The bait, then the rug-pull.
Every few months someone declares RAG is dead. The claims are usually overhyped and the replacements too simplistic. But Redis just announced something worth actually reading — an architecture called Iris that treats the retrieval problem not as a search problem but as a data infrastructure problem, and that distinction matters more than it sounds.
Where the time goes.

01 · Overview — why RAG fails in production
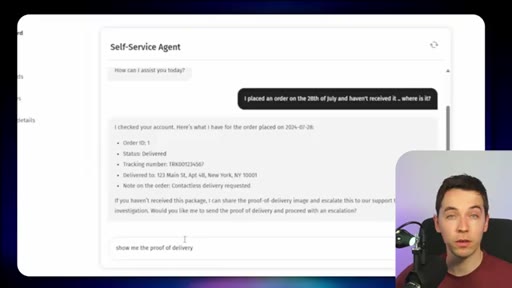
Sets up the core problem with a Redis CEO quote: stale state, fragmented memory, slow retrieval. Customer support bot example illustrates collapse when data spans 5+ systems.

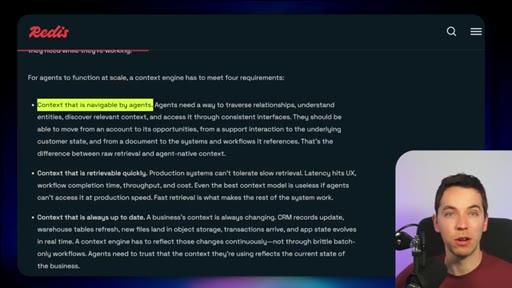
02 · Four requirements for agent retrieval at scale
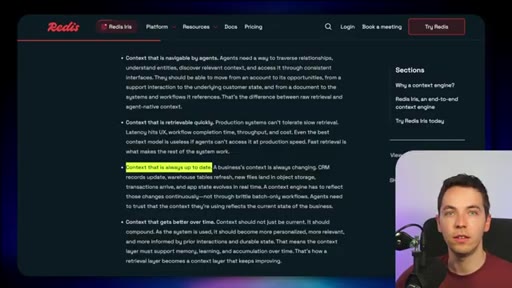
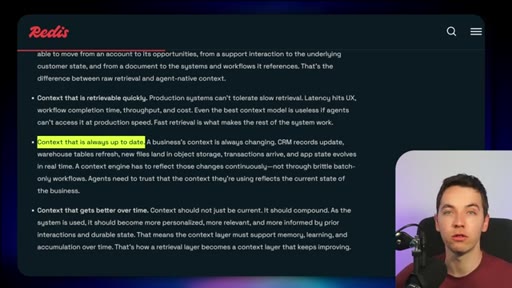
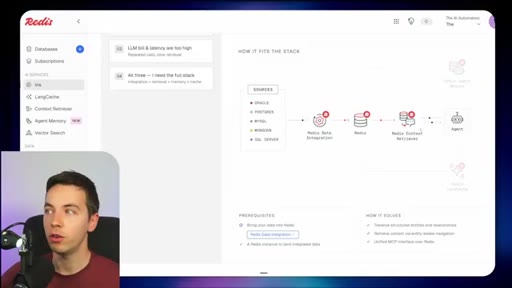
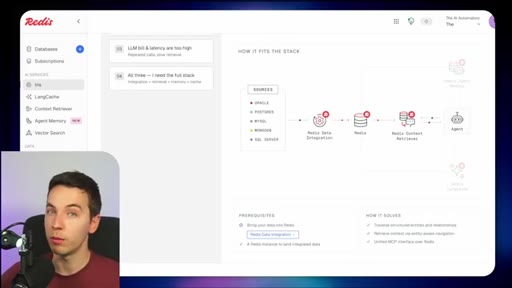
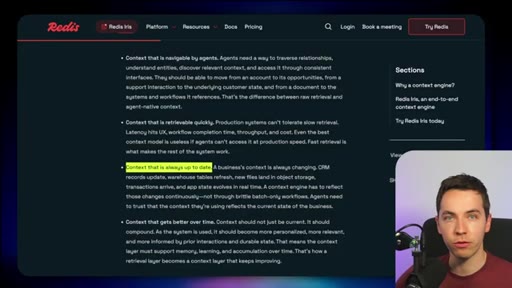
Navigable, fast, always up to date, self-improving. Redis criteria for what a production retrieval layer must deliver.
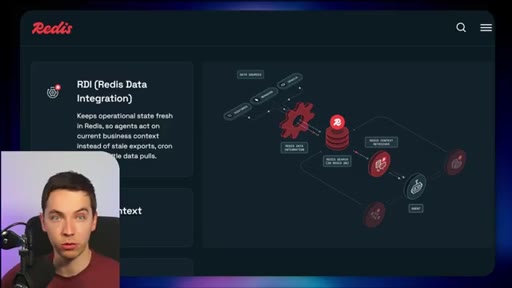
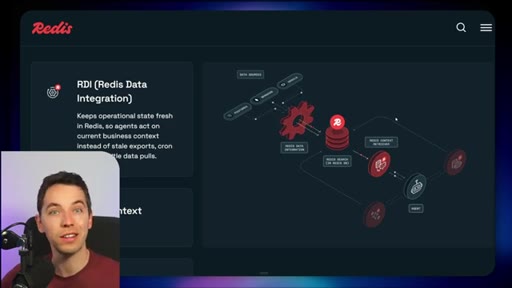
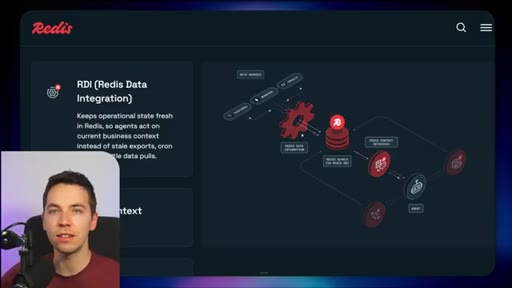
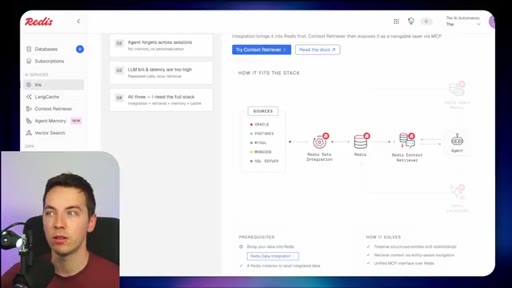
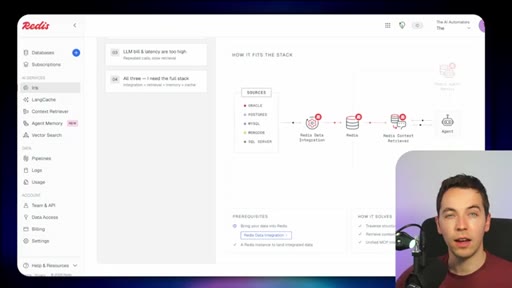
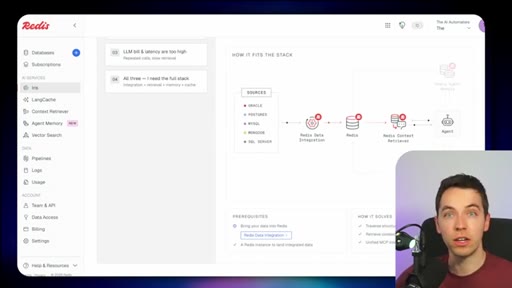
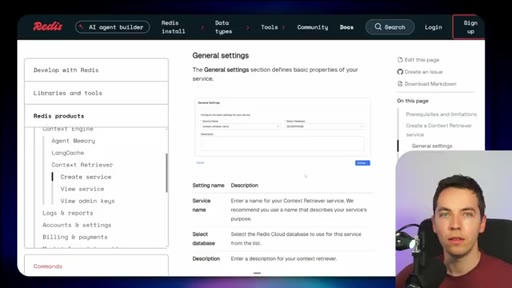
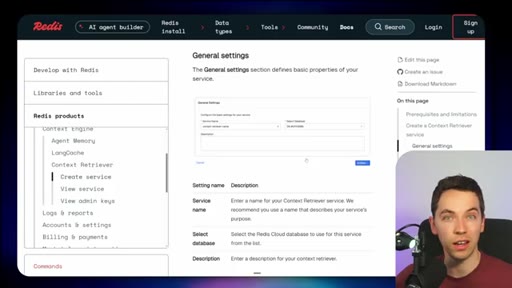
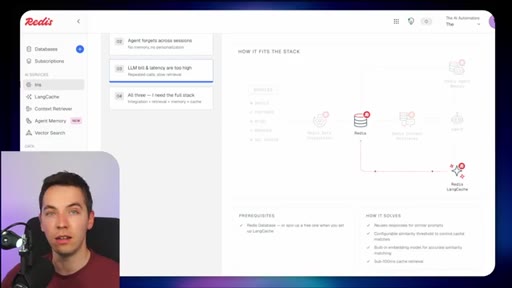
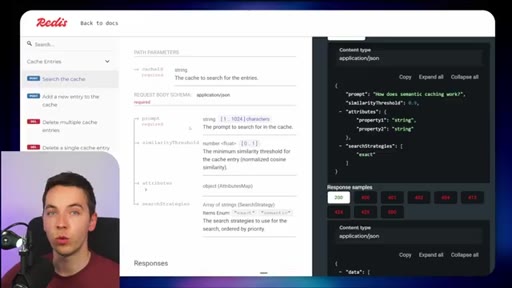
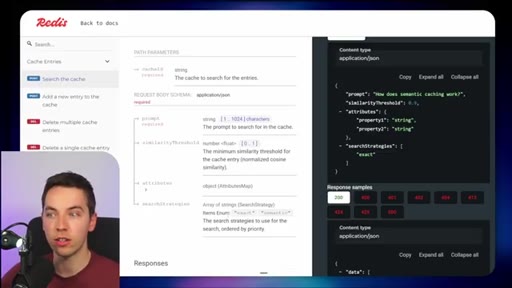
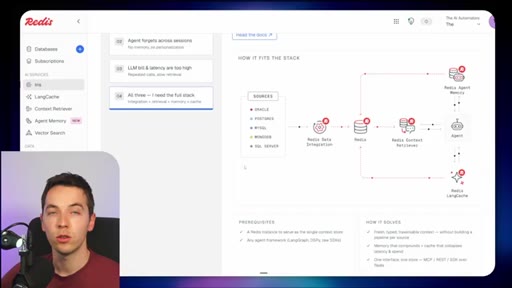
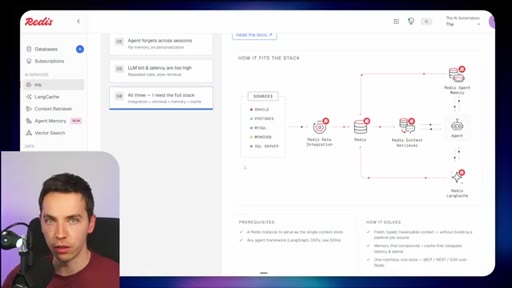
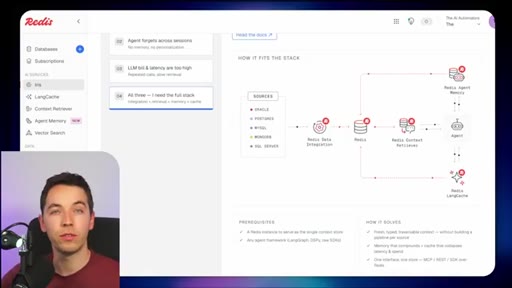
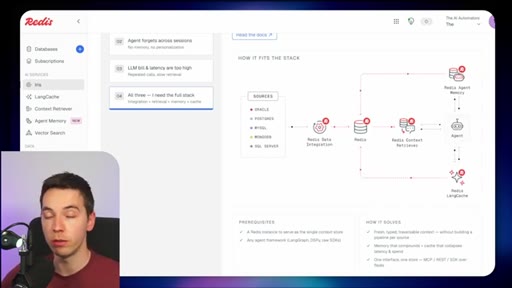
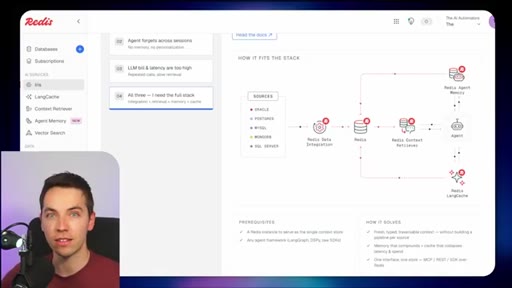
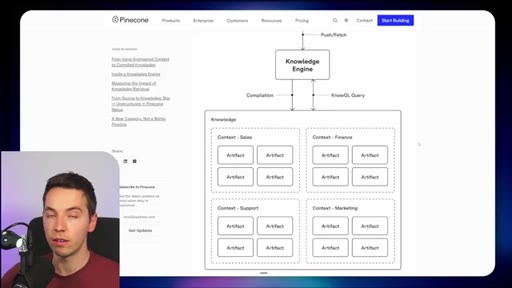
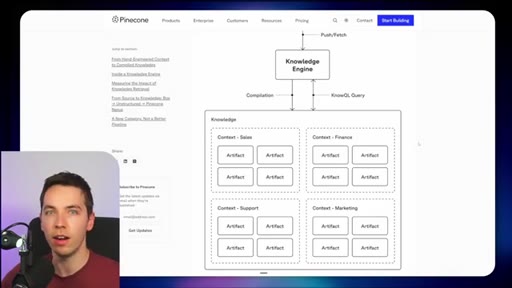
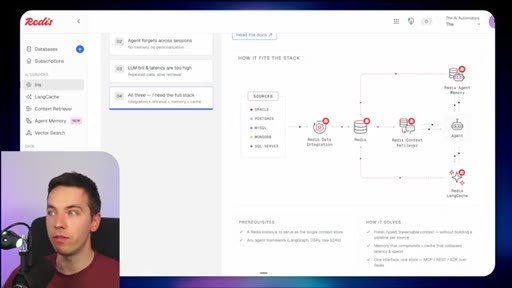
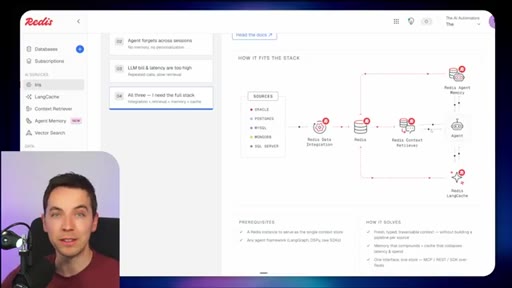
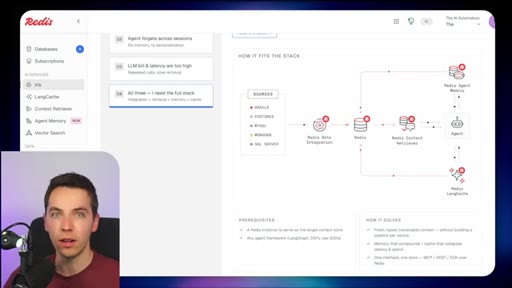
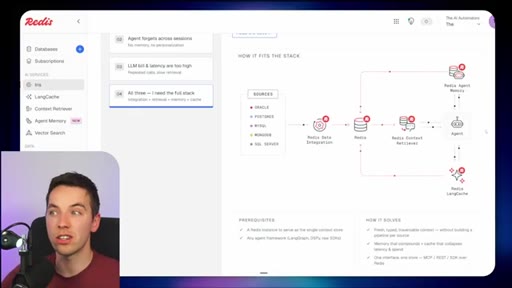
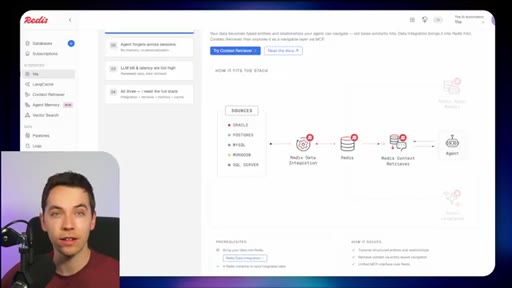
03 · What is Redis Iris
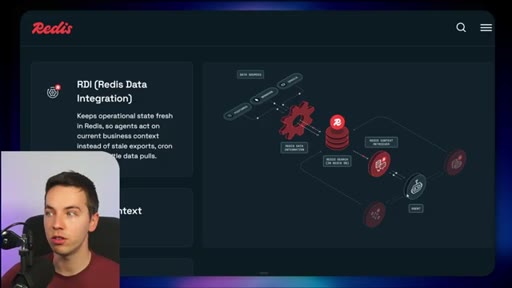
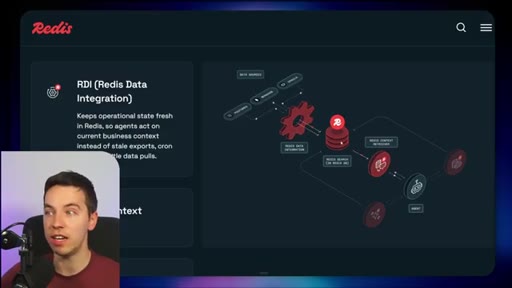
High-level stack: RDI syncs sources into Redis, Context Retriever exposes MCP/CLI tools to agents, Agent Memory persists sessions, LangCache deduplicates responses.
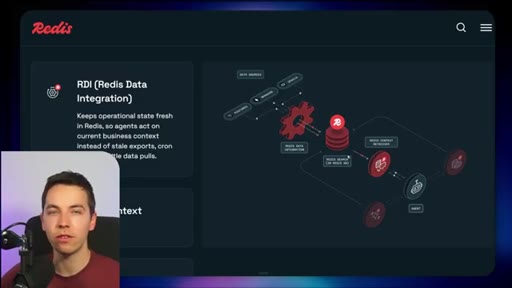
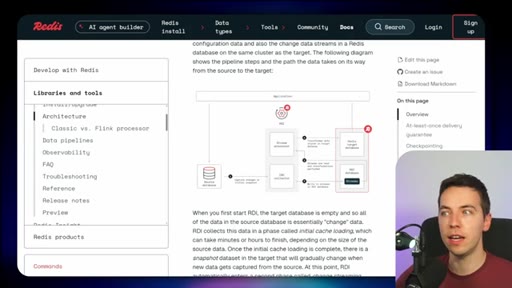
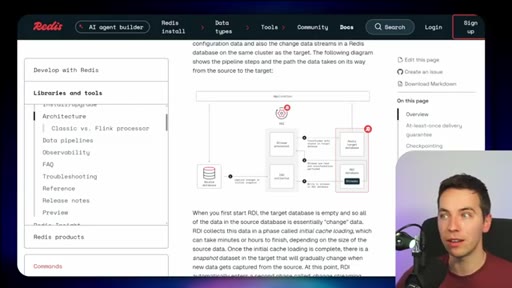
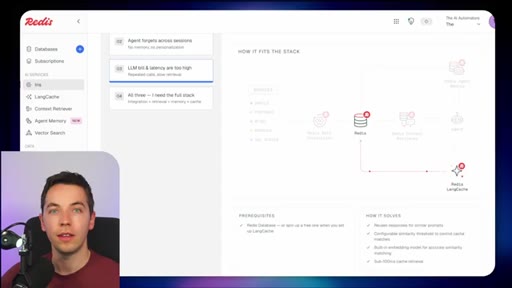
04 · Redis Data Integration (RDI)
Change data capture from Postgres, Oracle, Snowflake, MongoDB. Protects transactional systems from agentic request volume. Enables denormalized, agent-friendly modeling.
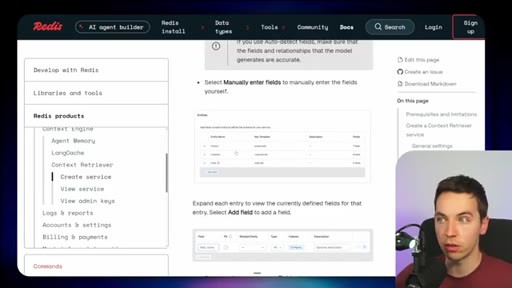
05 · Redis Context Retriever
Define entities, fields, relationships, and role-level access control. Redis auto-generates typed tools exposed to agents via MCP or CLI.
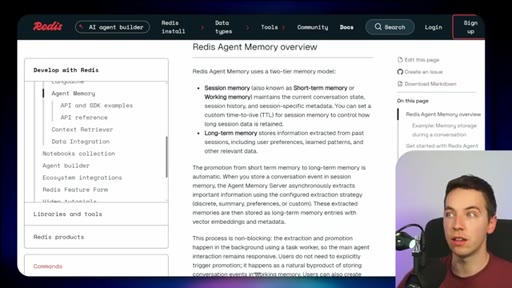
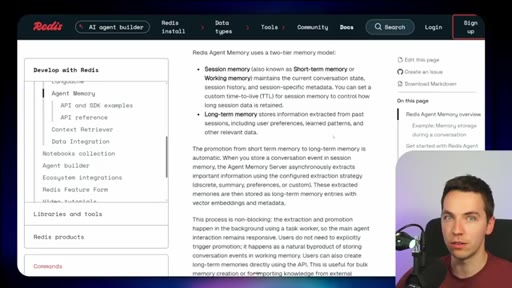
06 · Redis Agent Memory
Short-term session memory with configurable TTL plus long-term memory for promoted preferences and learned patterns.
07 · LangCache — semantic response caching
Caches LLM responses; short-circuits repeated similar queries. Warning: similarity thresholds are blunt and stale cache hits can be contextually wrong.
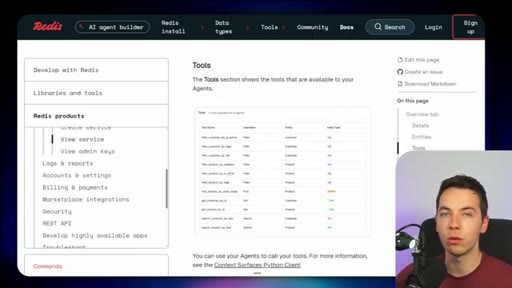
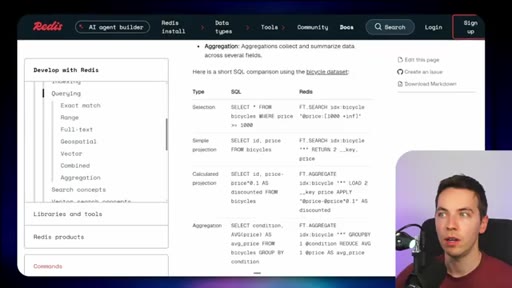
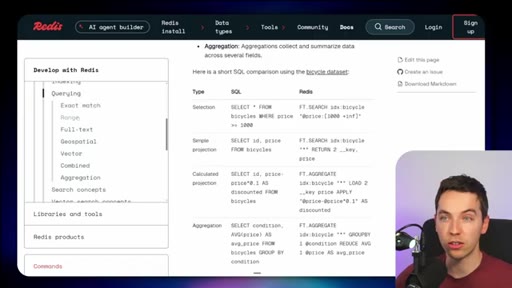
08 · Redis Search and Redis Flex
Single unified index across vector, structured, and unstructured data. Redis Flex is a new SSD tier for billion-vector-scale cost reduction.
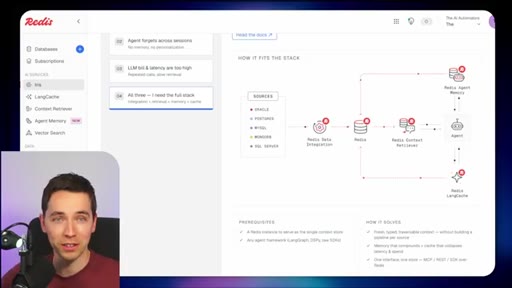
09 · Not plug and play
Honest caveat: modular stack requiring data modeling and ongoing maintenance. Signing up does not solve retrieval.
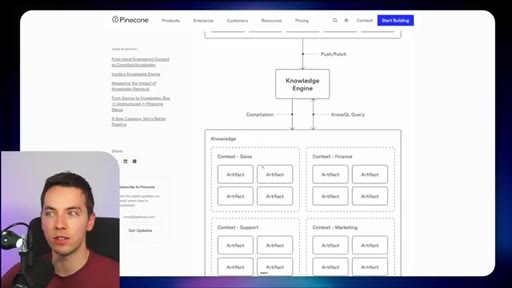
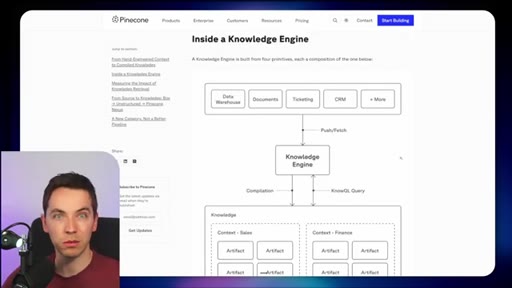
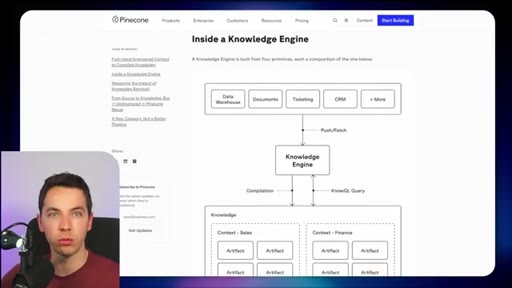
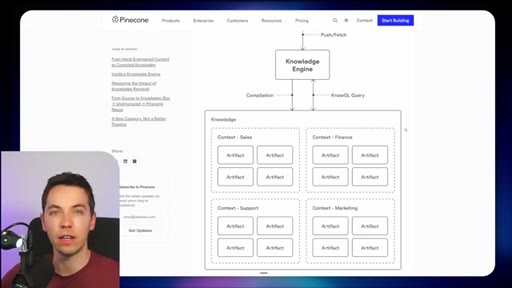
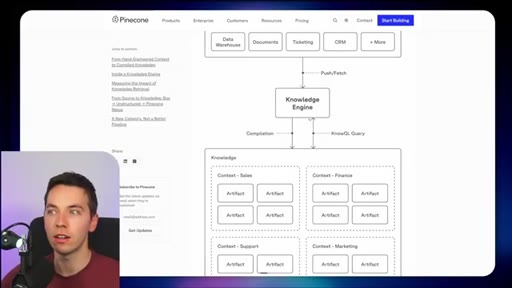
10 · Comparison vs Pinecone Nexus
Build-time (Pinecone) pre-compiles knowledge artifacts for stable recurring-question domains. Runtime (Redis) pulls fresh context on demand for fast-changing operational data.
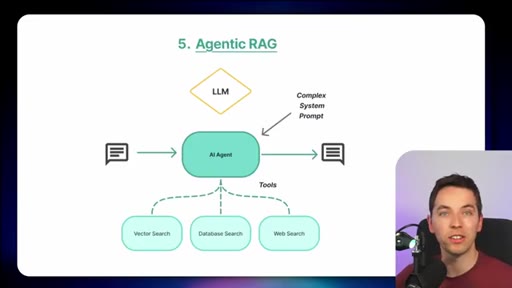
11 · No one-size-fits-all retrieval
Closing argument: match architecture to data volatility. Course CTA and cross-link to Pinecone Nexus video.
Visual structure at a glance.

Named ideas worth stealing.
Four Requirements for Agent Retrieval at Scale
- Navigable
- Fast
- Always up to date
- Self-improving
Redis framing of what a production-grade retrieval layer needs to deliver. Each requirement maps to a component in the Iris stack.
Runtime vs Build-time Retrieval Split
- Runtime (Redis Iris) — fresh data, live mirror, fast-changing environments
- Build-time (Pinecone Nexus) — pre-compiled artifacts, stable knowledge, recurring queries
The central architectural decision frame. Picks the right pattern based on how frequently underlying data changes.
Lines you could clip.
"The hardest problems in production AI are no longer solved by model choice. They show up at runtime, stale state, slow retrieval, fragmented memory, disconnected tools, and sessions that fail to compound."
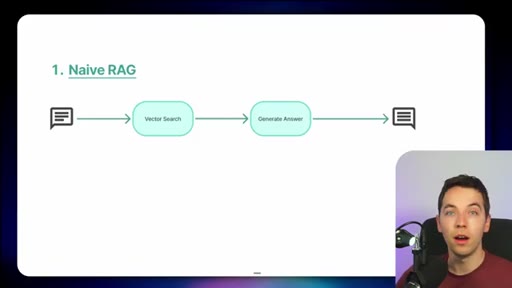
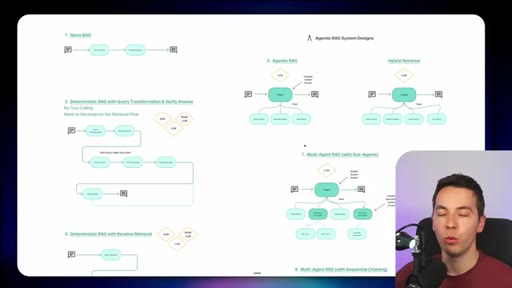
"Naive RAG is almost never going to work in these kind of use cases."
"This is not plug and play, and it will require maintenance."
"A precompiled artifact in a knowledge layer could be stale five minutes after it's created."
Things they pointed at.
How they asked for the click.
"if you want to design a context and retrieval layer that will actually work in production, that's exactly what we cover in our agentic retrieval module inside the AI architects course in our community. Link in the description below."
Low-pressure, value-first setup. The course CTA comes after 10+ minutes of genuinely useful architecture content, making it credible. Cross-linked related video provides a natural next step.
Word for word.
Retrieval architecture, not model choice, determines production success.
When AI agents fail in production the culprit is almost never the model — it is stale data, fragmented sources, and a retrieval layer designed for demos rather than real operational complexity.
- The failure modes of production AI agents — stale context, slow retrieval, fragmented memory, sessions that reset — are infrastructure problems, not model problems.
- Agents querying operational databases directly can generate thousands of times more requests than humans; a dedicated mirror layer is essential to prevent collateral damage to transactional systems.
- Change data capture solves the freshness problem more reliably than scheduled batch exports or cron-based syncs, because it tracks row-level changes continuously.
- Typed entity tools (find by ID, search by text, filter by tag) give agents a far more reliable interface to structured data than open-ended SQL generation or cross-table joins.
- Semantic response caching can reduce LLM costs but is a potential failure point — a cached answer to a similar query can be contextually wrong in a new session; test similarity thresholds rigorously.
- The choice between runtime retrieval (live mirror, on-demand) and build-time retrieval (pre-compiled knowledge artifacts) comes down to one question: how frequently does the underlying data change?
- Pre-compiled knowledge artifacts are right for stable, recurring-question domains like compliance, manuals, and contracts; they become liabilities in fast-changing environments where they can be stale within minutes.
- Short-term session memory with configurable TTL and promotion logic to long-term memory separates a useful production agent from one that re-derives context from scratch on every call.