The bait, then the rug-pull.
Benchmarks always look amazing on launch day. The real question is whether the model actually fixes the things that were breaking your workflow — and for Opus 4.8, the answer turns out to depend almost entirely on a slider you probably never touched.
Where the time goes.
01 · Intro
Promise: same-day breakdown of benchmarks, 4.7 pain points, and key takeaways.
02 · What's New in 4.8
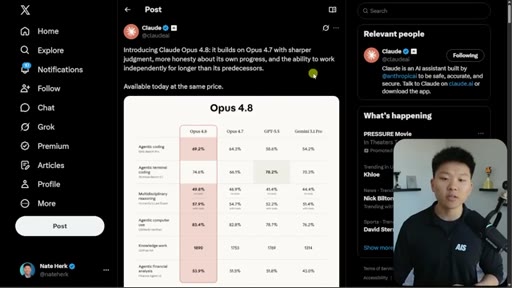
Blog post walkthrough: effort control, dynamic workflows, same pricing as 4.7, API rate limit increases.

03 · Effort Levels and Workflows
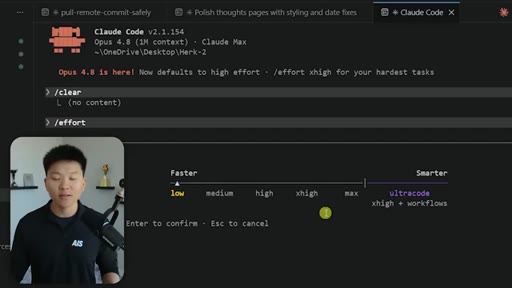
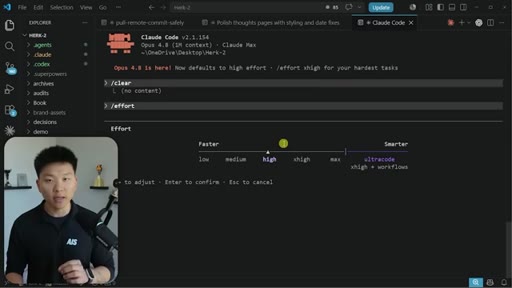
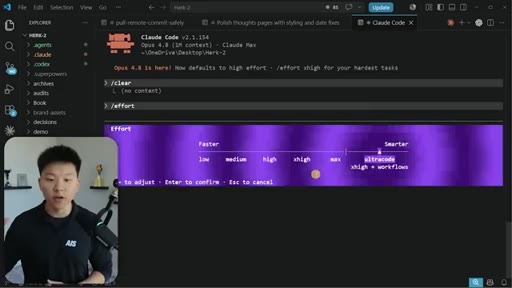
Live demo of /effort slider in Claude Code CLI: low, medium, high, xhigh, max, ultracode. Ultracode = xhigh + dynamic workflows.

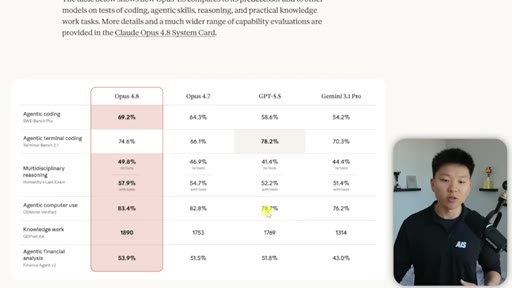
04 · Benchmarks Reality Check
Benchmarks always look great at launch. Codex with GPT-5.5 may outperform Opus on computer use despite worse paper numbers.

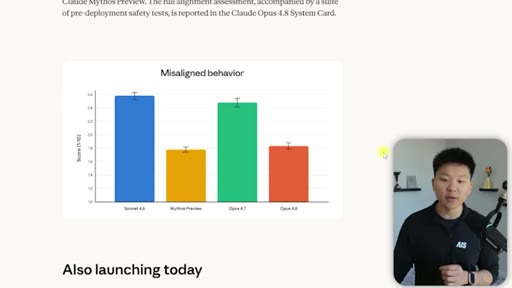
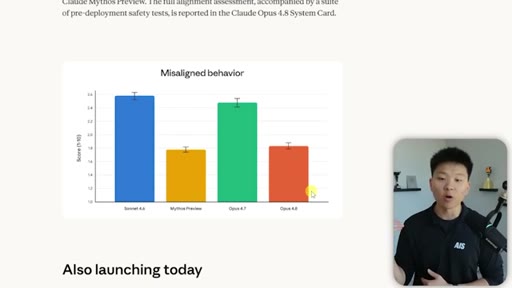
05 · The Honesty Upgrade
Opus 4.8 is ~4x less likely to falsely claim task completion. Alignment evaluation data shown. Mythos preview teased.

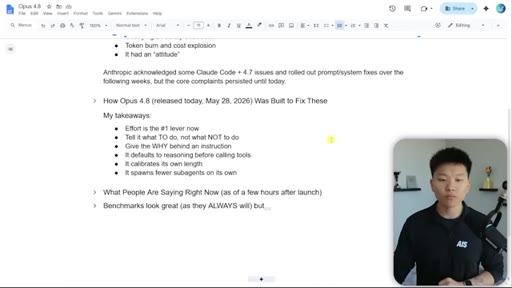
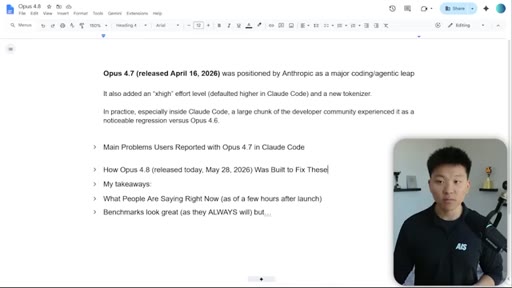
06 · 4.7 Pain Points
Community-reported 4.7 problems: lazy/early quitting, safety overreach, token explosion, attitude. Anthropic acknowledged and rolled partial fixes but core complaints persisted until 4.8.
07 · Key Takeaways
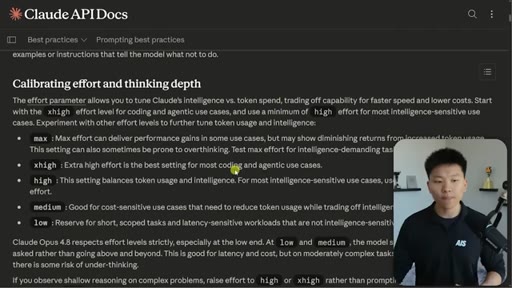
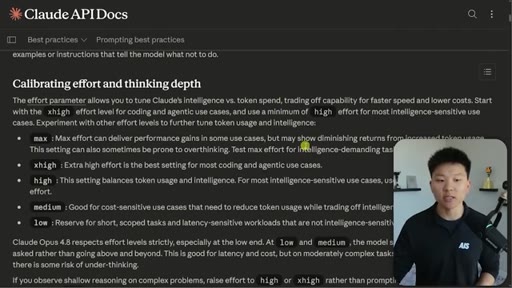
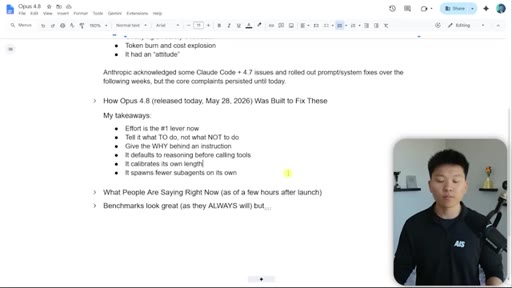
Five adjustments from Anthropic docs: effort is the primary lever, positive instructions, give the why, reasoning-before-tools default, self-calibrated response length.
08 · Community Reactions
Launch-hour social takes. Positive: one-shotted GPT-5.5, warm and collaborative. Cautious: early bugs, real-world data still thin.
09 · Final Thoughts
Evaluate 4.8 against your specific 4.7 frustrations, not the benchmarks. Watch for vibe upgrade, self-correction frequency, token efficiency. Plug for free token dashboard.
Visual structure at a glance.
Named ideas worth stealing.
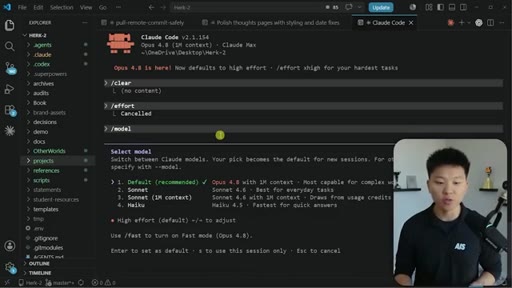
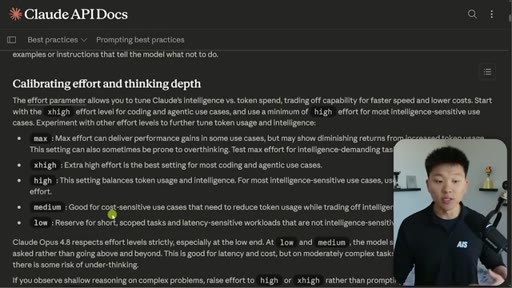
Effort Tiers
- low
- medium
- high
- xhigh
- max
- ultracode
Six-tier effort parameter controlling Claude Code compute, reasoning depth, and token spend. Ultracode combines xhigh with dynamic workflows.
4.7 Problem to 4.8 Fix Map
- Laziness → Sustained autonomy
- Safety overreach → Warmer vibe
- Token burn → Token efficiency
- Hallucinated completion → Honesty (4x)
- Attitude → Collaborative
Direct mapping of the five most-cited 4.7 community complaints to the explicit 4.8 training improvements.
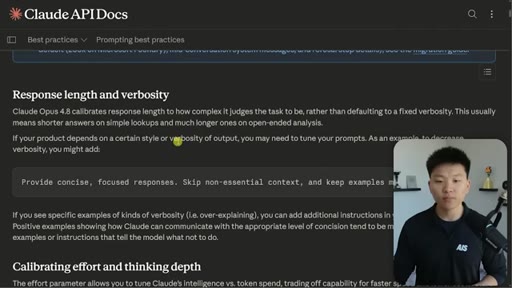
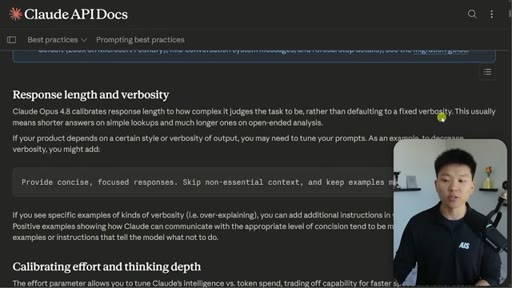
Five Prompting Adjustments for Opus 4.8
- Match effort level to task complexity
- Tell it what to do, not what not to do
- Give the why behind every instruction
- Account for reasoning-before-tools default
- Let it self-calibrate response length
Five behavioral shifts derived from Anthropic's own prompting best practices doc, applied specifically to Opus 4.8.
Lines you could clip.
"The difference between Opus 4.8 on low and Opus 4.8 on extra high is a significant difference, like almost to the point where it feels like a different version."
"Benchmarks look great, and they always will. Someone else's use case is not your use case."
"There is a big difference here between the model having problems and you using the model wrong. Sometimes it truly is a skills problem."
Things they pointed at.
How they asked for the click.
"I will leave that in my free school community linked in the description. Just give Claude Code the GitHub repo, tell it to set it up."
Soft free tool mention at the end. No price, no hard pitch. Feels like a utility recommendation.
Word for word.
Effort level is the dial most Claude Code users never touch.
Opus 4.8 ships with six effort tiers that behave differently enough to feel like different models — and most of the frustration attributed to 4.7 was effort misconfiguration as much as model limitation.
- Running max effort on a simple task causes overengineering; running high effort on a complex autonomous task triggers early quitting — the mismatch, not the model, is usually the problem.
- Positive framing outperforms negative constraints: telling the model what style to match lands better than listing what to avoid, because the model can reason about intent.
- Giving the why behind an instruction is not optional polish — it is how the model calibrates compliance when an instruction conflicts with its defaults.
- Opus 4.8 reasons before calling tools by default; if your workflow needs external context pulled in first, you have to prompt explicitly for that order of operations.
- The honesty improvement is real and measurable: the model is four times less likely to report false completion, which changes how much you can trust unsupervised long-running tasks.
- Benchmark scores measure the benchmark — they don't measure your workflow. Test the model on the specific task that frustrated you in 4.7 before declaring it fixed or broken.
- Token efficiency claims from Anthropic are unverified at launch; use a session-level token tracker to confirm whether your actual costs dropped before adjusting budgets.
- A model that feels stubborn or sassy is exhibiting a documented training characteristic, not random behavior — and 4.8 was explicitly retrained to reduce it.