The bait, then the rug-pull.
Anthropic shipped Opus 4.8 the same day, and most creator videos turned it into hype. This one does the opposite - reads the announcement aloud, dismisses the benchmarks, and treats the release as a tell about what is actually coming next from Anthropic.
Where the time goes.

01 · Cold open and no-BS promise
Names the release, promises no benchmark talk, frames the video as honest analysis instead of hype.
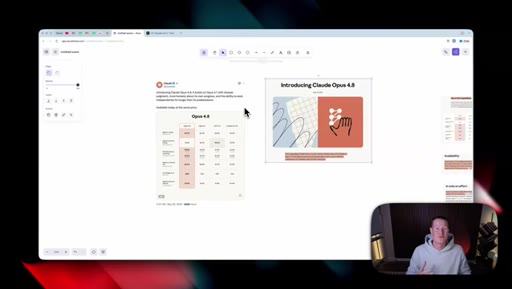
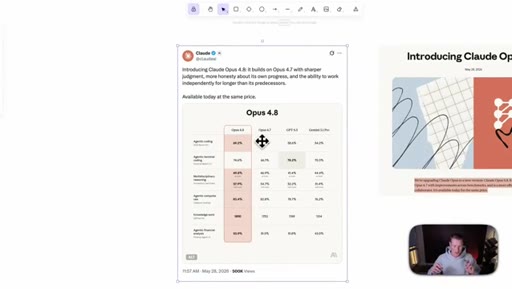
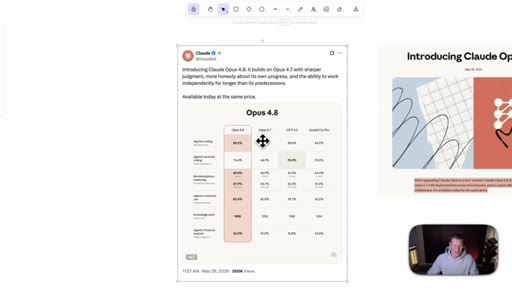
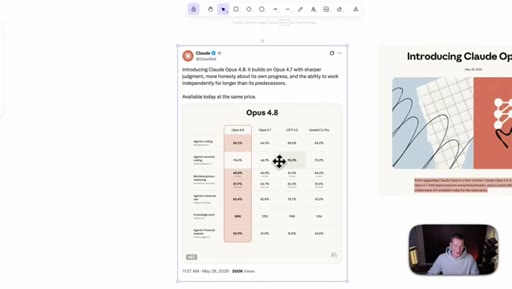
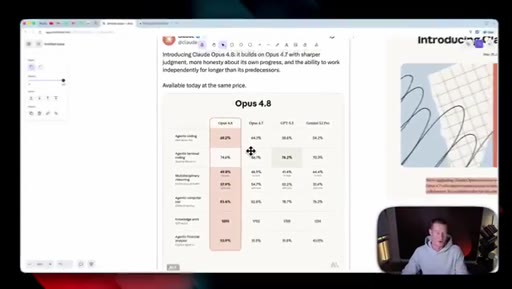
02 · Benchmarks, dismissed
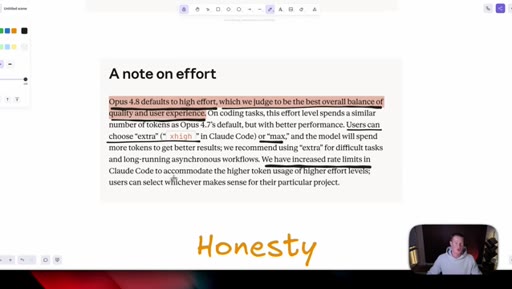
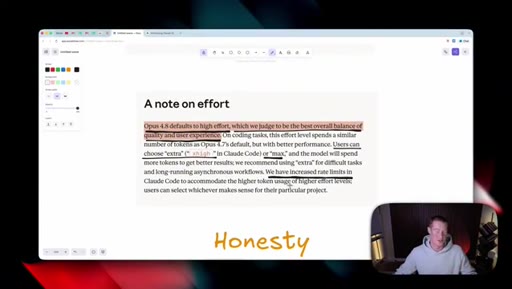
Shows the benchmark table and waves it off; only surviving claim is that Opus 4.8 beats GPT-5.5 and Gemini 3.1 Pro everywhere except agentic terminal coding.
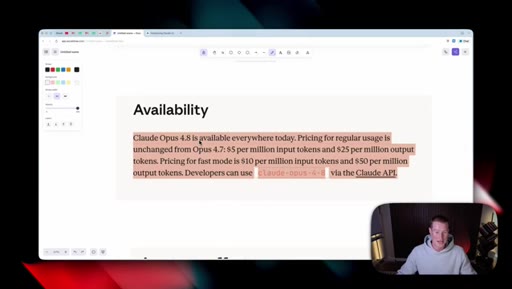
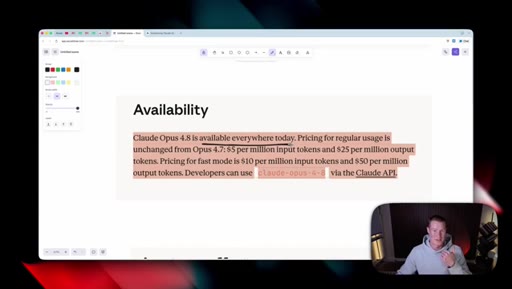
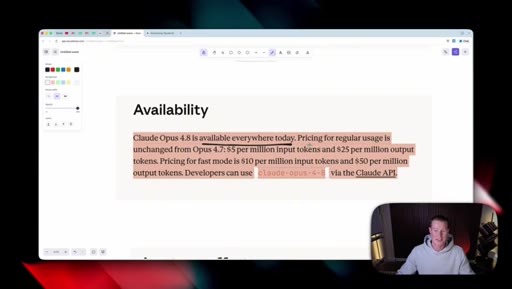
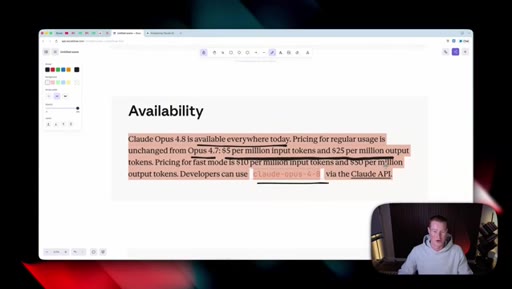
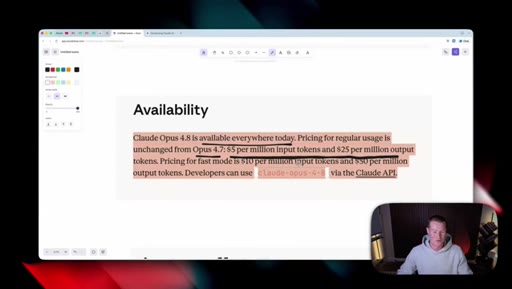
03 · Availability and pricing
Same price as 4.7 ($5/M input, $25/M output). Available in claude.ai, Claude Code, Cowork, and via the API.
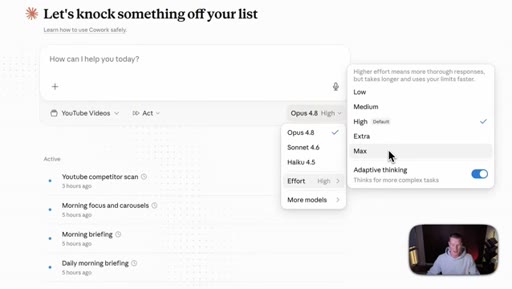
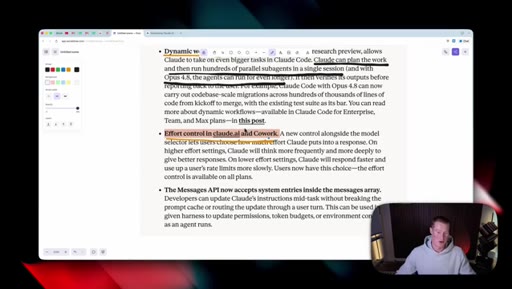
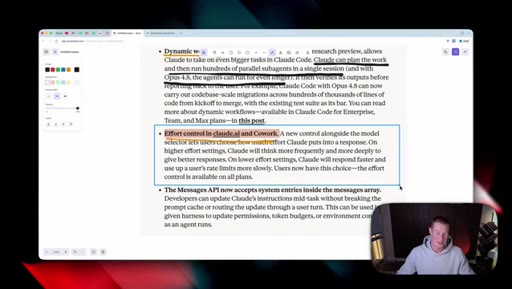
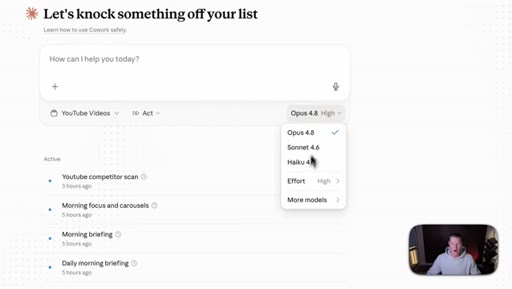
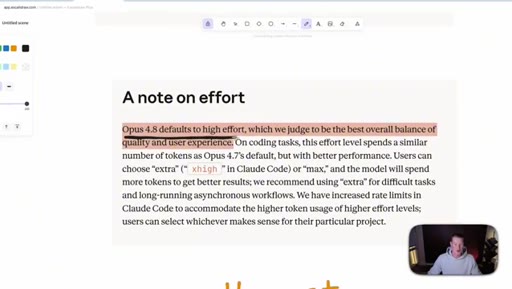
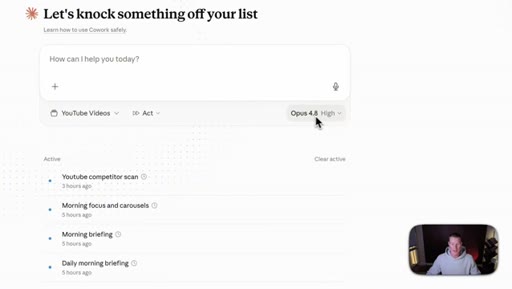
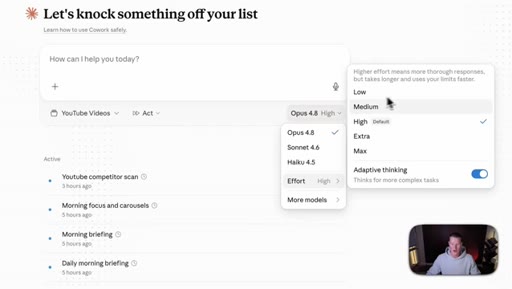
04 · The new effort mode
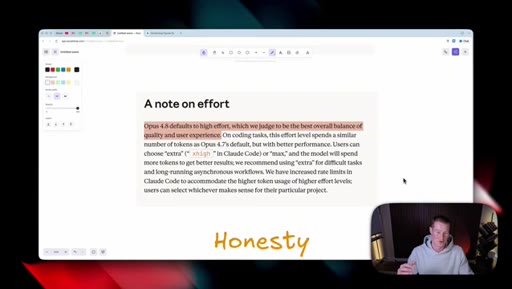
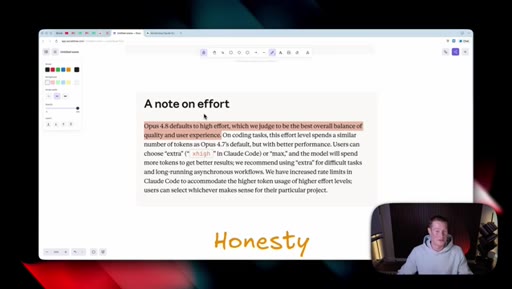
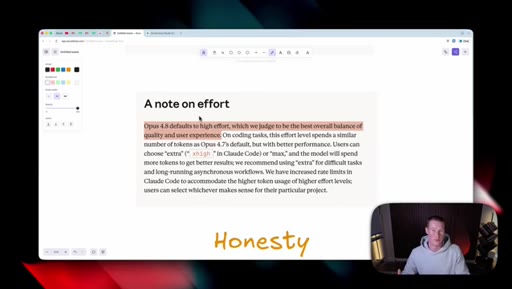
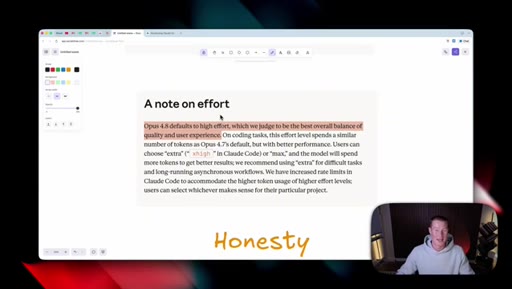
Effort selector (Low / Medium / High / Extra / Max) now lives inside the consumer Claude apps. Opus 4.8 defaults to High. Live demo of the dropdown in Cowork.
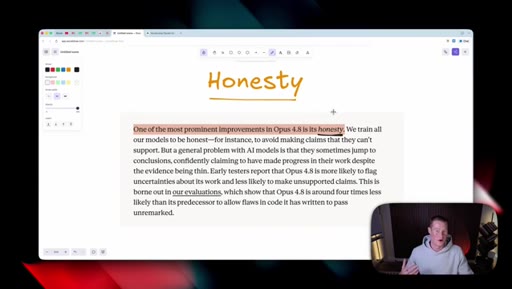
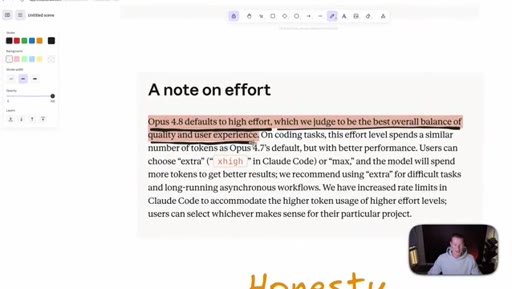
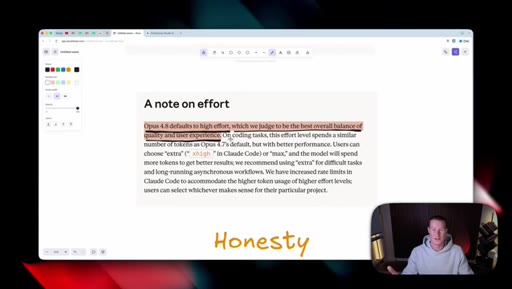
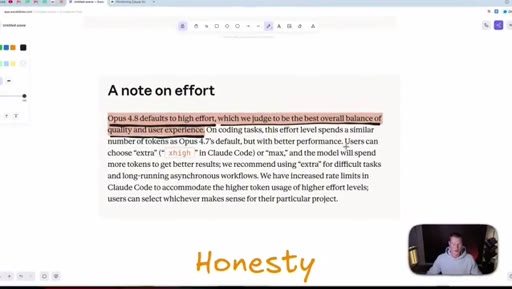
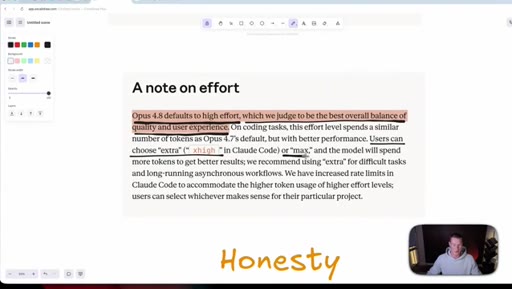
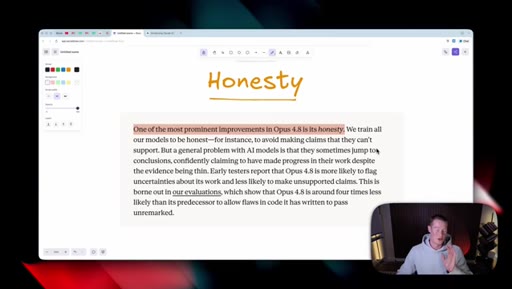
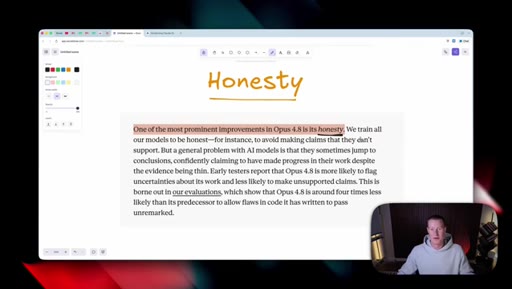
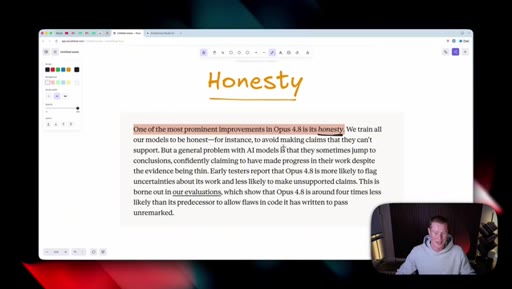
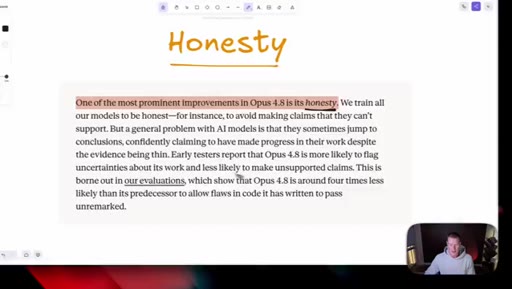
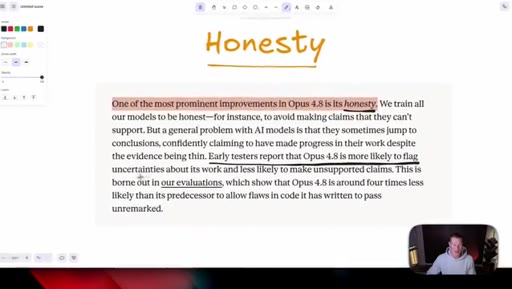
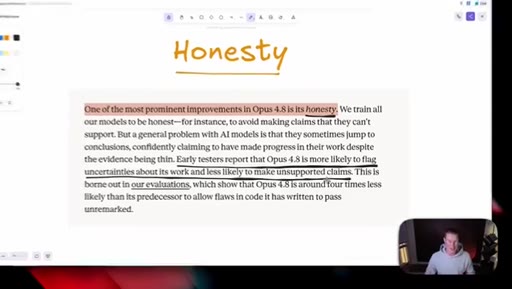
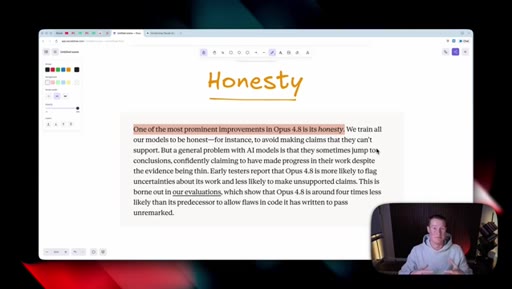
05 · Honesty as headline feature
Anthropic claims Opus 4.8 is roughly four times less likely to fake-pass coding tasks. Host stays skeptical and reserves judgement until he can test it himself.
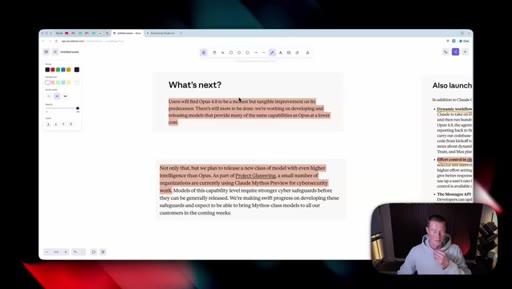
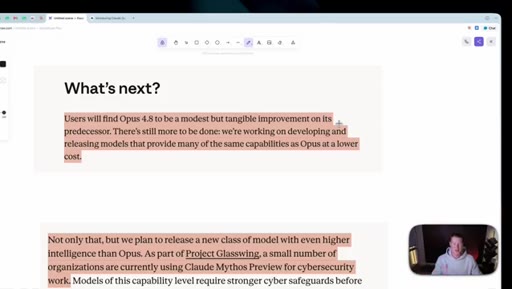
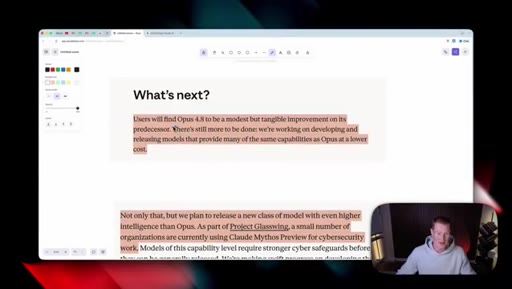
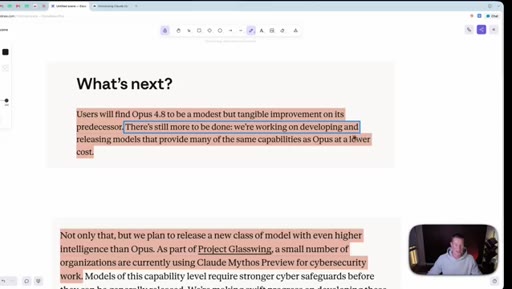
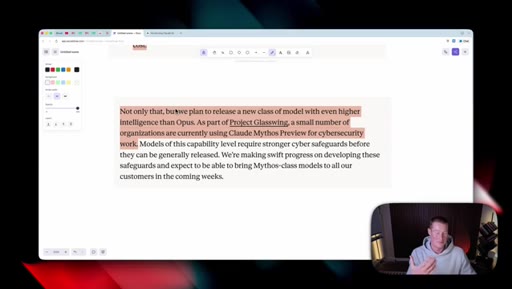
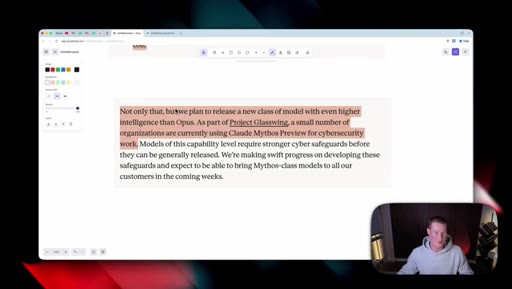
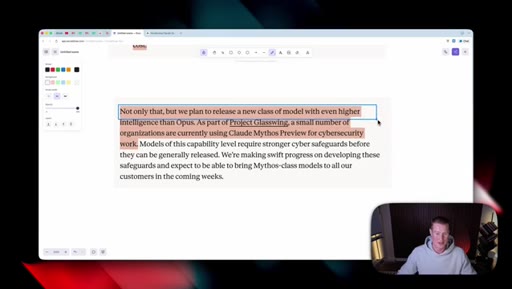
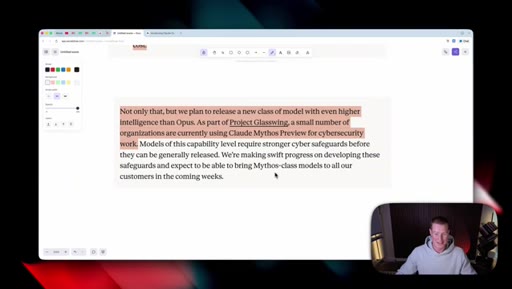
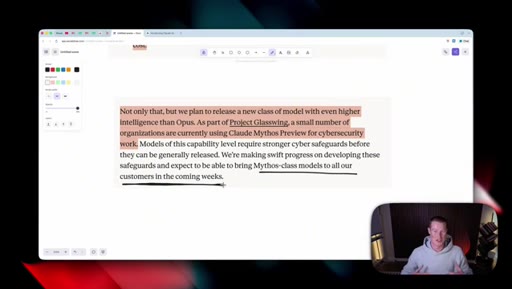
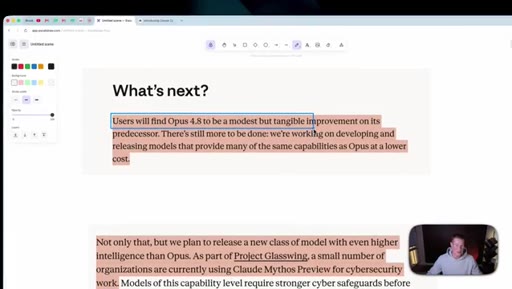
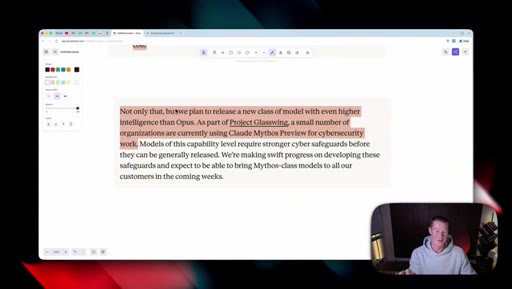
06 · What is coming next: Claude Mythos
Reads Anthropic's own framing (modest but tangible) as the tell. Project Glassuiing is staging Claude Mythos with Fortune 500 cybersecurity testers; expected in claude.ai in the coming weeks.
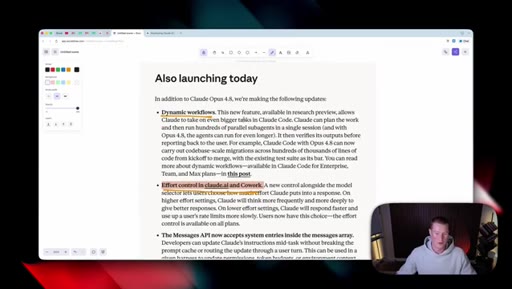
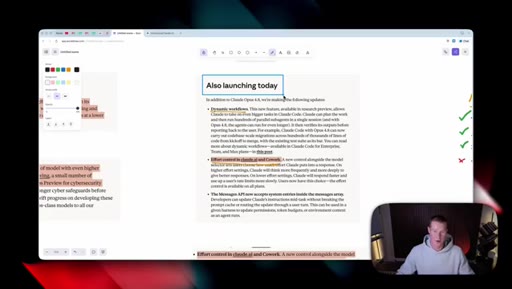
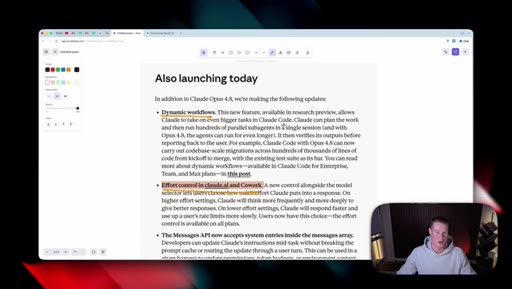
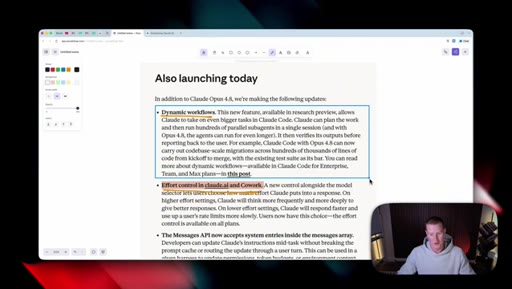
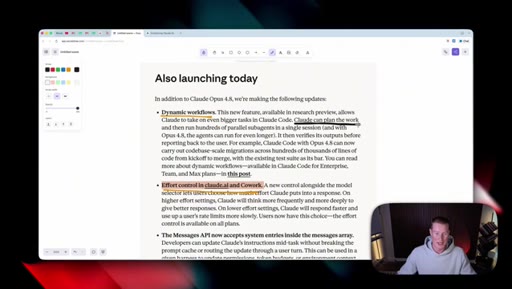
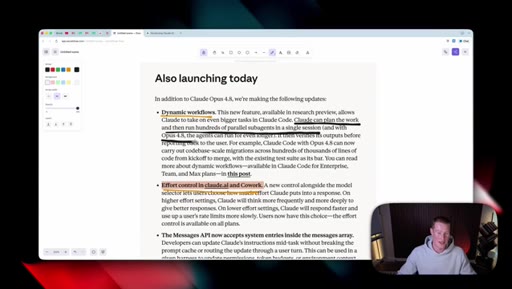
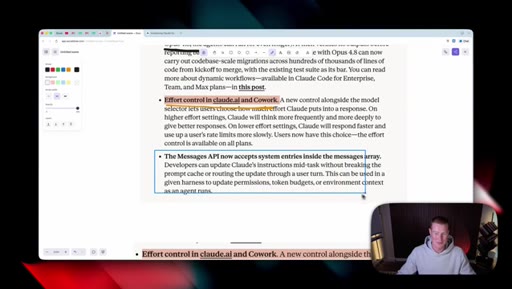
07 · Also launching today
Dynamic workflows in Claude Code (hundreds of parallel sub-agents, can run longer on 4.8). Messages API gains system entries inside the messages array for developers.

08 · Four-takeaway recap
Same price, focus on honest responses, new effort levels, but ultimately small marginal improvements. The real story is Mythos.
Visual structure at a glance.

Named ideas worth stealing.
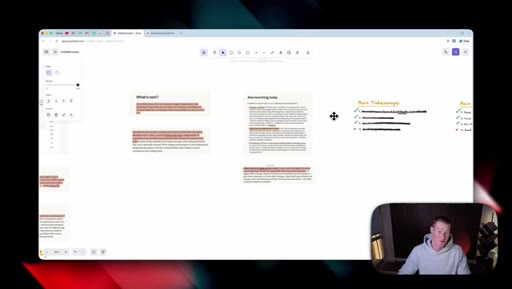
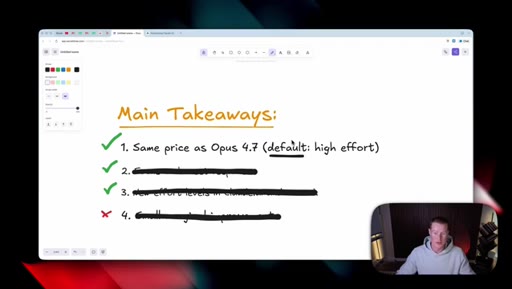
Four Takeaways
- Same price as Opus 4.7 (default high effort)
- Focus on honest responses
- New effort levels in claude.ai and Cowork
- Small marginal improvements - this release is groundwork, not the milestone
The host's own whiteboard distillation, used as the through-line in both the intro and the recap.
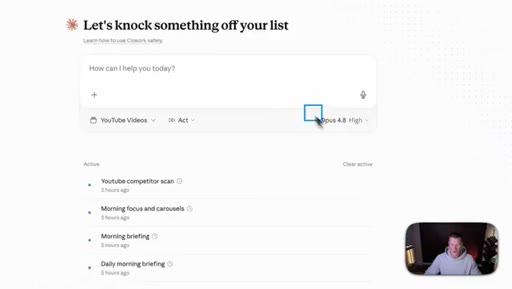
Effort Levels (Cowork / claude.ai)
- Low
- Medium
- High (default for Opus 4.8)
- Extra
- Max
The five effort tiers exposed in the consumer Claude apps for Opus 4.8.
Lines you could clip.
"I'm not gonna talk benchmarks and complicate this. I'm just gonna talk about tangibly what is different."
"One of the most prominent improvements inside of Opus 4.8 is its honesty, which to me, honestly, sounds like a no brainer. You want AI to give you honest responses."
"When they are coming out and saying this is just a modest update, I'm not expecting this to be a huge leap in capabilities."
"Claude Mythos - this is the AI model that apparently is too good for them to release to the public, so they've actually given this to some of the Fortune 500 companies to run internal testing."
"This is definitely not a game changing release. Of course, it is a new level up from Claude Opus 4.7, but I think this is kind of laying the groundwork for a bigger model release in the Claude Mythos preview."
Things they pointed at.
How they asked for the click.
"If you guys got some value from this video, leave a like, subscribe to this channel for more AI content for nontechnical people."
soft, 10-second outro with no funnel mention; relies on watch-time and topic affinity rather than a lead magnet
Word for word.
Read the model card like a release strategist.
Opus 4.8 is the same price and a modest jump - and the most useful thing in the post is the next-model tell Anthropic buried under a headline upgrade.
- Treat Opus 4.8 as a free upgrade: identical pricing to 4.7 ($5/M input, $25/M output) means there is no reason to keep prompting against the older model.
- Use the new effort selector inside claude.ai and Cowork to spend tokens on hard problems and save them on easy ones; High is the safe default Anthropic ships.
- When a model card calls its own release 'modest but tangible' and names a stronger model held back for cybersecurity review, the strategic move is to plan around the next release window, not this one.
- Anthropic's four-times-fewer-fake-passes honesty claim is unverified until you stress-test the model on the kind of code-review or research task that previously hallucinated; do not adopt the claim on faith.
- If you live in Claude Code, dynamic workflows and the new Extra-High effort tier are the only items that materially change your day; everything else is a UX polish.
- Watch the Claude Mythos preview as the real next inflection - Anthropic stating it requires stronger cybersecurity safeguards is a signal it will land with usage limits and access friction, not a clean rollout.