The bait, then the rug-pull.
A thousand agents, zero API bill. The Claude Desktop app ships a gateway mode that routes all inference to a local LM Studio server -- and the only non-obvious step is a model-renaming trick that takes thirty seconds.
Where the time goes.
01 · Hook + gateway overview
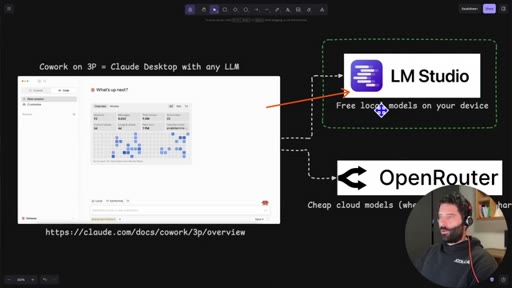
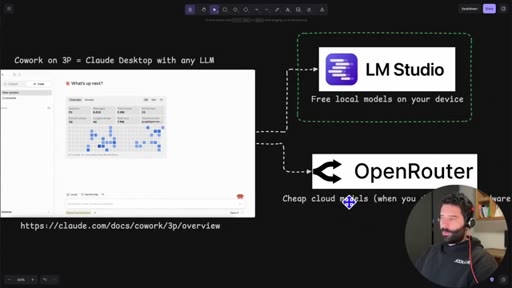
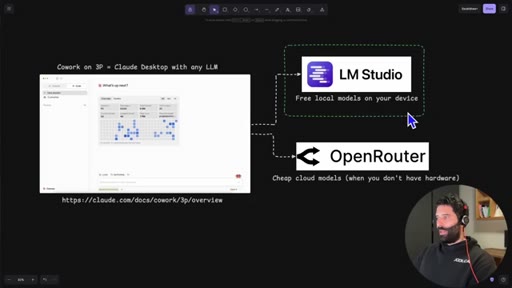
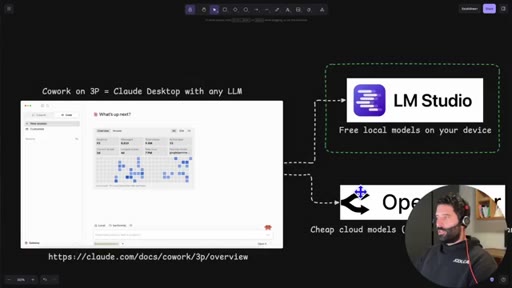
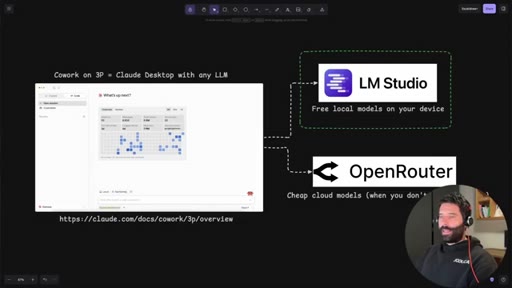
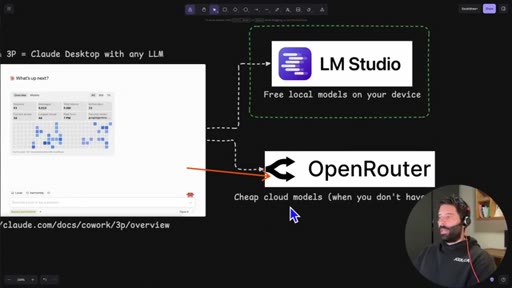
Introduces Claude Dynamic Workflows, names the two backend options (LM Studio local, OpenRouter cloud), and frames the cost angle.
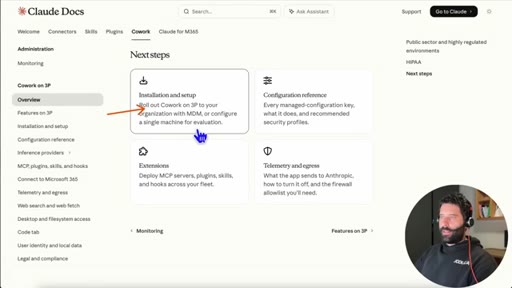
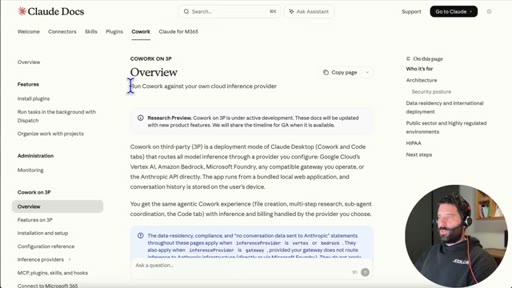
02 · Claude docs: Cowork on 3P
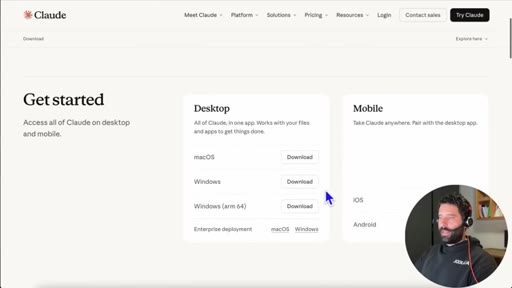
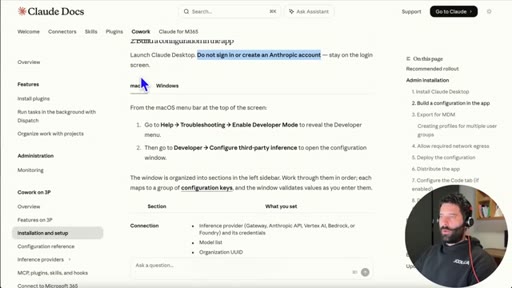
Walks through official setup guide. Step 1: download Claude Desktop. Step 2: do not sign in with an Anthropic account.
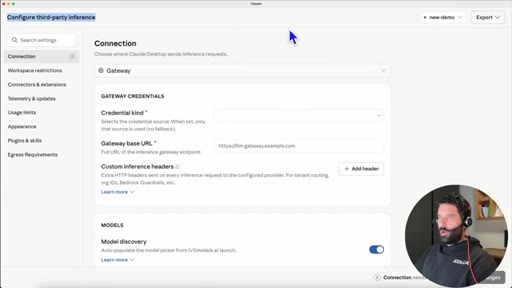
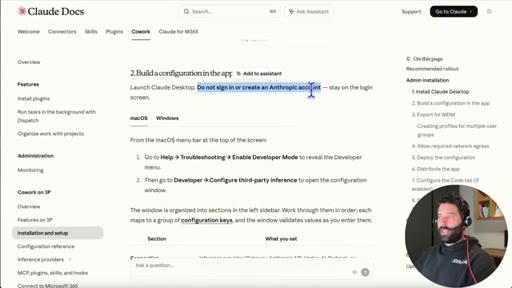
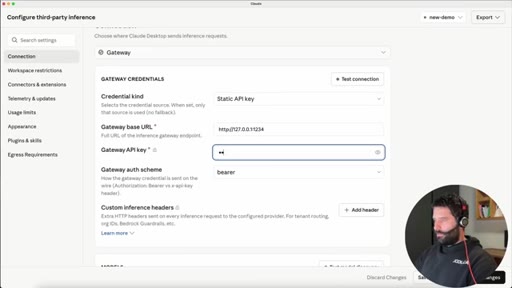
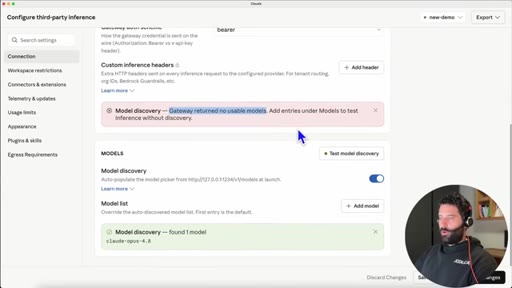
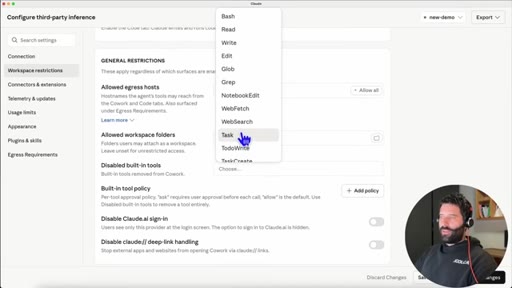
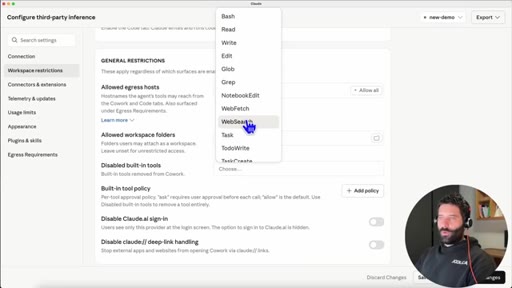
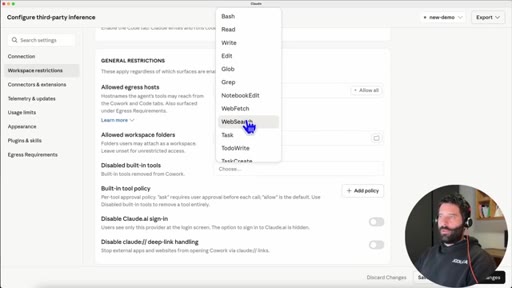
03 · Configure third-party inference
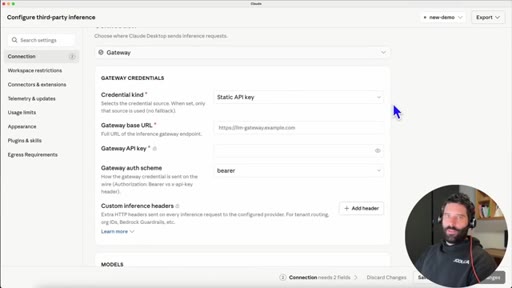
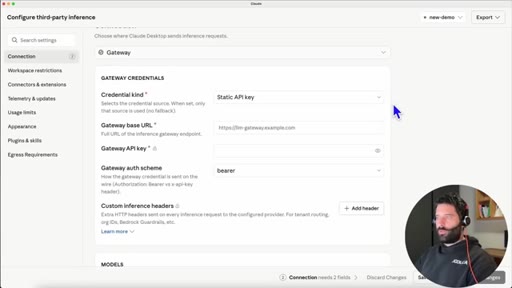
In Claude Desktop settings: set connection type to gateway, credential kind to static API key.
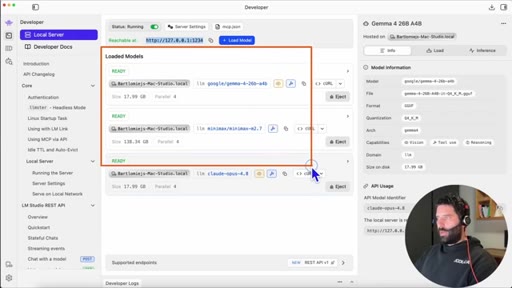
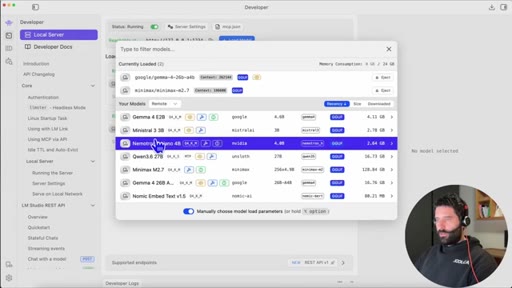
04 · LM Studio overview
Download, model search interface, GPU compatibility green-tick indicator, three setup steps.
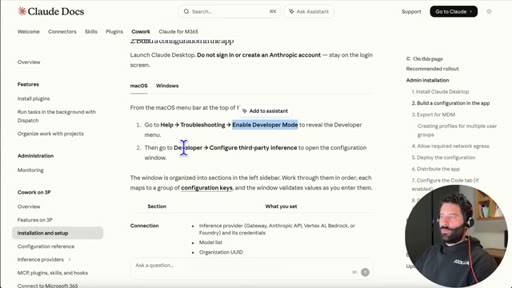
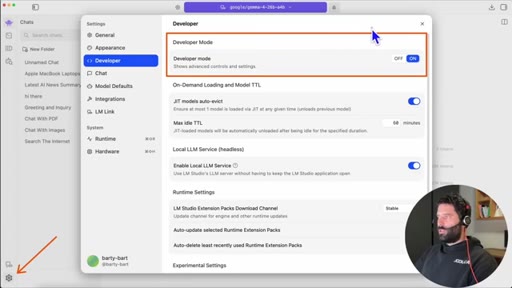
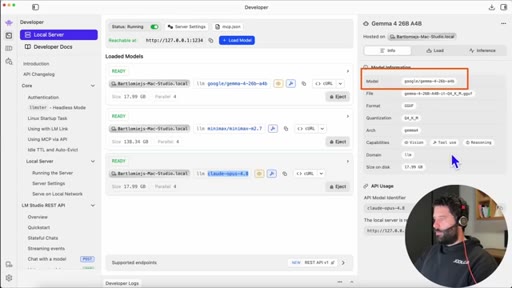
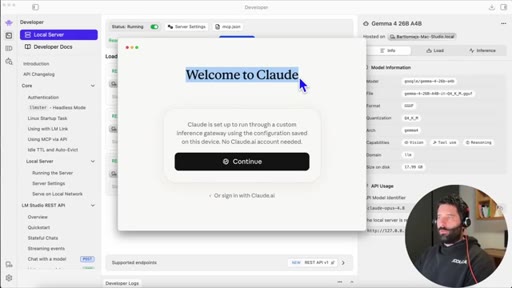
05 · Developer mode + gateway URL
Enable developer mode in LM Studio, open Developer tab, copy local server URL, paste into Claude gateway base URL field.
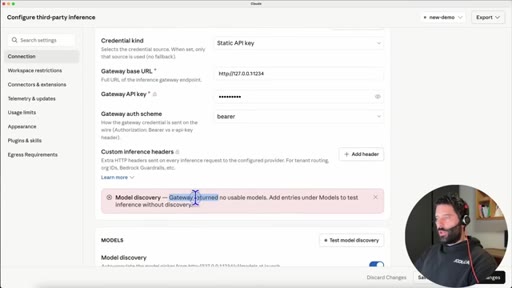
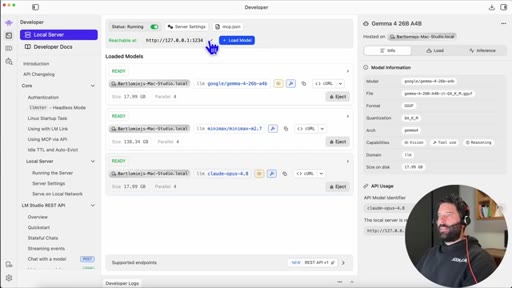
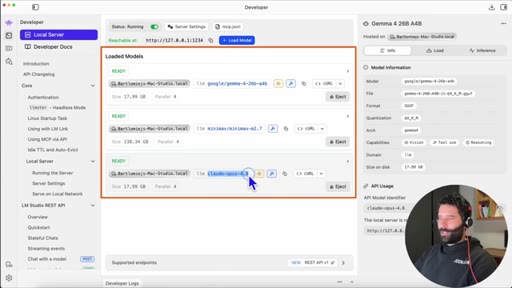
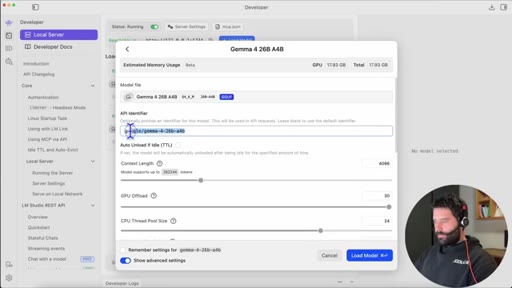
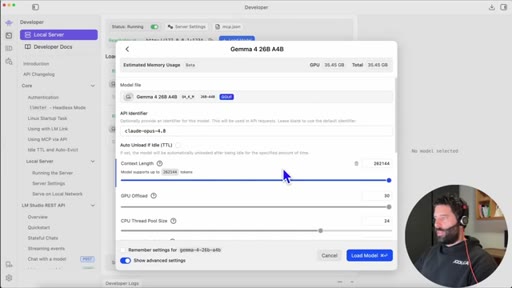
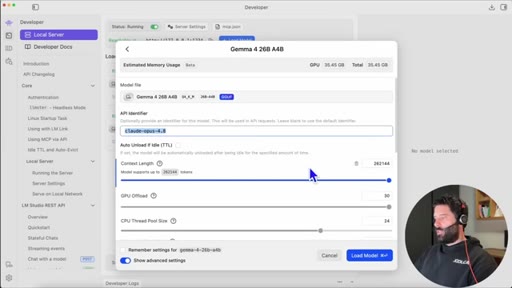
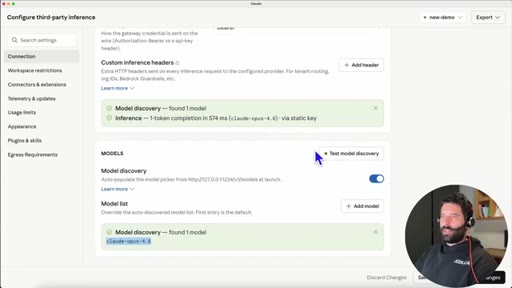
06 · The model-alias trick
Claude rejects models not named Sonnet/Opus/Haiku. Fix: rename the model API identifier to claude-opus-4.8 in LM Studio load settings.
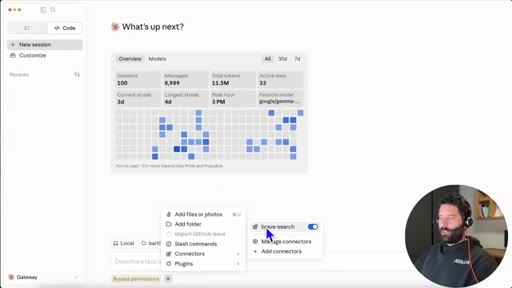
07 · Disable built-in tools + BraveSearch MCP
Local models lack built-in web search. Toggle disables native tools so Claude looks for MCP connections.
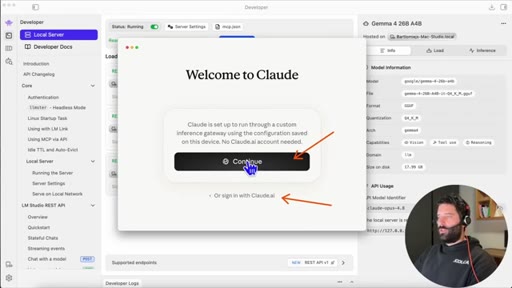
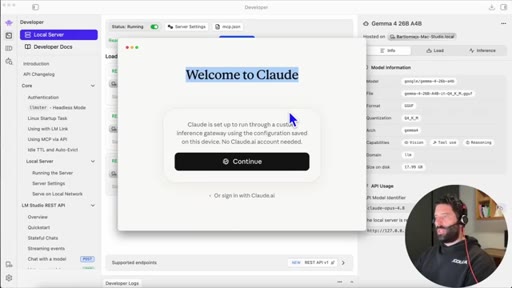
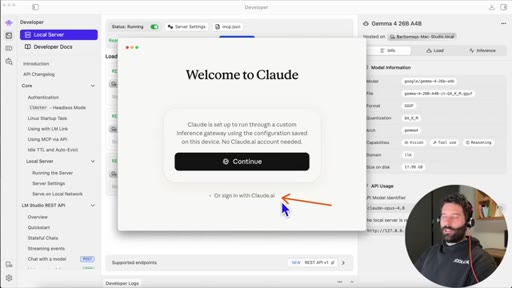
08 · Sign-in flow
If already signed in to Claude, sign out first to see the gateway login screen. Continue without account.
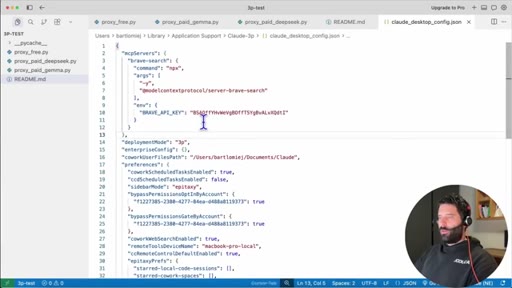
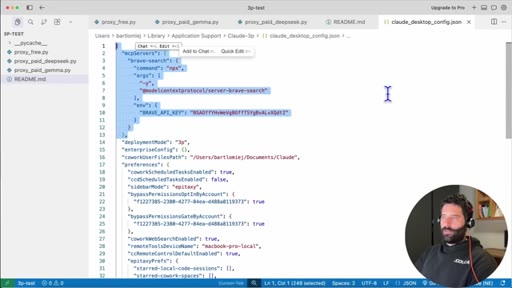
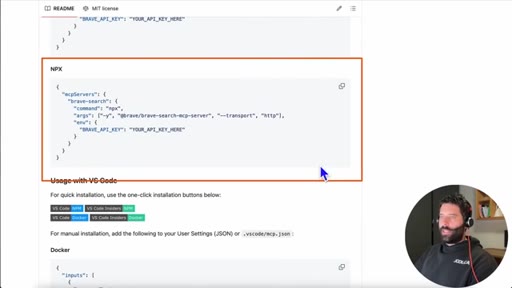
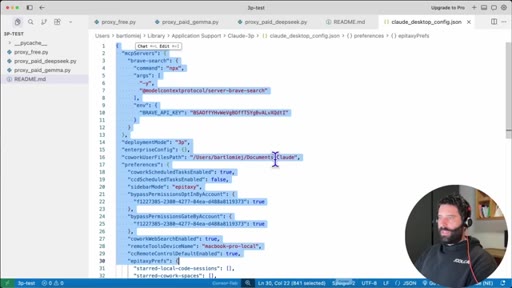
09 · Adding MCP via config file
Copy NPX install snippet from BraveSearch docs, use Claude to merge it into existing claude_desktop_config.json.
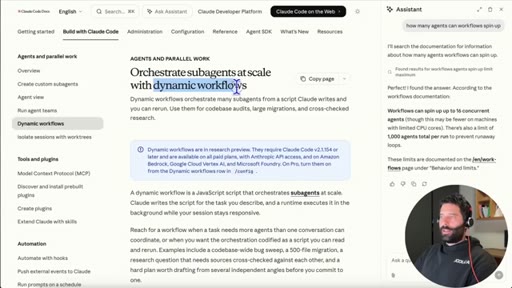
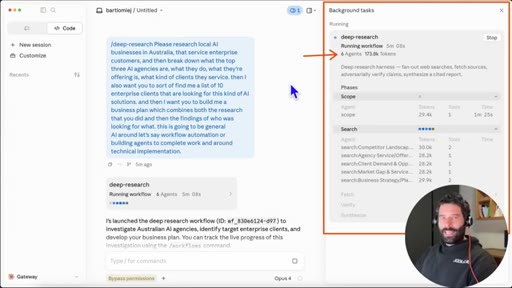
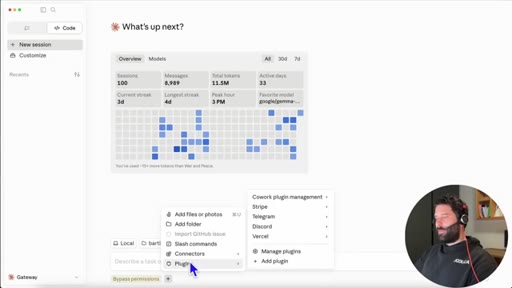
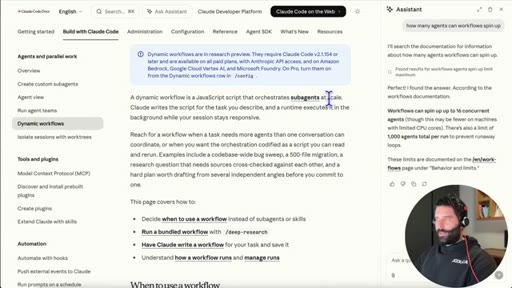
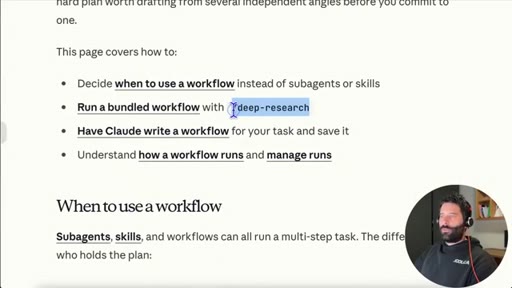
10 · Dynamic Workflows explained
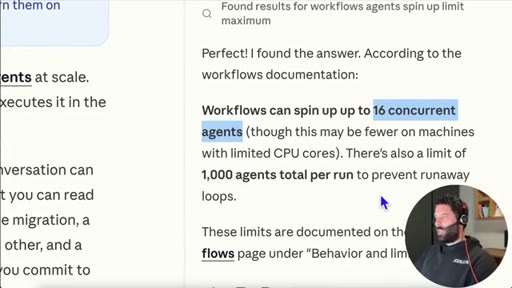
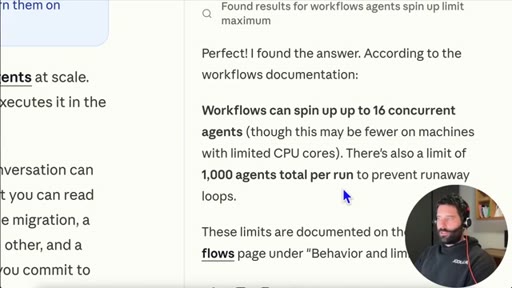
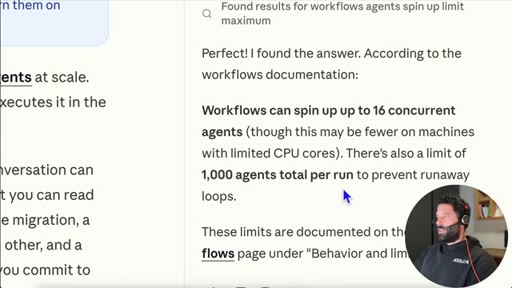
16 concurrent agents, 1,000 total per run. /deep-research is a bundled slash command. Live business-plan demo.
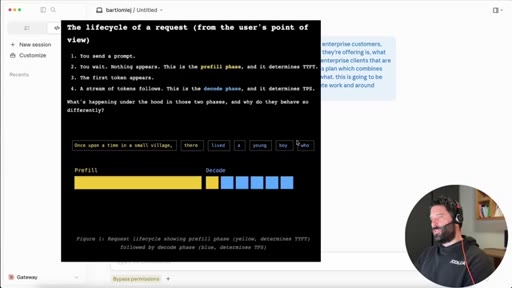
11 · Live demo + prefill/decode explainer
Agents running in real time on Gemma 26B. Explains why first message is slow (30K tokens). Suggests leaving the computer for 1-2 hours.
Visual structure at a glance.
Named ideas worth stealing.
Prefill vs. Decode
- Prefill (TTFT -- prompt ingestion speed)
- Decode (TPS -- token generation speed)
Two phases of local LLM inference. Prefill determines time to first token; decode determines generation speed. Local hardware bottlenecks at prefill for large contexts.
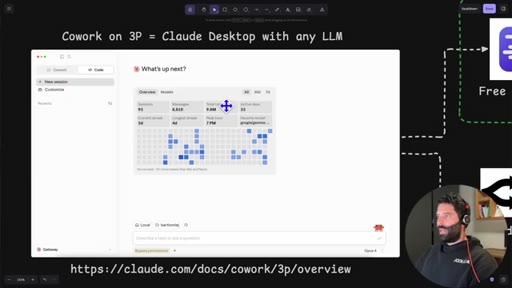
Cowork on 3P
Anthropic term for running Claude Desktop against a third-party inference provider, enabling any OpenAI-compatible endpoint as a drop-in replacement.
Lines you could clip.
"Instead of us using the paid API from Anthropic or even needing an Anthropic account, I'm gonna show you how to do this by using local AI models that are running completely on your computer."
"The gateway returned no usable models -- Claude is only looking for things that have Sona or Opus or Haiku."
"A dynamic workflow is a JavaScript that lets you basically deploy hundreds of sub agents."
"From the very first message, we're sending like 30,000 tokens. It's a lot. But then from here, you can literally just leave your computer."
Things they pointed at.
How they asked for the click.
"If you enjoyed it, I would appreciate if you could like the video, drop a comment, or subscribe to my channel."
Standard subscribe ask after content wraps. Also seeds a follow-up video on OpenRouter integration.
Word for word.
How to run Claude agents without an Anthropic bill.
Claude Desktop gateway mode is an official feature that lets you substitute any local model for the Anthropic API, and one naming convention is the only non-obvious requirement.
- Claude Desktop model-discovery filter only accepts model IDs containing Sonnet, Opus, or Haiku -- renaming your local model to match this pattern before loading it is the single step most tutorials skip.
- Dynamic Workflows are capped at 16 concurrent agents and 1,000 total per run, which is more than enough for most research, analysis, and code-generation tasks running locally.
- The /deep-research slash command is already bundled into Claude Code -- there is no scripting required to access multi-agent behavior, just type the command.
- Local model latency is front-loaded: the first response in a Claude Code session is the slowest because the system context runs around 30,000 tokens, and prefill speed is where local hardware trails hosted inference most noticeably.
- BraveSearch and other web-search providers require their own API keys even when connected through an MCP -- the MCP provides the interface but not the credential.
- OpenRouter is a drop-in alternative to LM Studio in this same setup and gives access to hundreds of cloud models including free tiers and paid options at a significant discount over direct API pricing.