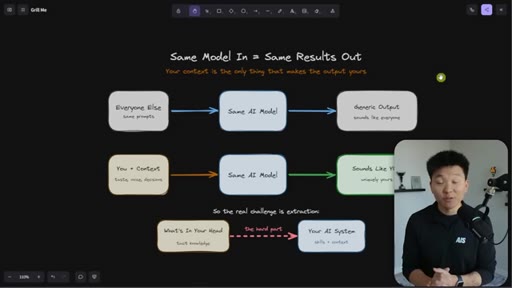
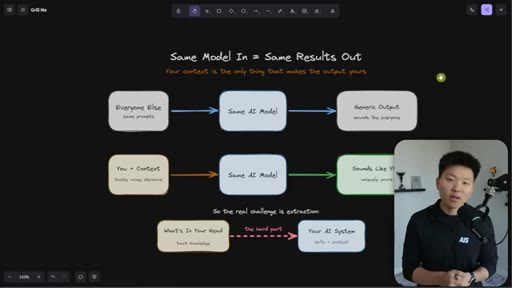
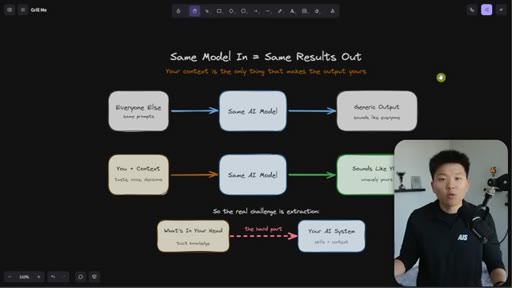
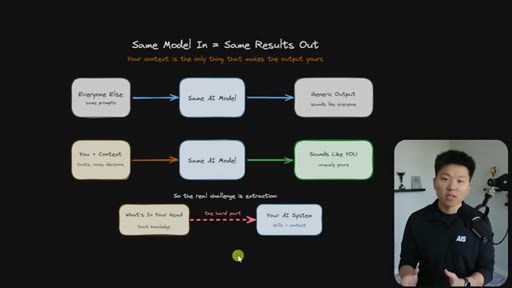
Every Claude Code builder eventually hits the same wall: the model is the same for everyone, so the outputs are the same — until you load it with everything that lives in your head. The hard part is not writing skills. The hard part is extraction.
Where the time goes.
01 · The Extraction Problem
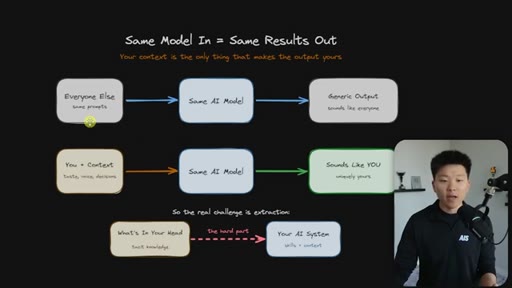
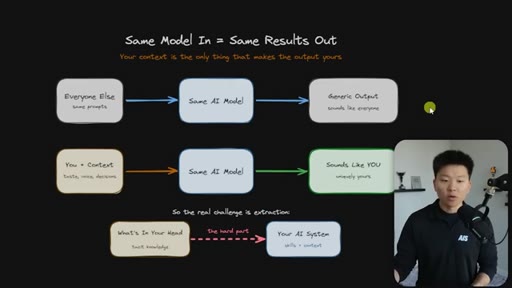
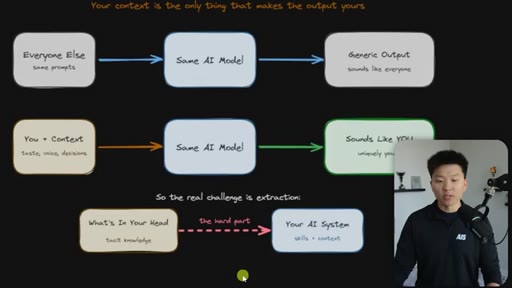
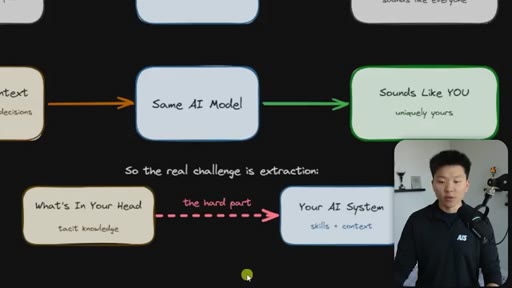
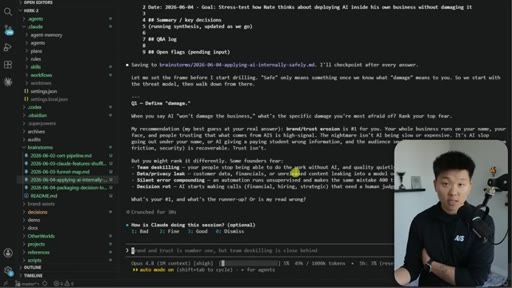
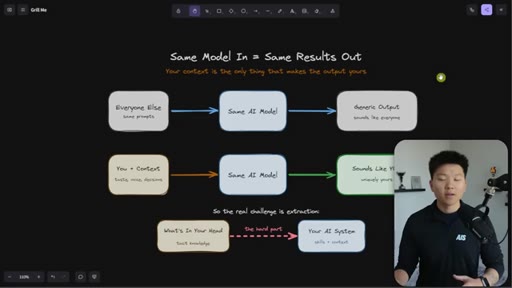
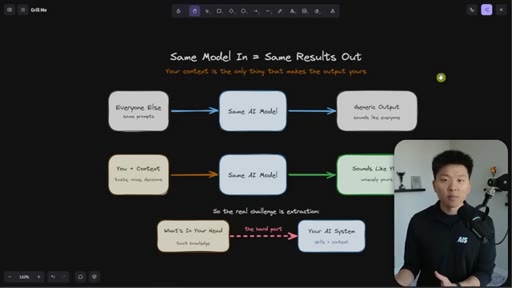
Everyone uses the same model with the same prompts and gets generic output. The only differentiator is context — and the real challenge is getting tacit knowledge from your head into the system.
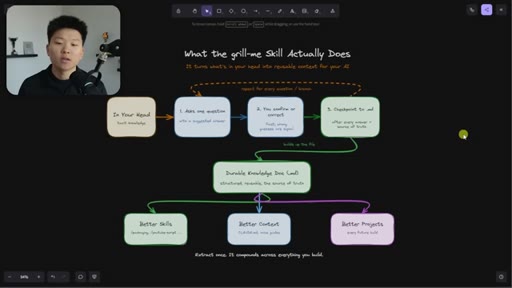
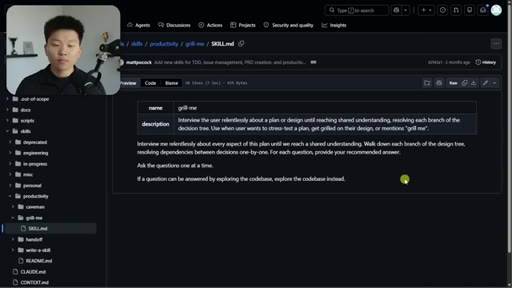
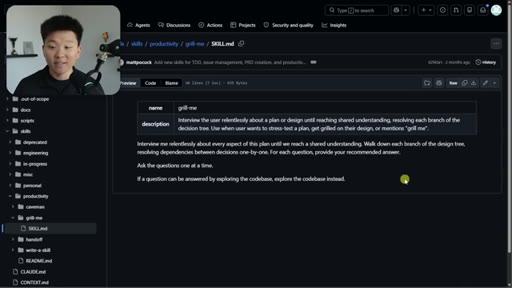
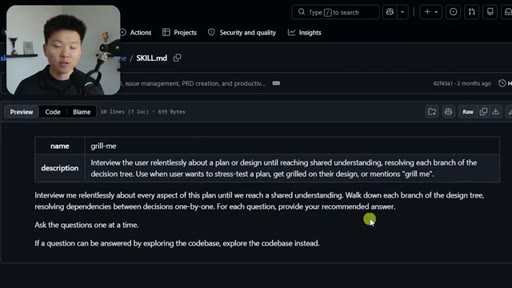
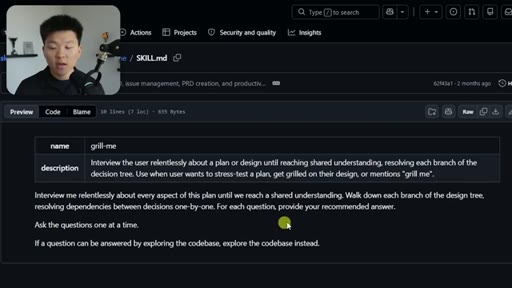
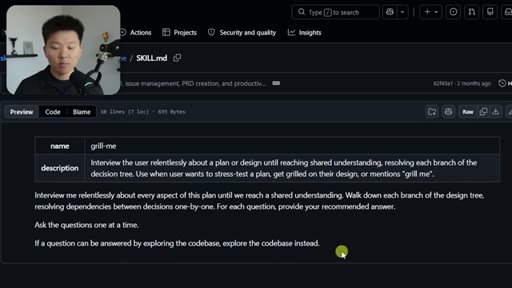
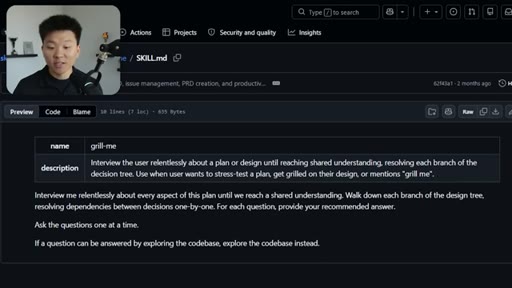
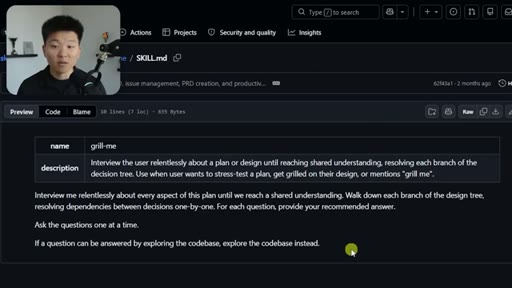
02 · What the Grill Me Skill Does
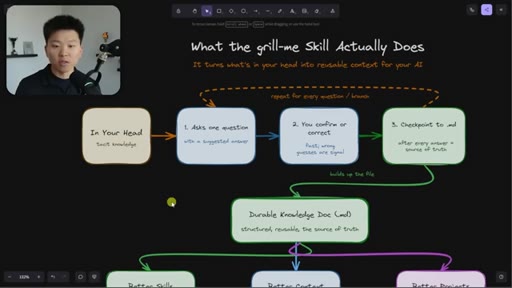
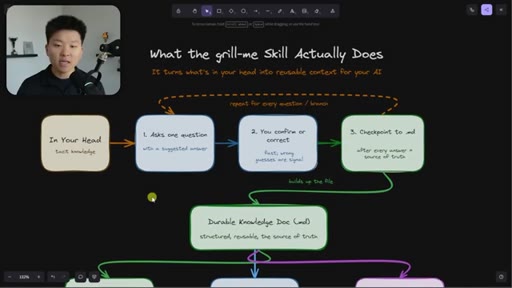
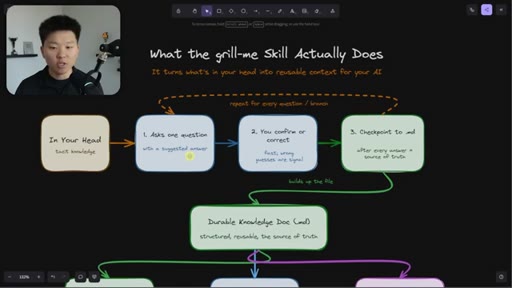
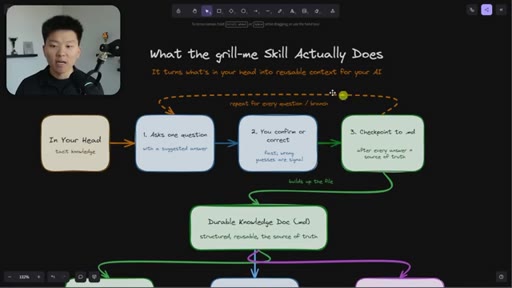
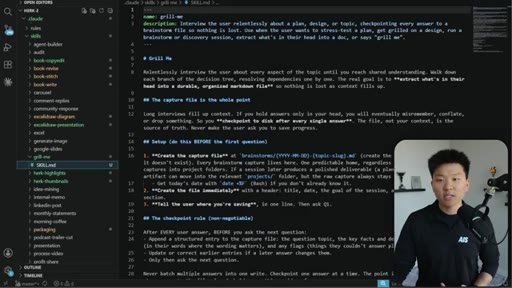
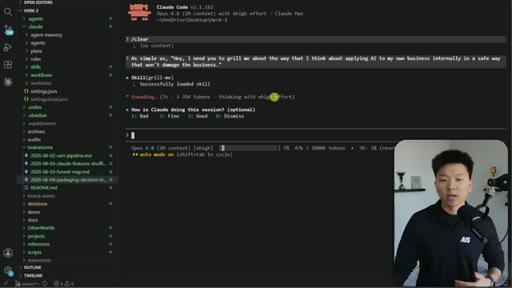
Relentless Q&A loop that grills you until no knowledge gaps remain. Original four-sentence prompt by Matt Pocock: interview me about every aspect of this plan until we reach shared understanding.
03 · Checkpointing
Why the original skill is insufficient for long sessions. Nate's enhancement: auto-checkpoint after every answer so context-window decay can't erase earlier responses.
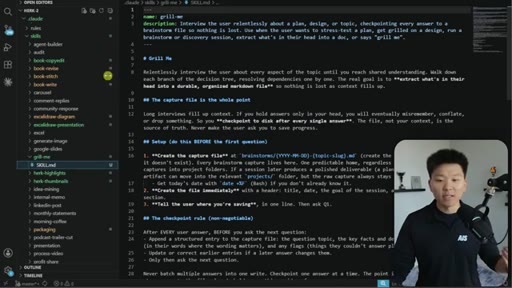
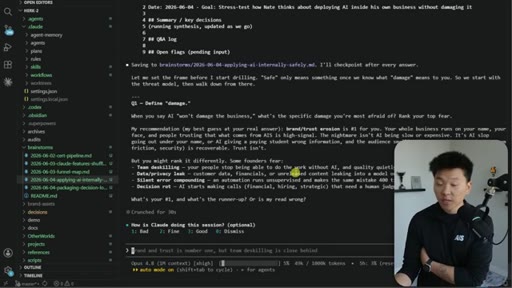
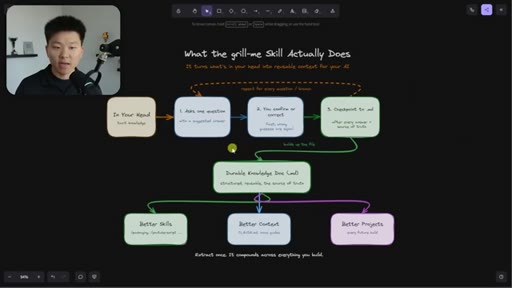
04 · Brainstorm Files in Action
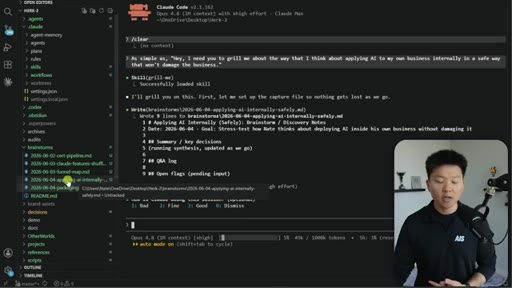
The brainstorms/ folder at project root. Live demo of a packaging session doc with Q&A log, key decisions, and the AI's auto-offer to update existing skills and guides.
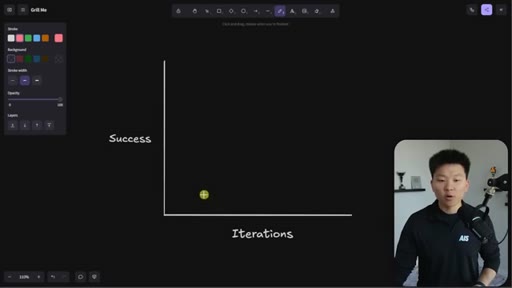
05 · Why It's Worth It
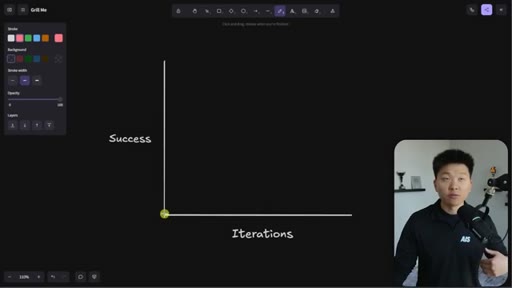
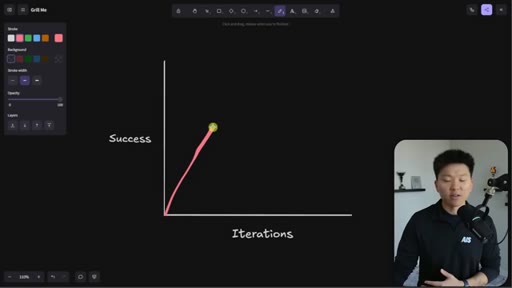
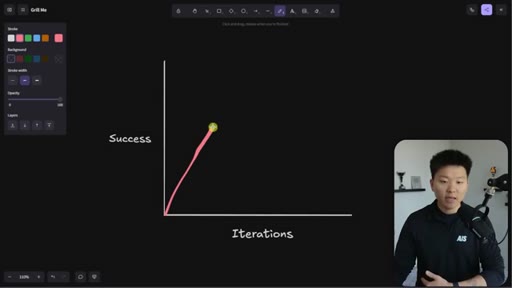
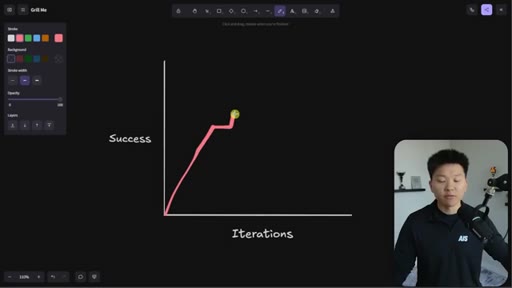
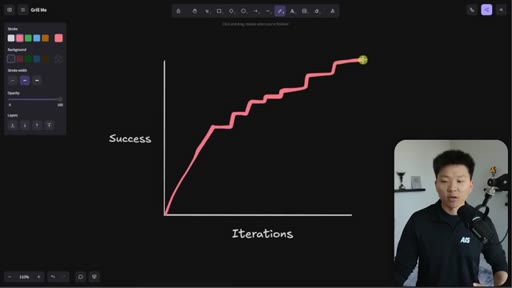
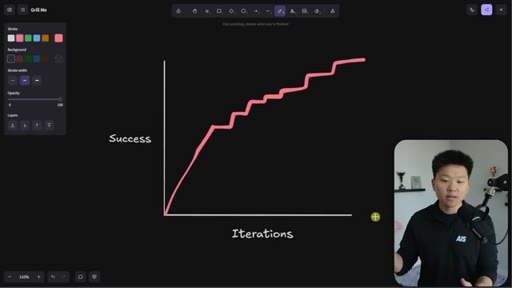
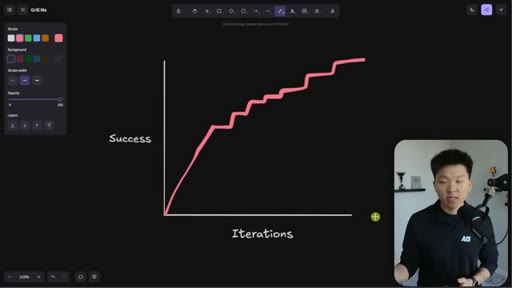
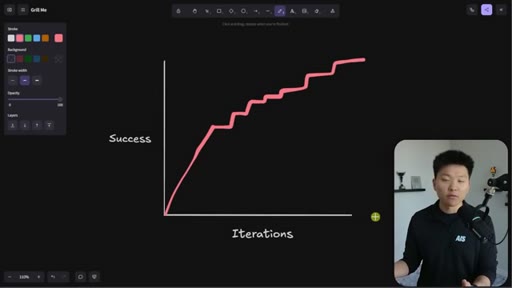
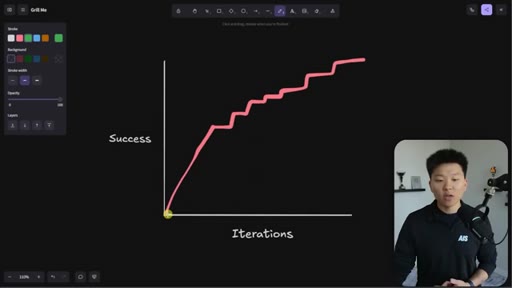
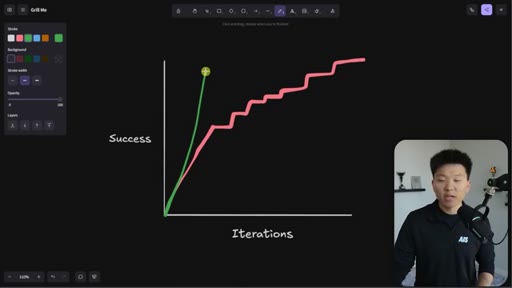
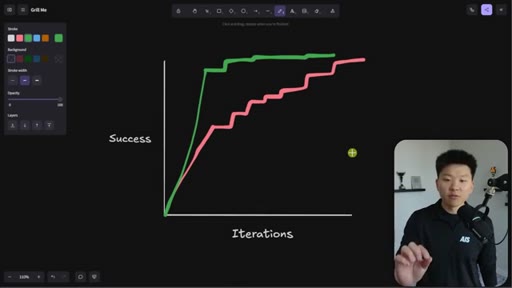
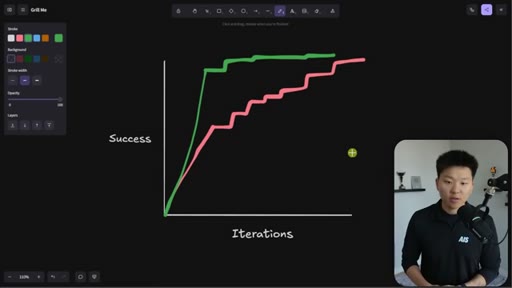
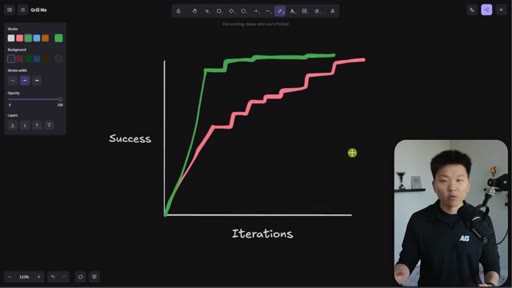
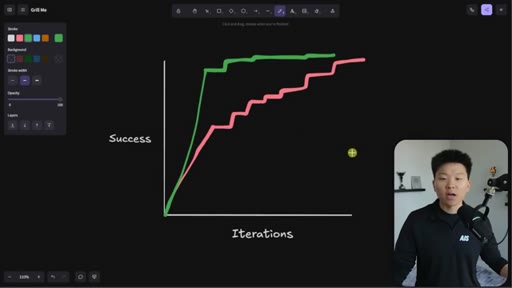
Whiteboard visualization: old path (70% on iteration 1, 30 iterations to reach 95%) vs. grill-me path (90% on iteration 1). The sharpen-the-axe argument for front-loading extraction.
06 · Get It Free + Live Demo
Where to find Matt Pocock's original and Nate's enhanced version. Live demo of invoking /grill me and watching the discovery doc scaffold in real time with open flags.
07 · Final Thoughts
Quick close and subscribe CTA.
Visual structure at a glance.
Named ideas worth stealing.
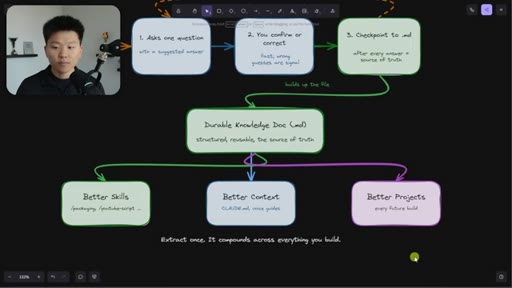
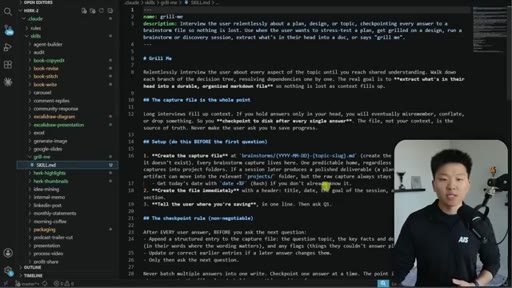
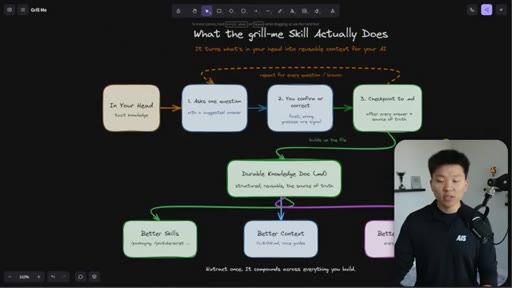
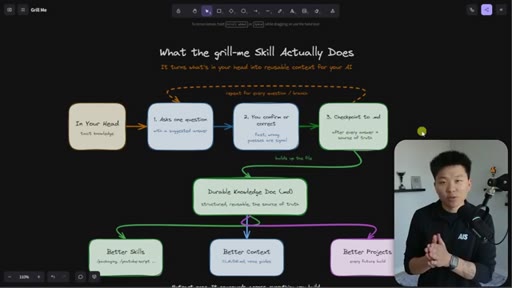
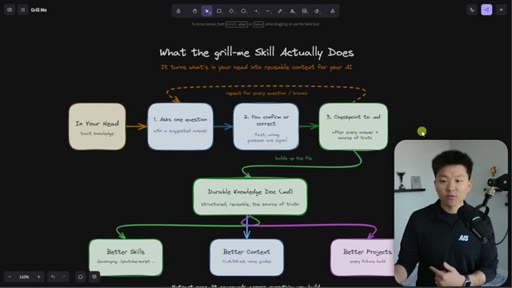
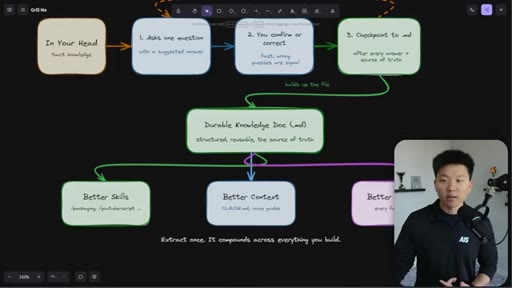
The Extraction Loop
- Ask one question
- Receive one answer
- Checkpoint to markdown doc
- Repeat until no gaps remain
The grill-me skill's core mechanism: a structured Q&A loop that writes to brainstorms/<topic>.md with sections for summary, key decisions, Q&A log, and open flags. Continues until both you and the AI agree the knowledge is complete.
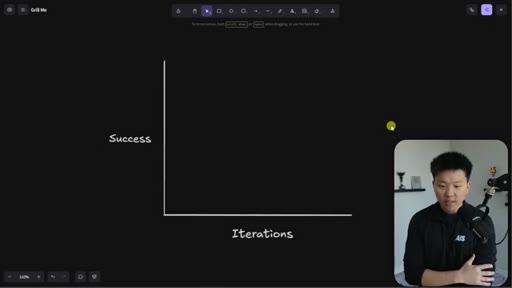
The Iteration Curve
Whiteboard framework: without extraction, a new skill starts at ~70% quality and reaches 95% after 10-30 iterations. With grill-me front-loading, iteration one starts at ~90% quality and reaches 95% in a handful of runs. The compounding benefit is earlier feedback and faster refinement.
Lines you could clip.
"It's the difference between a system that is successful 95% of the time and one that's only successful 80% of the time."
"A skill can just be a prompt that you don't wanna have to say every single time."
"If I had six hours to chop down a tree, I would spend the first four sharpening the axe."
Things they pointed at.
How they asked for the click.
"If you want my version, you can come to my free school community. The link for that is down in the description. Just join the community. Go to the classroom. Click on all YouTube resources."
Soft sell — positioned as giving away value for free. Comes at 73% through the video after the full proof-of-concept demo, which is good placement. No urgency or scarcity used.
Word for word.
Front-load extraction or grind through 30 iterations
The quality gap between a skill that starts at 70% and one that starts at 90% is almost entirely explained by how much tacit knowledge made it from your head into the system before iteration one.
- Giving Claude a five-minute brain dump is not enough — the gaps you overlook are exactly what causes failures in the edge cases that actually matter.
- A Claude Code skill can be as simple as four sentences you'd otherwise retype every session; complexity is not a prerequisite for value.
- Adding a checkpoint after every Q&A cycle prevents context-window decay from silently erasing your earliest and often most important answers in a long session.
- The brainstorms/ pattern turns a one-time extraction session into a reusable doc you can revisit and update incrementally when the process changes.
- When the AI surfaces a gap between what you discussed and what your existing docs say, having it auto-update those docs closes the loop immediately rather than letting the divergence accumulate.
- Tacit knowledge extraction is the same bottleneck whether you're building your own AI OS or scoping a client project — the tool transfers directly.