The bait, then the rug-pull.
Anthropic published its internal guide to building and scaling skills — the same playbook the company uses to run its own AI-assisted workflows. This breakdown translates the developer-centric framework into something a solo operator or small team can actually copy.
Where the time goes.

01 · Skills aren't just a markdown file
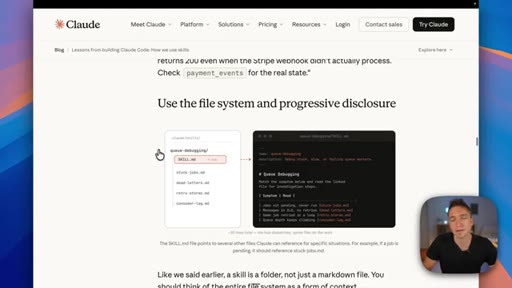
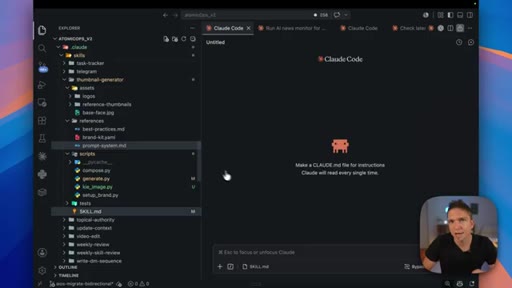
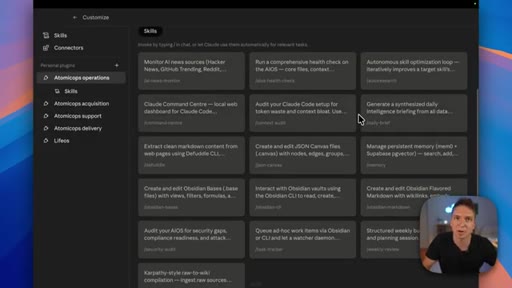
Skills are folder systems: the .md is the SOP, scripts are deterministic tools, and assets are reference examples of what good output looks like.
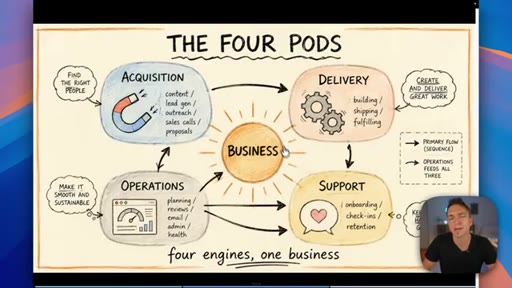
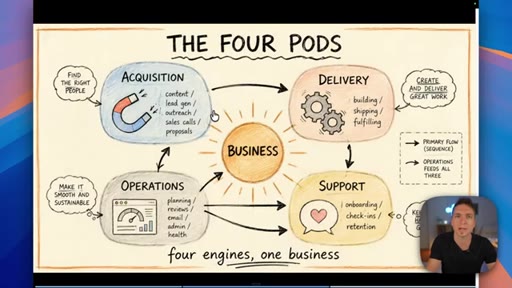
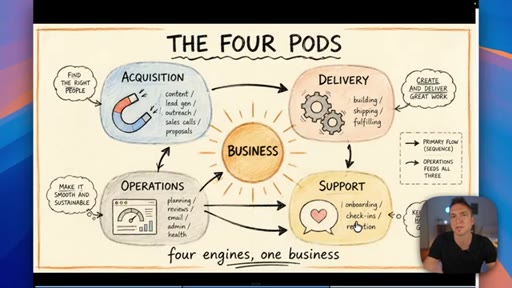
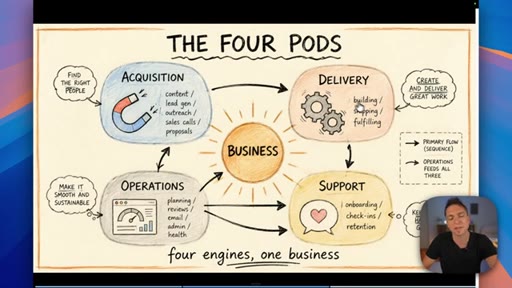
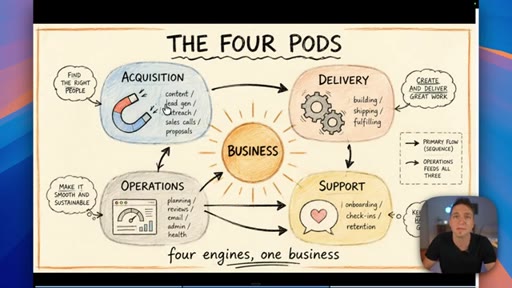
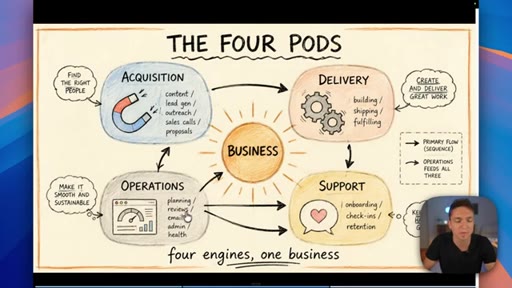
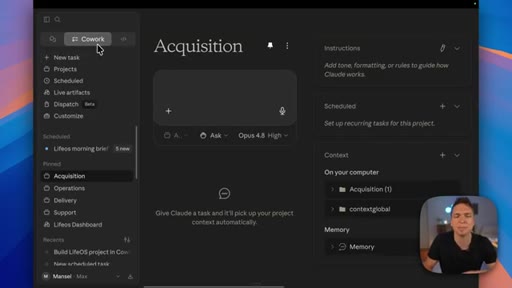
02 · Categorize your skills: the four pods
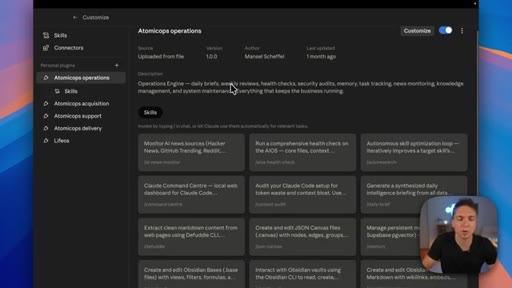
Anthropic sorts skills by technical type; the presenter maps that to four business functions — Acquisition, Delivery, Operations, Support — and shows how they map to Claude project folders.
03 · Tips for building better skills
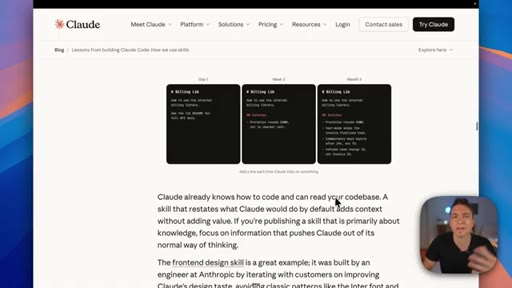
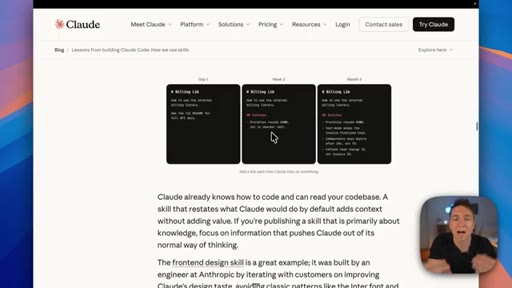
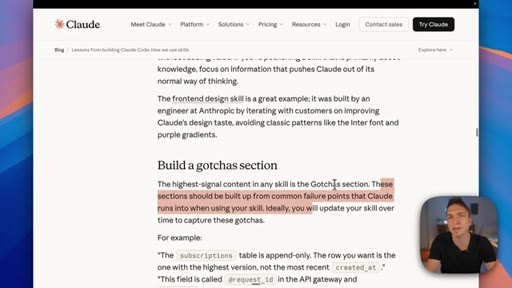
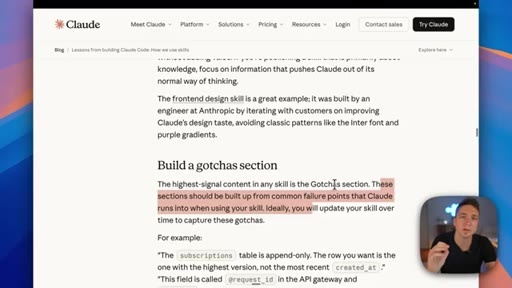
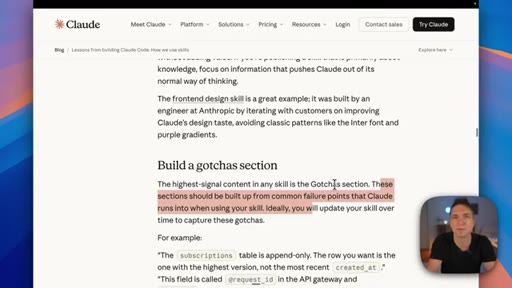
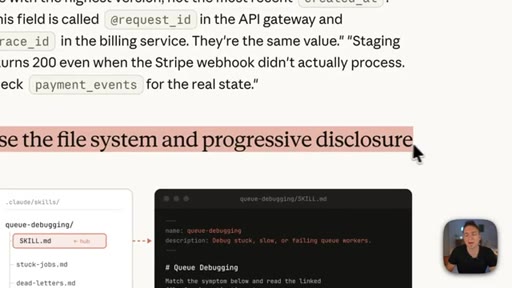
Key Anthropic tips: do not state the obvious, build a gotchas section from real failure points, write descriptions for the model not for humans, use progressive disclosure, do not railroad Claude with over-specified steps.
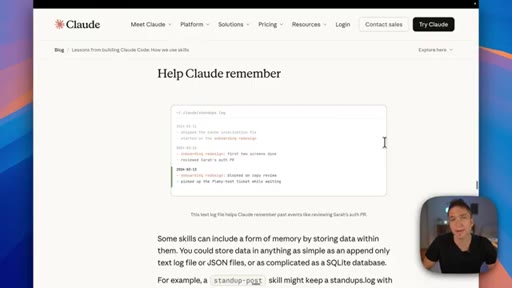
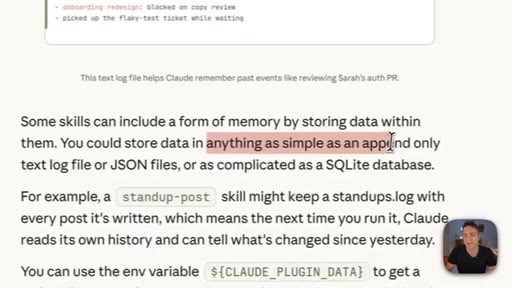
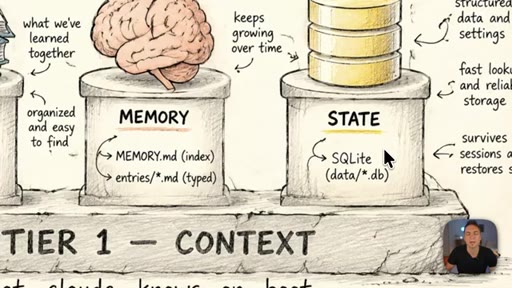
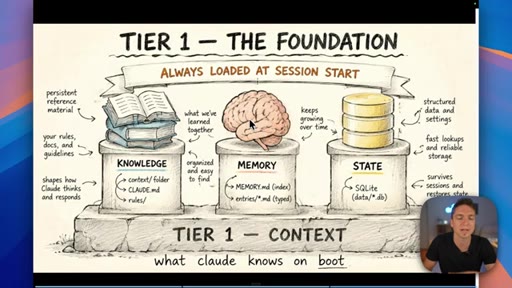
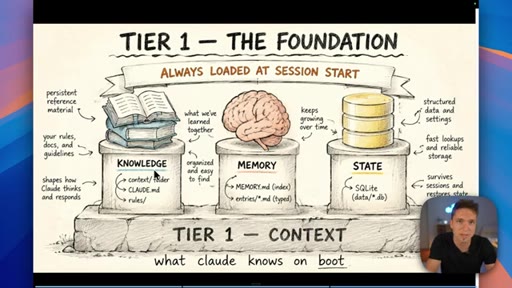
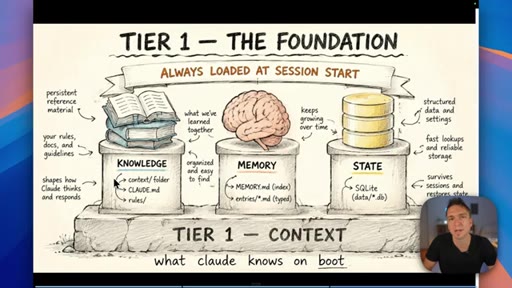
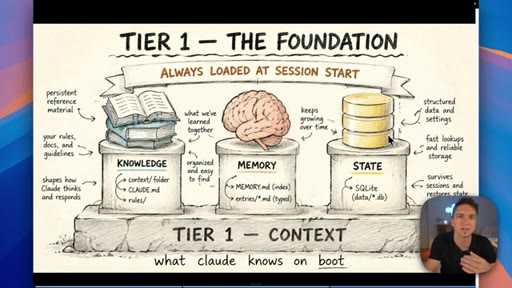
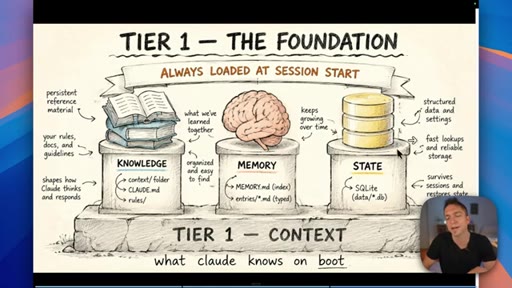
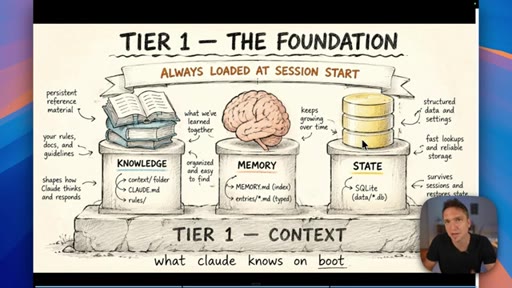
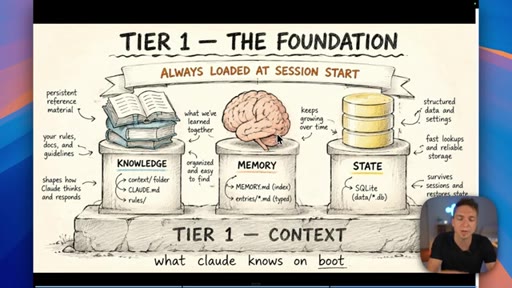
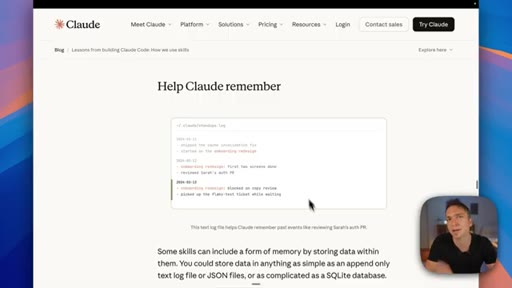
04 · The three types of Claude memory
Memory is not a single thing: Knowledge is static facts authored upfront; State is mutable workflow data stored in a database; Memory is what Claude learns from working with you over time.
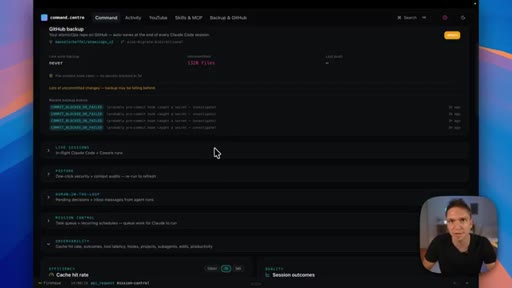
05 · How to share skills and build a plugin marketplace
Skills are portable zip files; a GitHub-backed marketplace lets teams distribute and version-control skills so everyone pulls the latest copy.
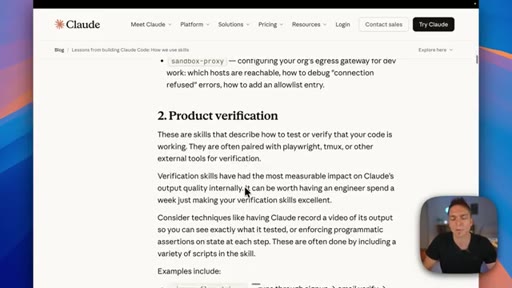
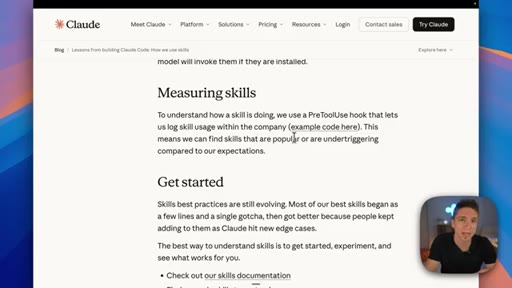
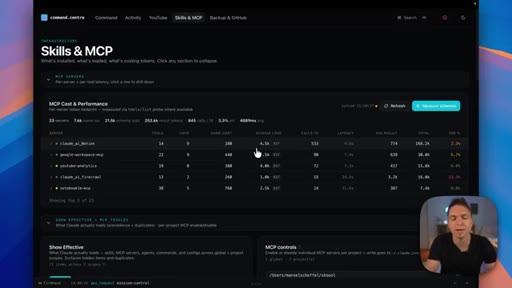
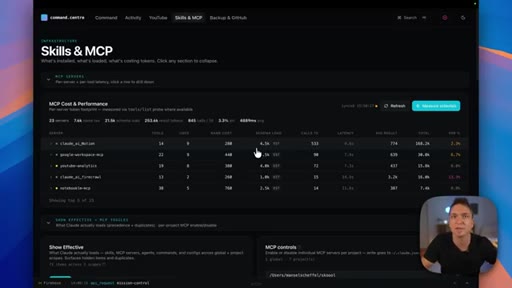
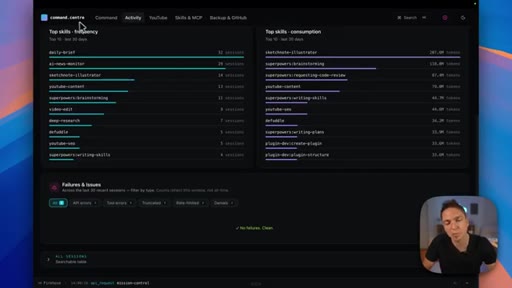
06 · Measure your skills
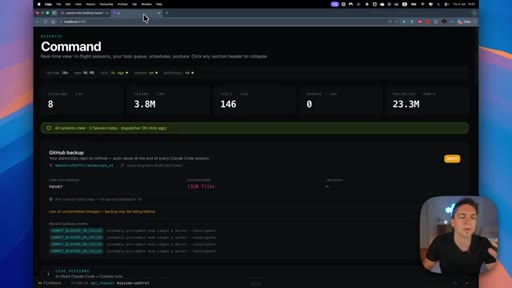
Track trigger rates, token costs, and under-triggering patterns — observability turns guessing into decisions about which skills to improve or prune.
07 · Skill injection: the security risk
Pulling unverified skills from external repos is a live attack vector; build from problems you own and understand before importing anything external.
Visual structure at a glance.
Named ideas worth stealing.
The Four Pods
- Acquisition
- Delivery
- Operations
- Support
A four-category map for organizing all business AI skills — mirrors the four core functions every business runs and maps cleanly to Claude project folder structure.
Three Tiers of Claude Memory
- Knowledge (static, authored upfront)
- State (mutable, database-stored)
- Memory (learned from interaction)
A framework for deciding where to store different types of information — prevents the common mistake of lumping everything into a single file or memory system.
Progressive Disclosure Loading
Skills load lazily — description stub first, full body second, assets on demand. Optimize the description as the decision gate; everything else loads only when matched.
Lines you could clip.
"The highest signal content in any skill is the gotcha section. These sections should be built up from common failure points that Claude runs into."
"You're not really going to get anything done in your business if your AI employee has dementia."
"Start with the problem and build it yourself. If you can speak any language, that means you can tell Claude exactly how to go and build your process from start to finish."
Things they pointed at.
How they asked for the click.
"Check out the videos on the screen — they'll definitely help you on your journey. Or you can join my community where I'm helping people and business owners solve their AI problems every single day."
Soft multiple-option close — video playlist links on screen plus community link. No hard sell.
Word for word.
The folder is the skill — architecture decides reliability.
Every gap between what Claude produces and what you want can be traced back to something missing in the skill folder — a gotcha section, a reference asset, a wrong description, or the wrong memory tier.
- The markdown file is the SOP; the scripts are deterministic tools that execute it. Without both, you get either AI drift or brittle automation that breaks on edge cases.
- Reference assets stored inside the skill folder define what done looks like — Claude loads them on demand, not at startup, so they add no token cost until they are needed.
- Mixing probabilistic AI judgment with deterministic scripts is the formula for reliable output — the markdown tells Claude what, the script locks in how.
- Mapping skills to four business functions (Acquisition, Delivery, Operations, Support) makes it obvious where a new skill belongs and prevents the folder from becoming a junk drawer.
- The same pod structure maps one-to-one to Claude project folders so that context stays scoped — Claude working inside the Acquisition project only loads Acquisition-relevant skills.
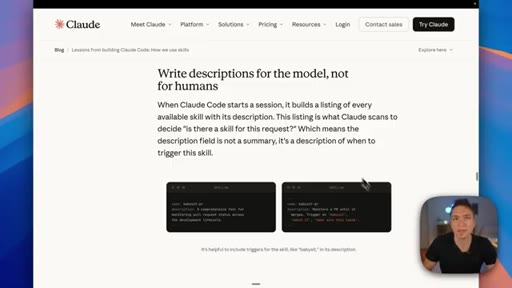
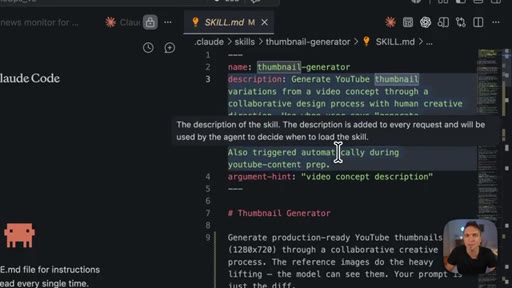
- Write descriptions for the model, not for yourself — the description is what Claude reads to decide if this skill matches a request, and most under-triggering is a description-language mismatch.
- The gotchas section is built from real failures — every time Claude produces something wrong, add it as a gotcha. The section compounds in value the longer you run the skill.
- Do not over-specify steps — telling Claude exactly how to do sub-tasks it already knows defeats the purpose. Specify the outcome and the constraints, not the mechanics.
- Knowledge is static and authored upfront; State is mutable and belongs in a database; Learned memory is what Claude accumulates from working with you. Each lives in a different system.
- A skill is self-contained by design — every reference, script, and asset lives inside the folder so you can zip it and hand it to anyone without setup instructions.
- Track which skills fire most, which fire least, and which cost the most tokens — usage data is the only reliable signal for deciding which skills to improve and which to prune.
- Pulling skills from external repositories you do not control is an active security risk — prompt injection can be embedded inside a skill definition and will execute silently.