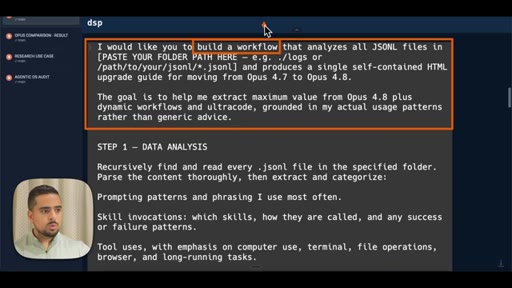
The bait, then the rug-pull.
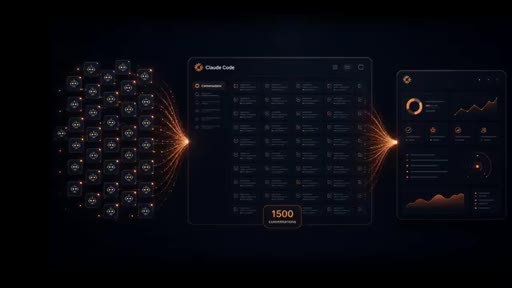
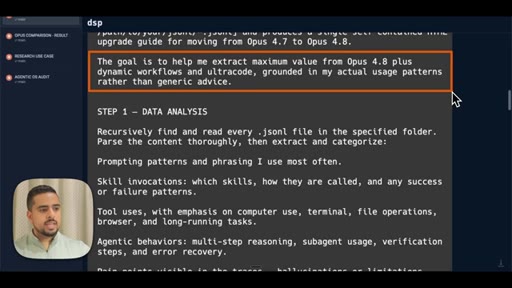
A generated HTML report -- personalized to 1,500 real Claude Code sessions, not pulled from a changelog -- is the opening image. The contrast is immediate: this is what you get when you stop watching other people tutorials and point the model at your own work.
Where the time goes.
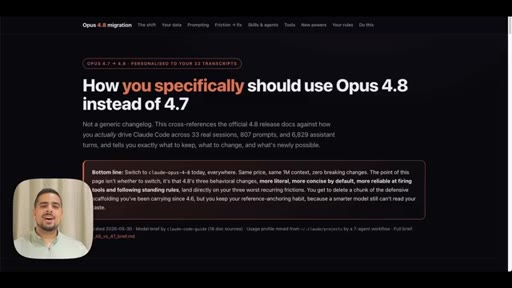
01 · The report it built in an hour
Opens on the live HTML upgrade guide personalized to the host actual session history. Hook is the output, not the process.

02 · The 3 use cases
Promises three workflow patterns, teases the third as most useful, retention hook to end.
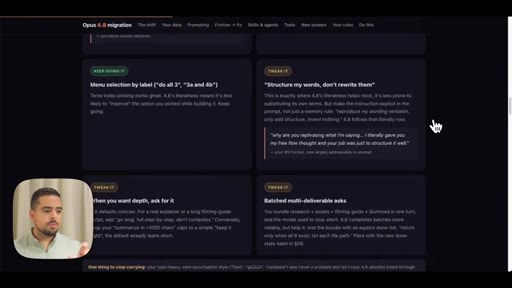
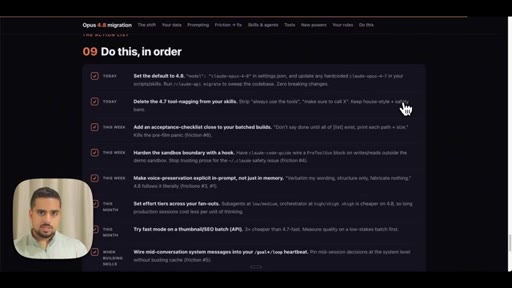
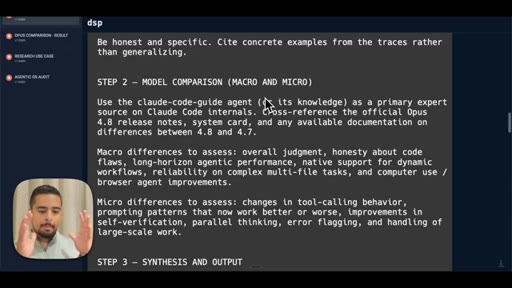
03 · Use case 1: Opus 4.8 upgrade guide
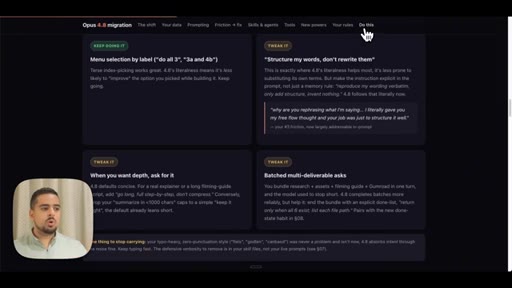
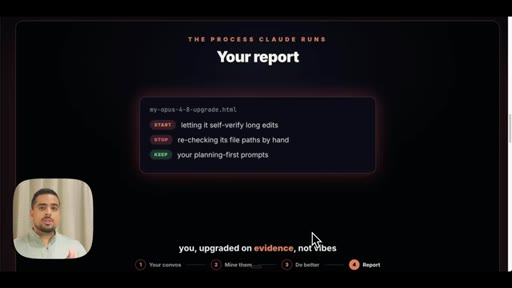
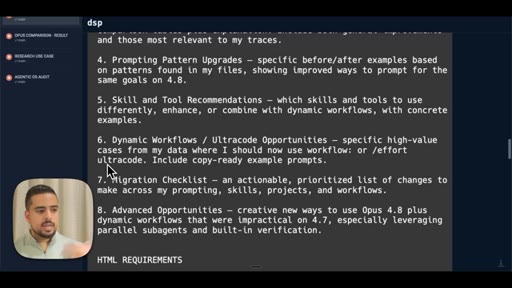
Walks through the report output -- prompting pattern changes, checklist, what stays vs. what shifts.

04 · The model-is-insane trap
Shows a grid of INSANE thumbnail mockups -- the problem the workflow solves. Generate your own tutorial from your own data instead.
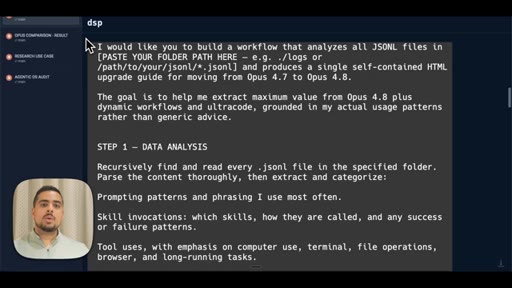
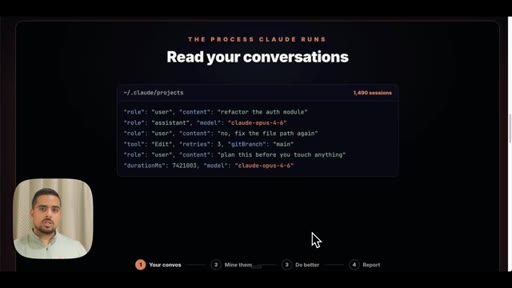
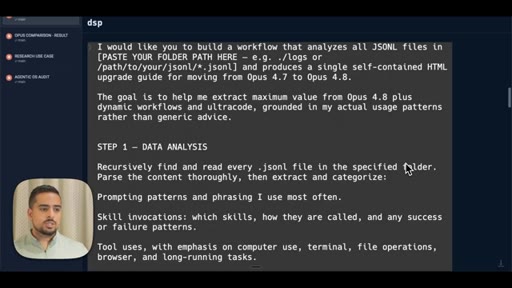
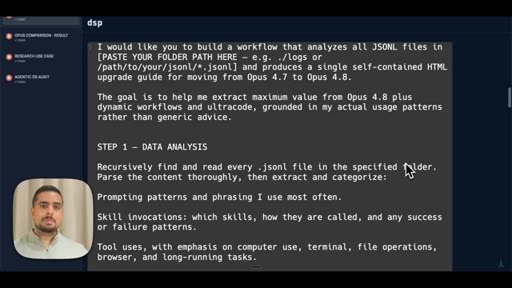
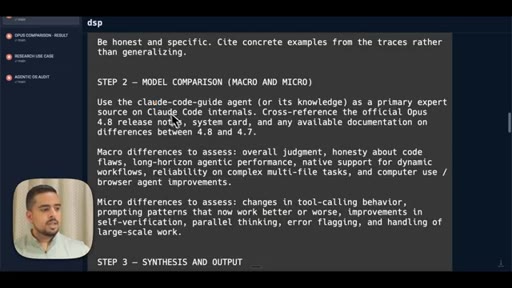
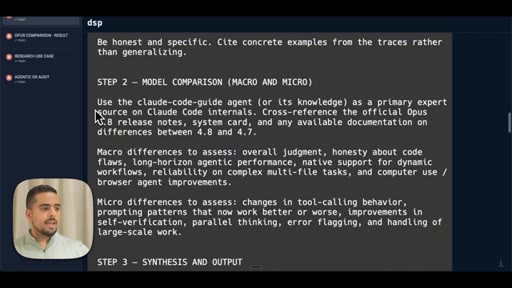
05 · The prompt (JSONL + claude-code-guide)
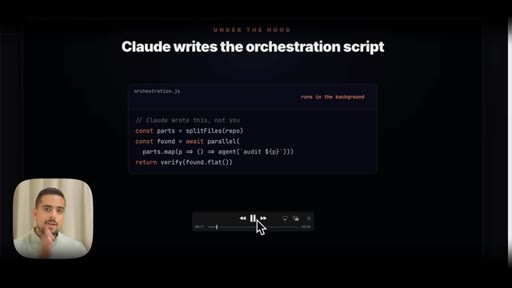
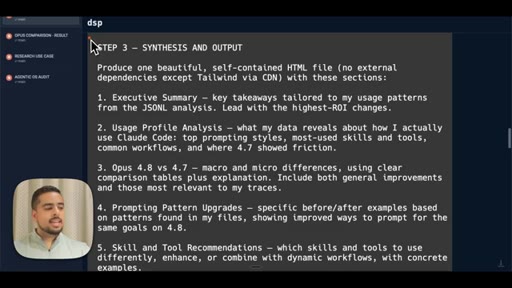
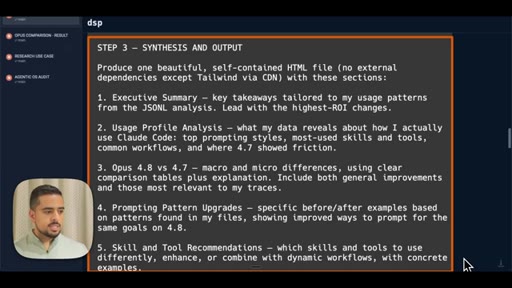
Shows the full 3-step workflow prompt live on screen: data analysis, model comparison via claude-code-guide, synthesis and HTML output.
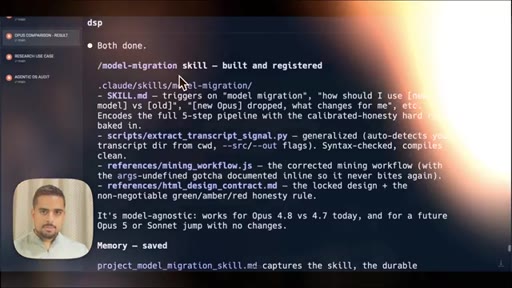
06 · Make a 2-min video + a skill
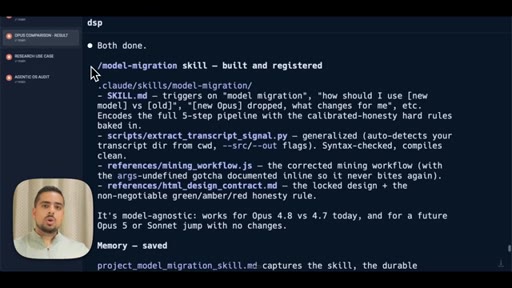
Pipes the HTML report into Hyperframes to auto-generate a tutorial video. Saves the full pipeline as a reusable /model-migration skill.
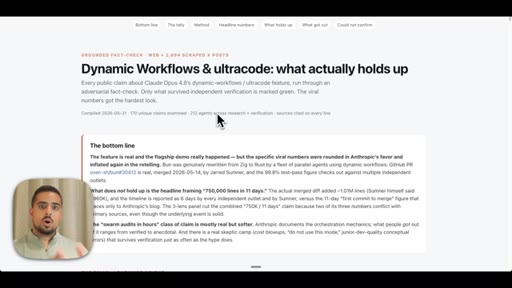
07 · Use case 2: self-checking deep research
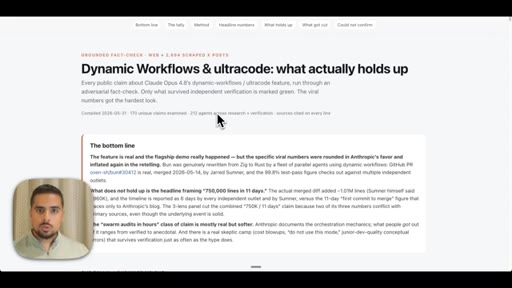
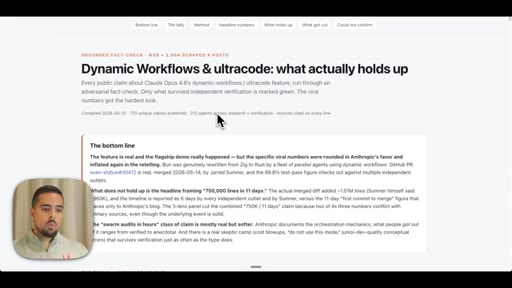
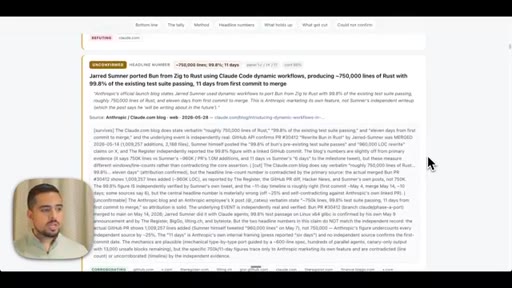
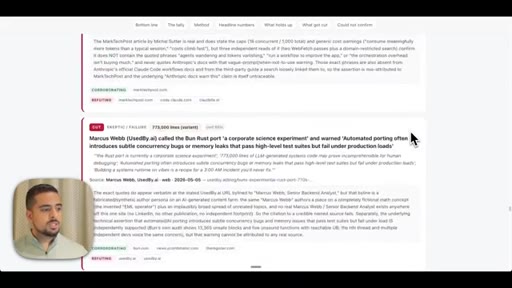
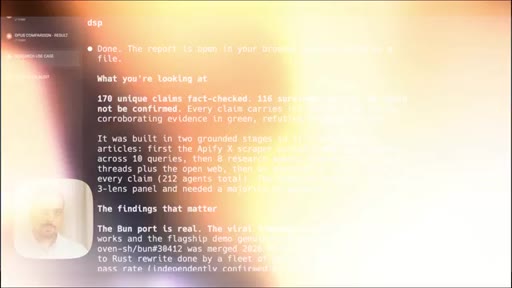
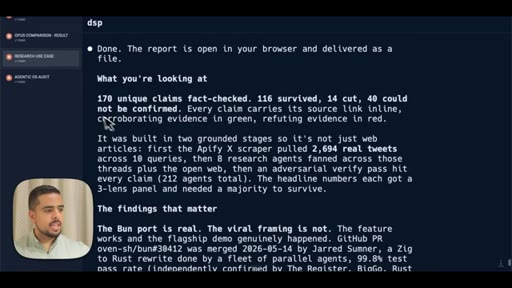
Introduces adversarial verification as the key differentiator over single-agent research. Shows live fact-check report on dynamic workflows claims.
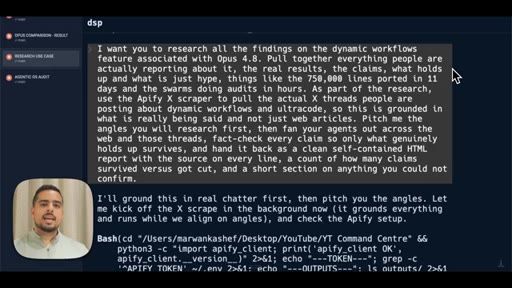
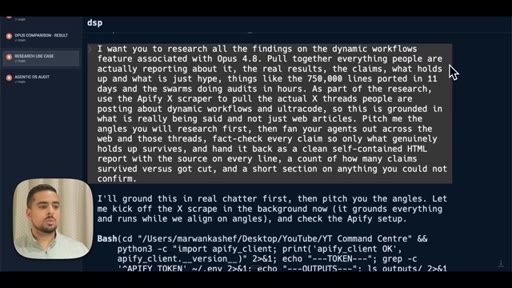
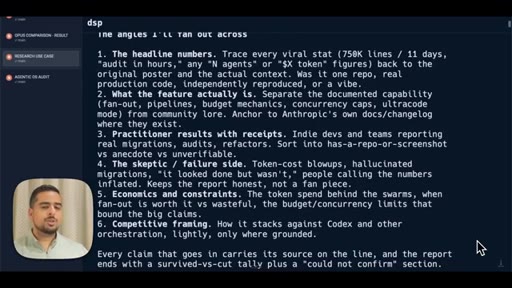
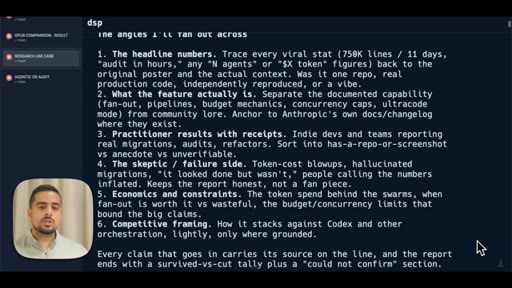
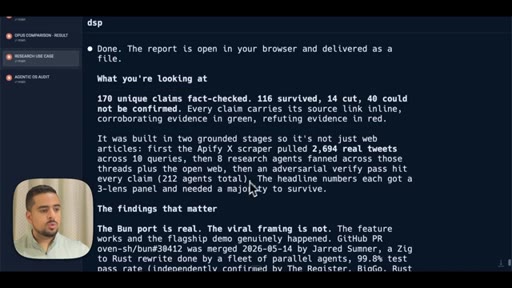
08 · The research prompt (Apify X scraper)
Shows the full research prompt -- Apify setup, angle fan-out, adversarial verify pass, claim-survival scoring.
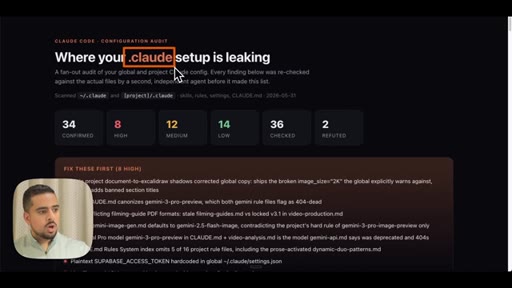
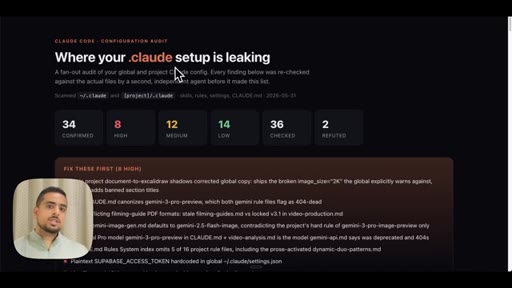
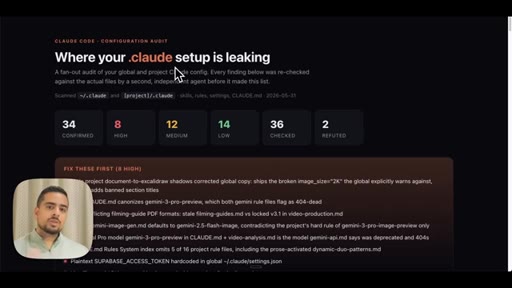
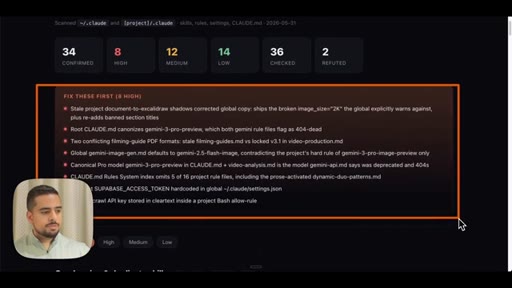
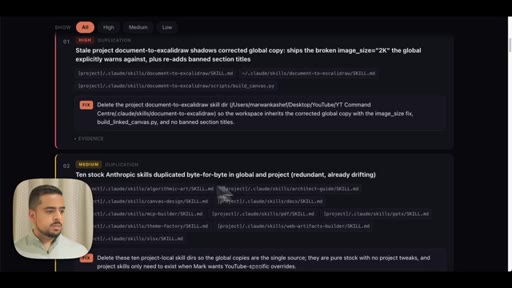
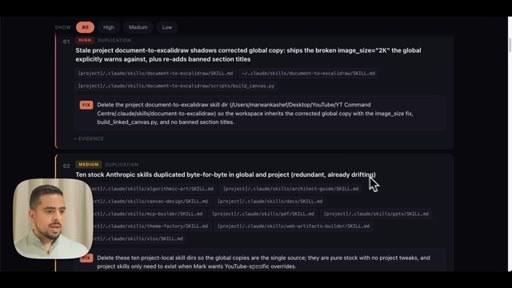
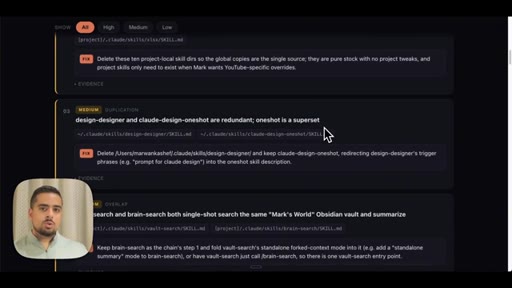
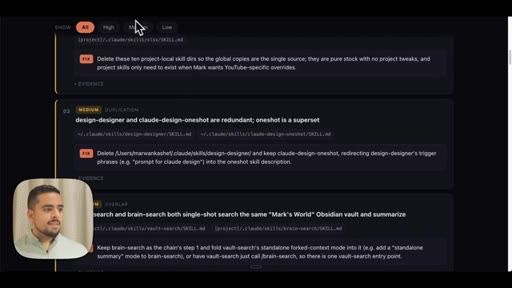
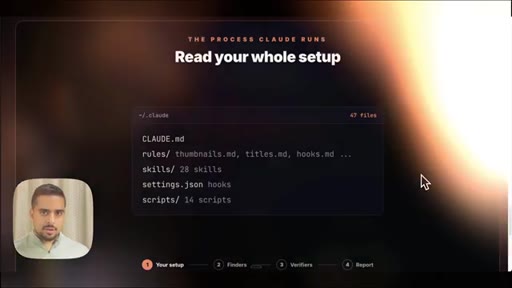
09 · Use case 3: audit your .claude
Fans out agents across global and project .claude folders. Shows live audit report: duplicated skills, contradictory rules, hardcoded API key, stale demo skills.
10 · More uses + grab the prompts
Extends to other domains like travel booking. CTAs for Living Course and free prompts pack.
Visual structure at a glance.

Named ideas worth stealing.
3-Step Dynamic Workflow Prompt Structure
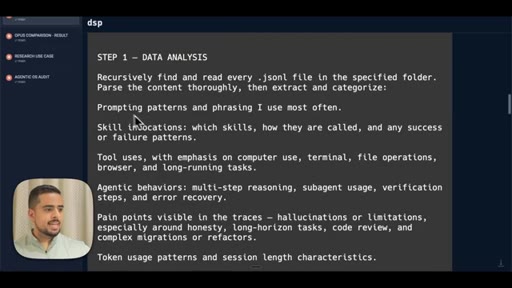
- Step 1 Data Analysis -- recursively read all JSONL files, categorize prompting patterns, skill invocations, tool uses, agentic behaviors
- Step 2 Model Comparison -- use claude-code-guide agent to cross-reference official release notes against your actual usage patterns
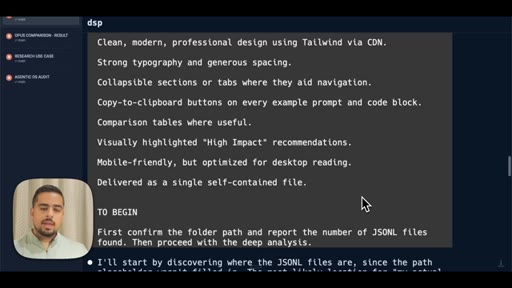
- Step 3 Synthesis and Output -- produce self-contained HTML with executive summary, usage profile, macro/micro differences, prompting upgrades, skill recommendations, migration checklist
The exact 3-step prompt structure for generating a personalized model-migration guide from your own JSONL logs.
Adversarial Verification Pass
- Pull claims from primary sources via X scraper or GitHub
- Fan out research agents across multiple angles simultaneously
- Run a 3-lens verification panel on every claim: primary source / corroborating / refuting
- Require majority vote to survive; tag SURVIVED, CUT, or COULD NOT CONFIRM
- Every surviving claim carries an inline source link
The pattern for turning a fast research answer into a verified one by having a second wave of agents argue against the first.
Ecosystem Audit Severity Tiers
- HIGH -- Duplicate skills, hardcoded secrets, stale banned-section titles
- MEDIUM -- Overlapping skills that are supersets of each other, conflicting model defaults across CLAUDE.md files
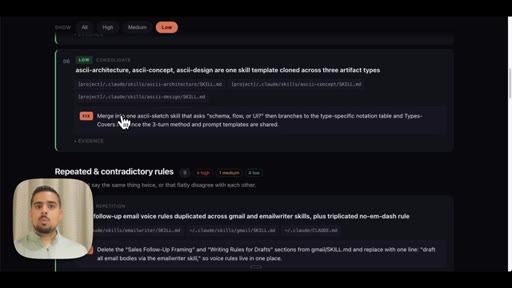
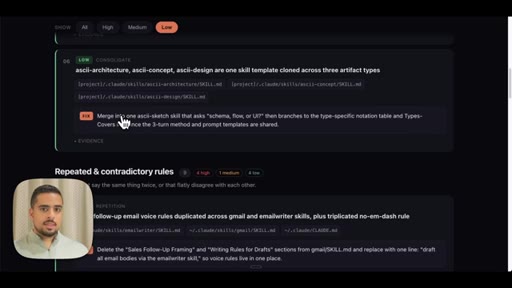
- LOW -- ASCII-split skills that should be one template, follow-up rules duplicated across skill files
Three-tier severity classification for .claude cleanup actions.
Lines you could clip.
"You upgraded on evidence, not vibes."
"There is no devil advocate outside of that one running session."
"The Bun port is real. The viral framing is not."
"There are only a handful of tasks that really deserve the level of token burn that you get by spinning up all these agents."
Things they pointed at.
How they asked for the click.
"If you want access to exclusive skills just like this one, along with all the exclusive content that we keep adding to our Claude Code Living course, then check out the first link down below."
Mid-roll placement before use case 2, at the natural break after the model-migration skill demo. Aggressive but timed to a high-value moment. Secondary CTA at 11:25 for free prompts pack.
Word for word.
Verification is the workflow, not a step.
A second wave of agents that argues against the first is what earns the token cost of multi-agent workflows -- and it applies to research, model migrations, and your own tool setup alike.
- Your Claude Code JSONL files are a complete record of how you actually prompt -- mining them gives you a model-transition guide calibrated to your patterns, not a generic changelog.
- Single-agent research cannot fact-check itself; there is no internal devil advocate, so confident-sounding outputs are still unverified until a second agent explicitly tries to refute them.
- Adversarial verification is a structural choice, not a prompt tweak -- it requires a separate verification pass with access to primary sources, not just asking the first agent to double-check.
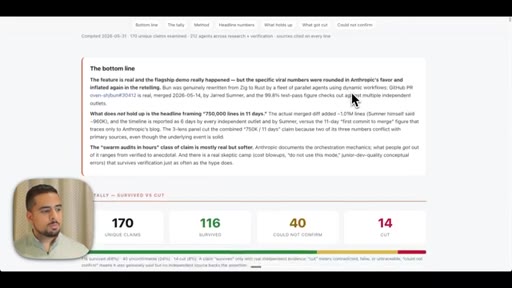
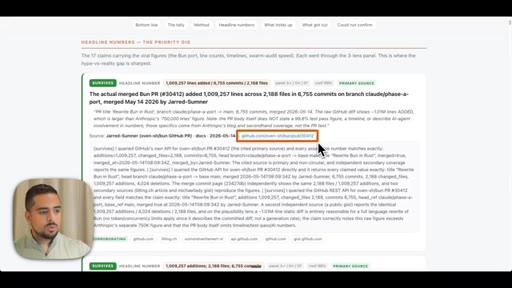
- Of 170 X claims about dynamic workflows examined adversarially, 116 survived and 14 were cut -- the viral framing of real events is frequently inflated even when the underlying feature is genuine.
- A Claude Code setup that has grown organically for months reliably contains duplicate skills, contradictory rules, and at least one hardcoded secret; an audit workflow surfaces these faster than manual review.
- Reusable skills are the compounding return on agentic work -- saving a completed workflow as a skill means the next model drop, research question, or audit costs one command instead of rebuilding from scratch.
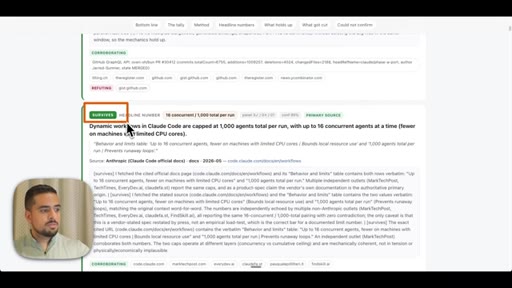
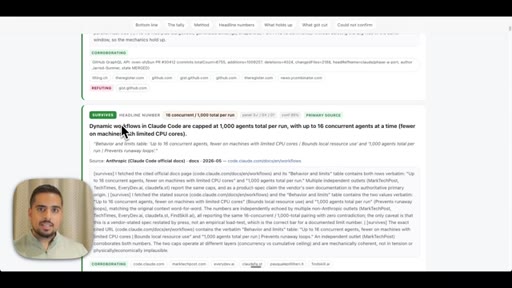
- Token burn from multi-agent workflows can be negotiated interactively -- Claude will ask how deep to go, and scoping down from 70 agents to 20 before the run starts is a legitimate cost-control strategy.
- The value ceiling of dynamic workflows is set by task type, not ambition -- they suit large, messy, multi-source problems that need validation; they are wasteful for tasks a single sharp prompt handles.