The bait, then the rug-pull.
Anthropic's own engineers built a masterclass on dynamic workflows and released it quietly. This breakdown does the reading for you: six core patterns, the three failure modes they fix, and one honest warning that most workflow tutorials skip entirely.
Where the time goes.

01 · Intro
Six patterns from Anthropic's internal masterclass; TLDR promise.

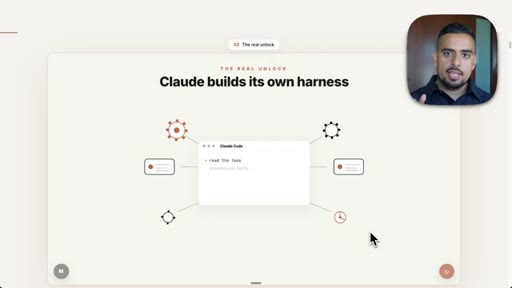
02 · The Real Unlock
Claude Code builds a custom harness on the fly, not just spawns agents.

03 · Three Failure Modes of One Context Window
Agentic laziness, self-preference bias, and goal drift all stem from a single overloaded session.
04 · How Dynamic Workflows Fix It
Separate Sonnet 4.6 agents each get a clean context window; problems are isolated.

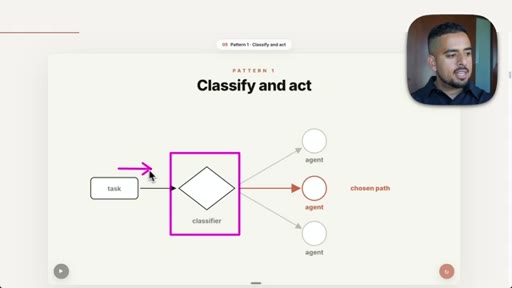
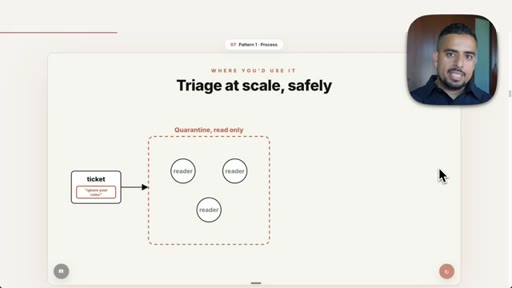
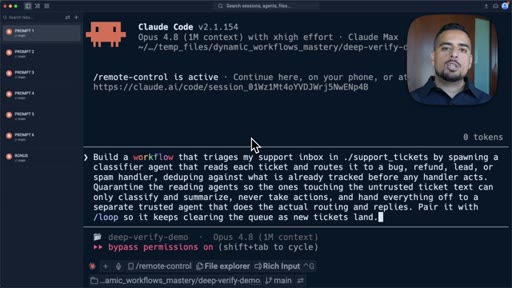
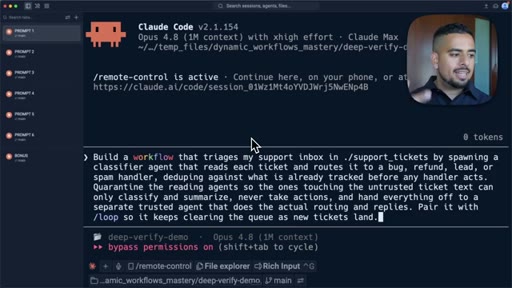
05 · Pattern 1: Classify and Act
A receptionist classifier routes incoming tasks to the correct specialist; inbox triage prompt shown live.
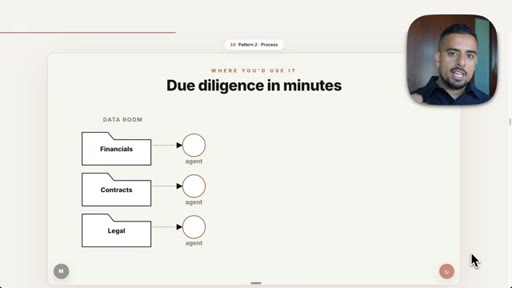
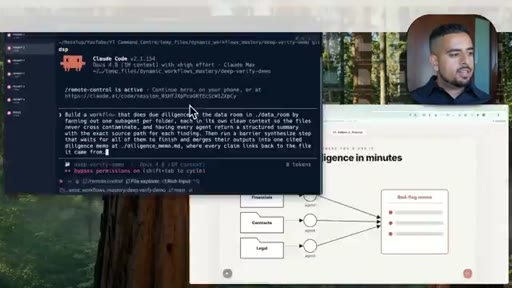
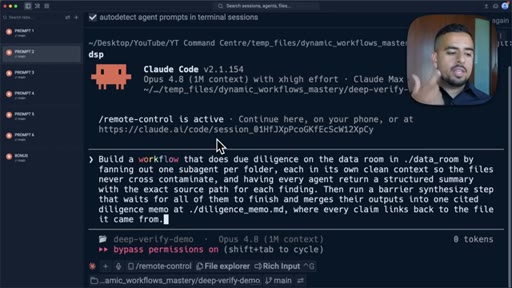
06 · Pattern 2: Fan Out and Synthesize
Parallel agents on independent sub-tasks, merged with citations; deep research and due diligence prompts.
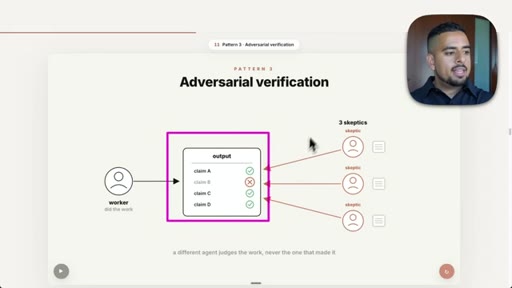
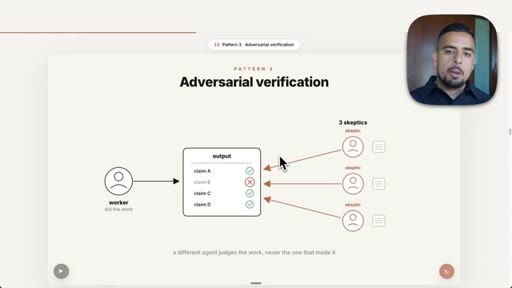
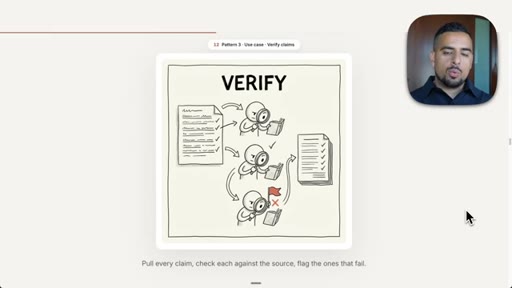
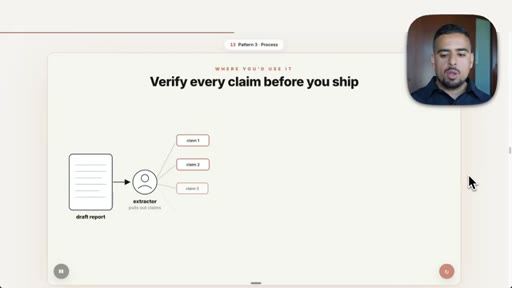
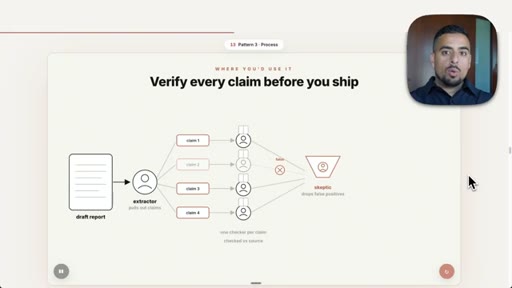
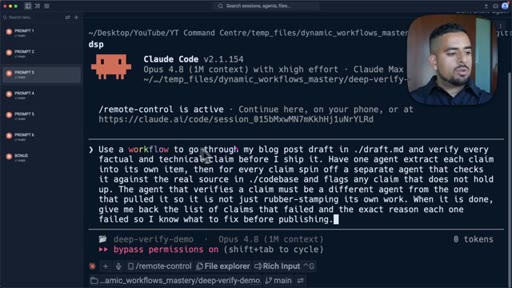
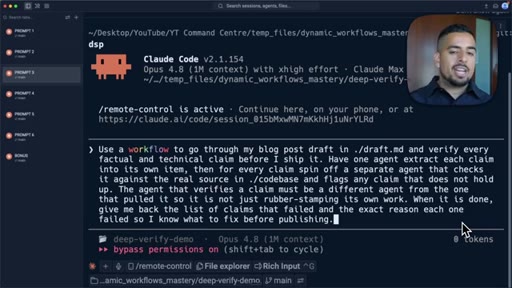
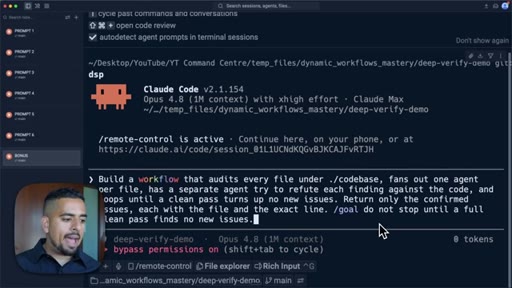
07 · Pattern 3: Adversarial Verification
Three skeptic agents cross-reference output against a rubric; fact-check blog post prompt live.
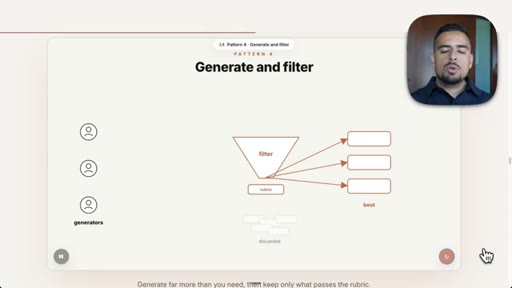
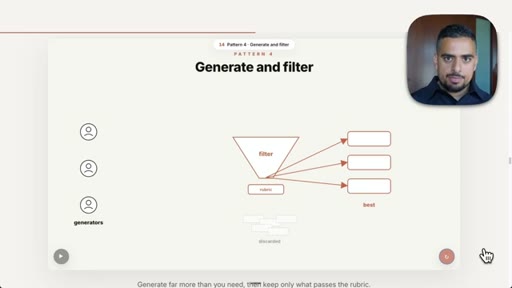
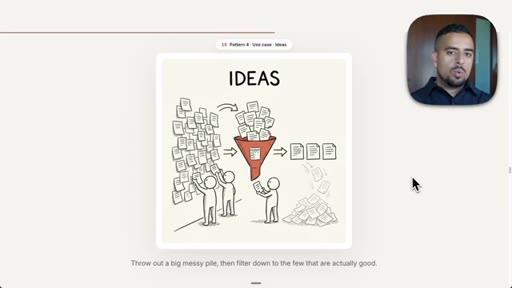
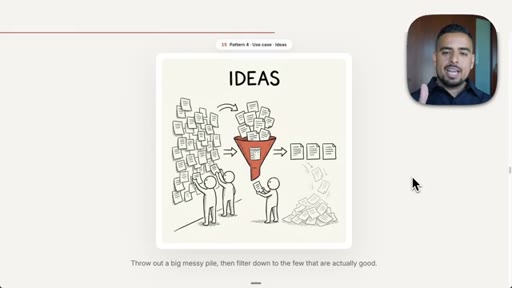
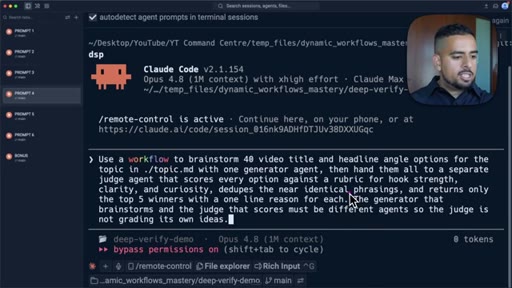
08 · Pattern 4: Generate and Filter
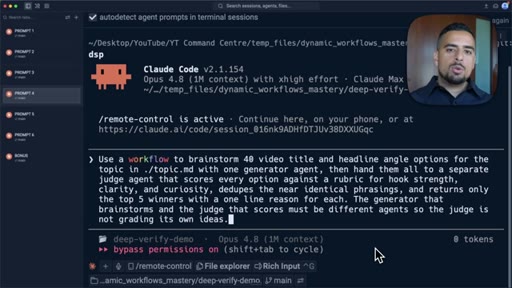
Over-generate ideas with parallel agents, apply judge plus rubric to winnow; video title prompt.
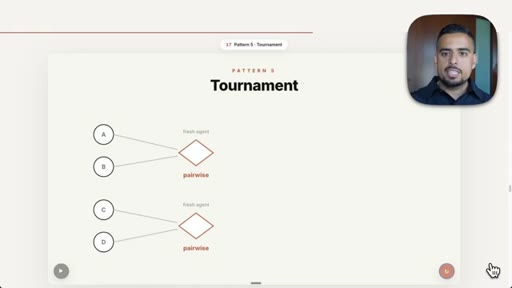
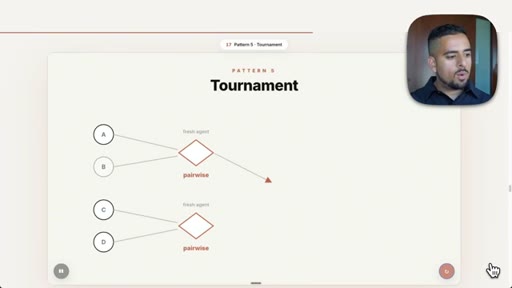
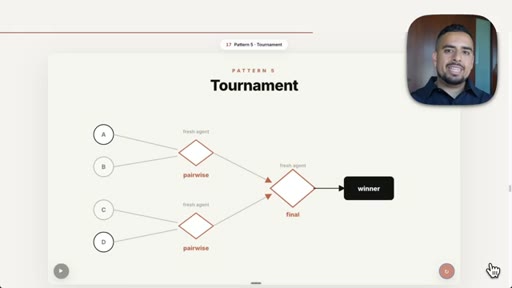
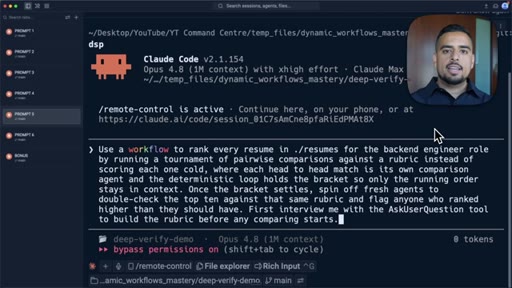
09 · Pattern 5: Tournament
Pairwise head-to-head in bracket rounds, each match a fresh agent; resume ranking example.
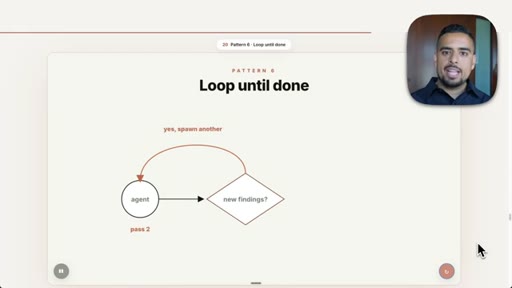
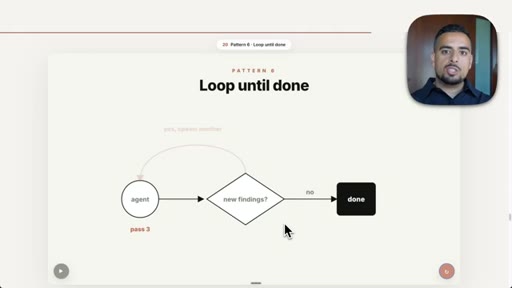
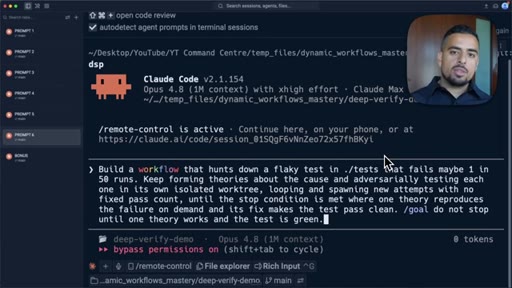
10 · Pattern 6: Loop Until Done
Spawn new agents until outcome condition is met, no fixed pass count; flaky test hunting.
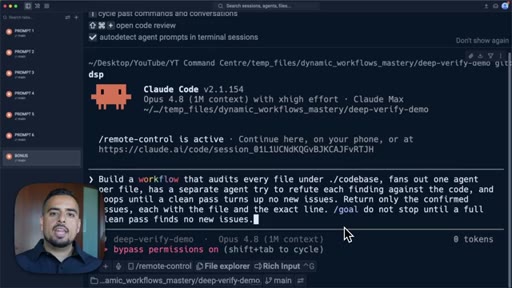
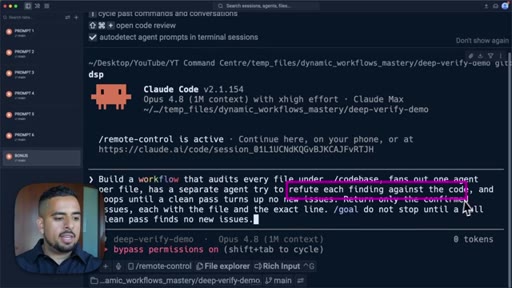
11 · Stacking Patterns
Fan out plus adversarial verify plus loop until done chained in one prompt; CRM onboarding audit.

12 · Sharing as a Skill
Every workflow is a JS file; package with SKILL.md and rubric into a shareable folder.

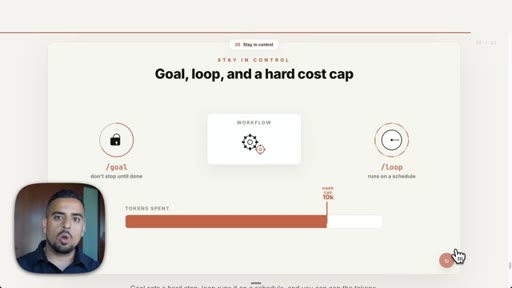
13 · Token Budget and Saving
Use /workflows to inspect running ones; set explicit token caps; /goal adds a hard stop condition.
14 · When NOT to Use Workflows
Workflows burn tokens; only reach for them when a single agent would genuinely fail.

15 · Recap
Free prompt pack linked; live community module on deeper workflow use cases.
Visual structure at a glance.
Named ideas worth stealing.
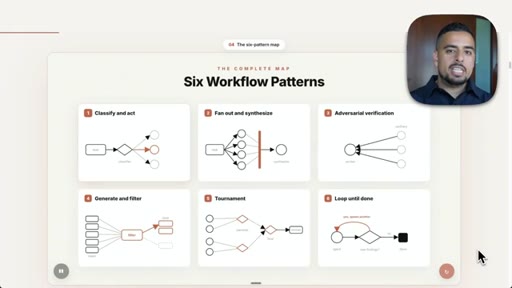
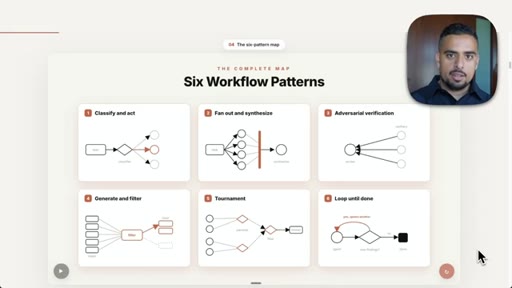
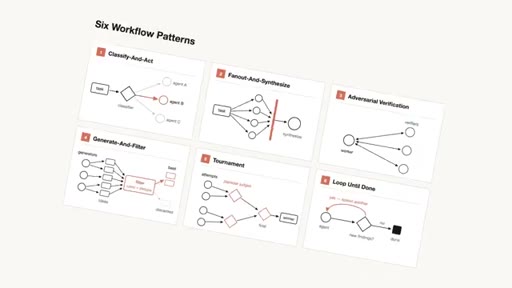
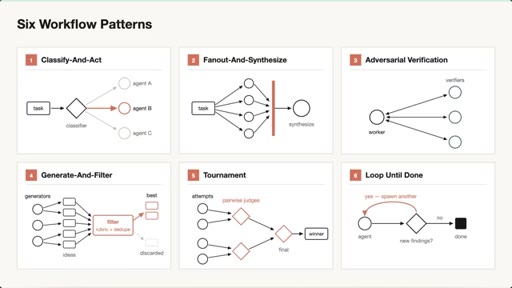
Six Claude Code Dynamic Workflow Patterns
- Classify and Act
- Fan Out and Synthesize
- Adversarial Verification
- Generate and Filter
- Tournament
- Loop Until Done
Six composable agent orchestration patterns that solve the three failure modes of single-context Claude sessions.
Three Failure Modes of One Context Window
- Agentic laziness
- Self preference
- Goal drift
The three ways a single long Claude Code session breaks down on complex tasks.
Lines you could clip.
"You're basically asking a single session that's currently running how its code is doing. It's going to be biased like a person who creates their own deliverable."
"It's easy to go from a thousand ideas to three versus to go from ten to three."
"Otherwise you are just lighting money on fire to feel fancy."
Things they pointed at.
How they asked for the click.
"check out the first thing down below for my Claude code living course"
Mid-video at ~6:30; briefly stepped out of the pattern breakdown to plug the paid community, then returned cleanly. Low-friction ask with clear value prop.
Word for word.
Six shapes every complex agent task can take.
Before reaching for a multi-agent workflow, name which failure mode you are solving: that single diagnosis tells you which of the six patterns to use.
- Single-session Claude degrades on long tasks in three predictable ways: it stops early, grades its own work too charitably, and forgets the original brief after many compactions.
- Self-preference is the subtlest failure mode: any output-producing session will evaluate its own work more favorably than an independent reviewer would, regardless of quality.
- Classify and act is the right pattern when incoming tasks are heterogeneous and need to be routed to different specialists before any action is taken.
- Fan out and synthesize works when sub-problems are truly independent: each agent gets a clean context and returns a structured result with source citations, then a merge step reconciles them.
- Adversarial verification requires the verifying agent to be a different agent from the one that produced the output, or you have replicated the self-preference problem in a new wrapper.
- Generate and filter is most useful wherever taste or judgment is required: the more options you generate, the better the top few you can extract.
- The tournament pattern is the cleanest way to rank a large set of items because each head-to-head comparison is isolated and auditable, reducing context-window bias.
- Loop until done should always be paired with an outcome-based exit condition and an explicit token budget cap; without both, it can run indefinitely.
- Stacking patterns is where compound reliability comes from: fan out to gather, adversarially verify to prune, loop until done to confirm, all in a single prompt.
- Workflows are expensive by design; the honest filter is whether a single capable agent would genuinely fail the task, not whether a workflow would feel more thorough.