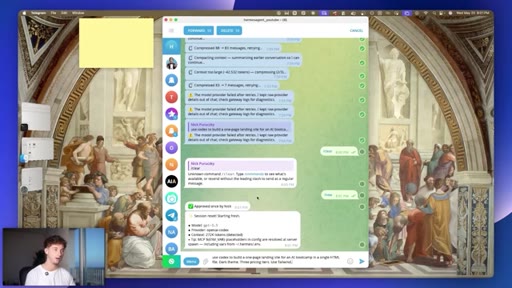
The bait, then the rug-pull.
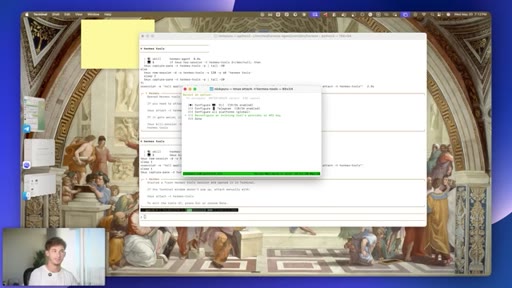
Thirty days, nine updates, and half of what this video demonstrates was not technically possible a month ago. The host opens with personal proof -- a six-week-old sponsor email retrieved in under a second, an inbox ranked in the background while filming -- before committing to show the updates that actually move the needle rather than flashy demos.
Where the time goes.

01 · Hook + proof claims
Personal usage proof, stakes the 9-update promise, no developer knowledge required
02 · Webinar sponsor block
June 3 live webinar pitch for AI agency offers
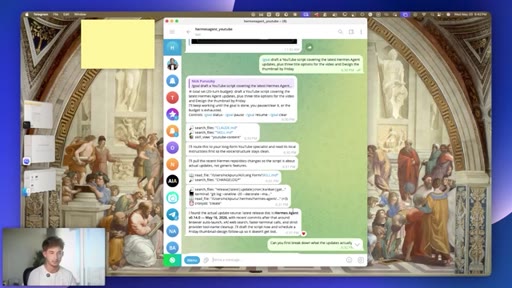
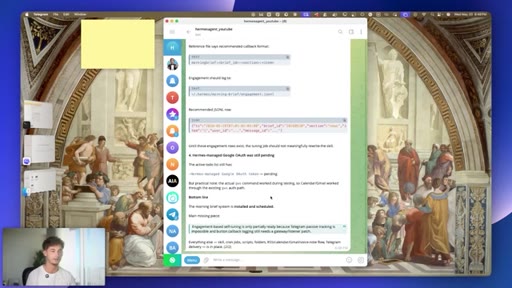
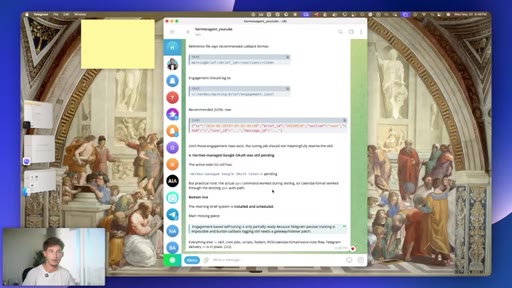
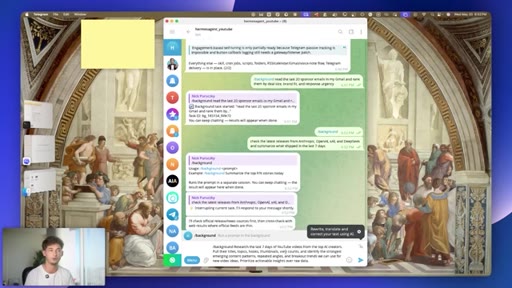
03 · #1: Slash goal
Pinned multi-turn objectives, judge model, Ralph loop, slash sub-goal
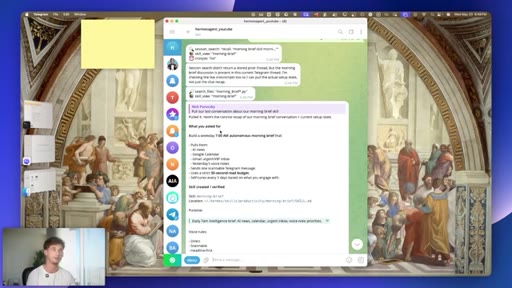
04 · Goal quality caveat
Vague goals break the judge model -- specificity is the lever
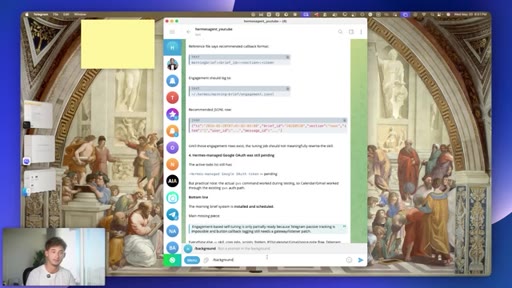
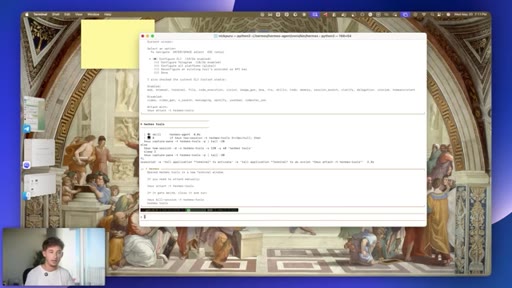
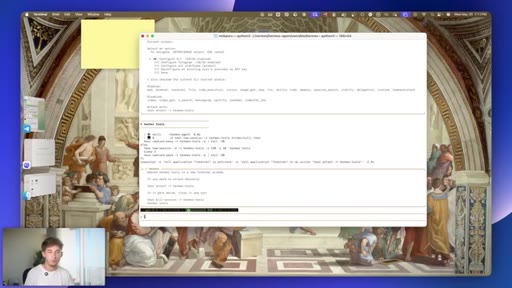
05 · #2: Memory upgrade
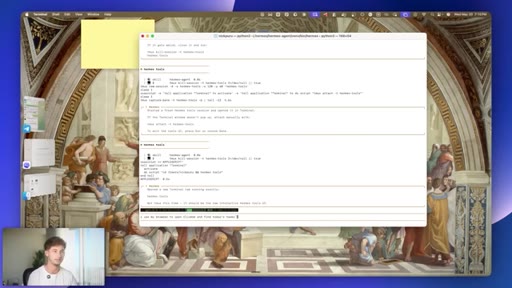
Full session recall, cross-session cache, tool call indexing, zero setup
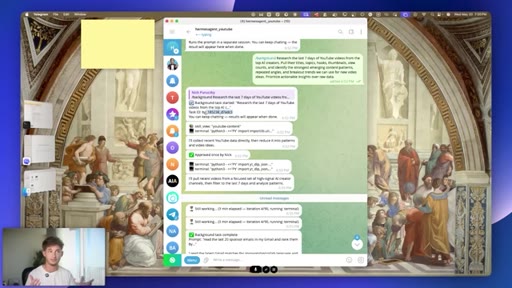
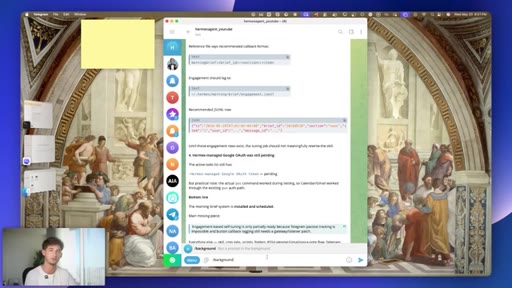
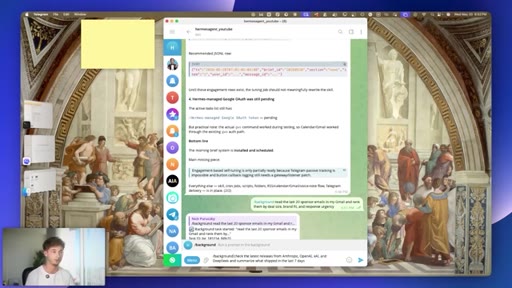
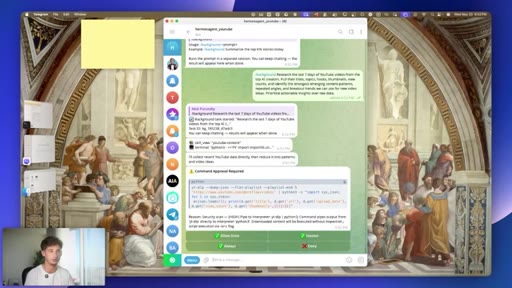
06 · #3: Slash background
Five concurrent background tasks, task IDs, foreground chat stays live
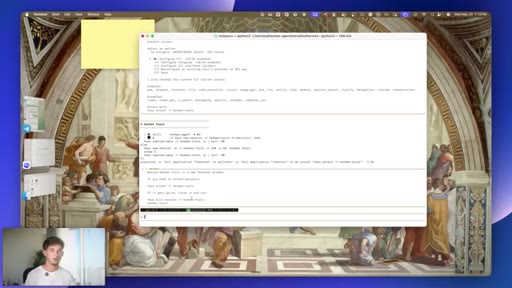
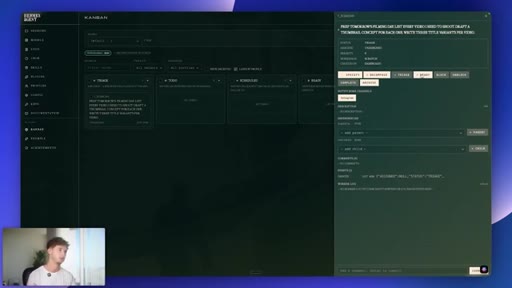
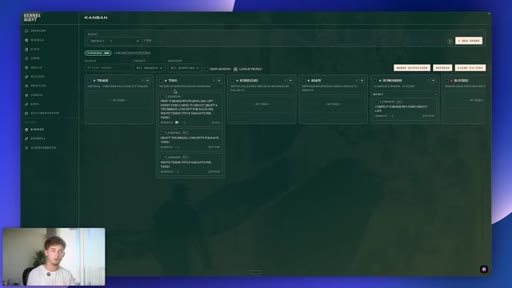
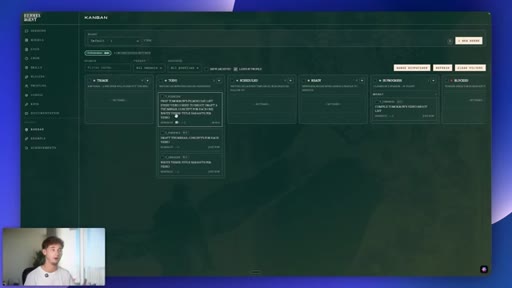
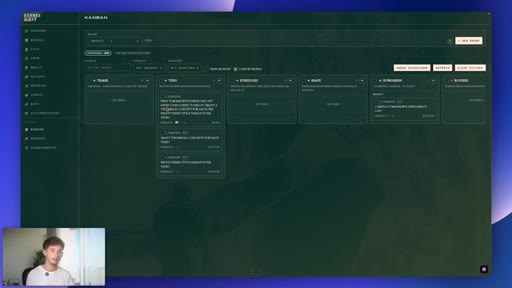
07 · #4: Auto Kanban
Triage to Specifier to subtasks to parallel sub-agents, orchestration=auto, demo with filming day brief
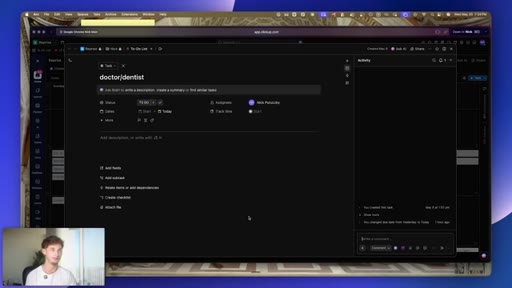
08 · #5: Computer use (any vision model)
Previously Claude-only; now GPT-5, Gemini, Grok Vision -- ClickUp navigation demo, remote task marking from phone
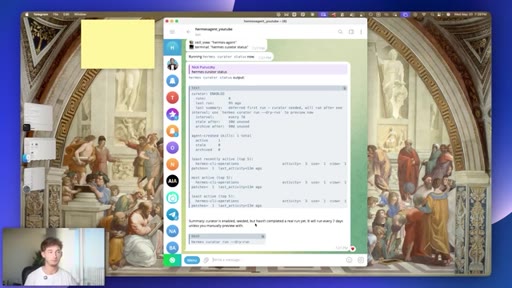
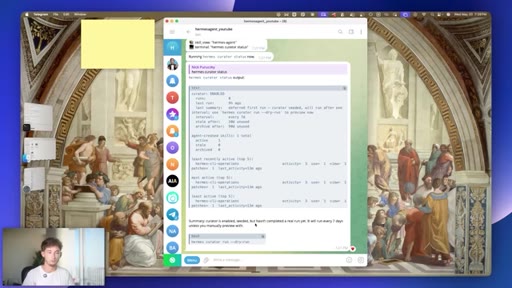
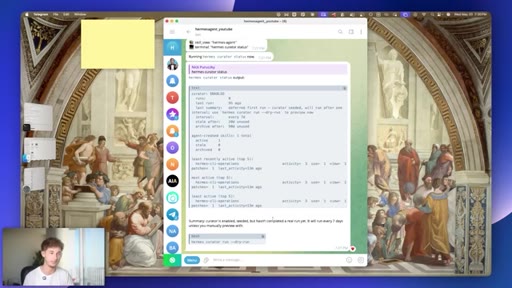
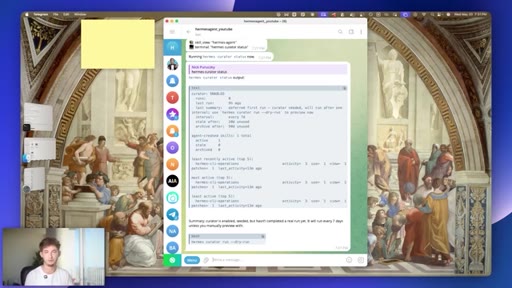
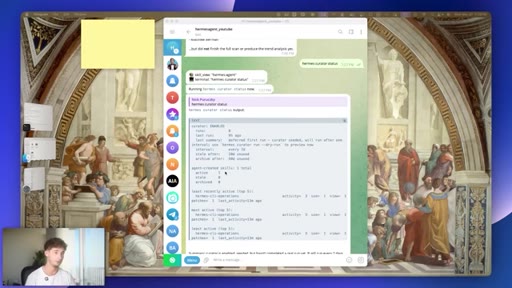
09 · #6: The Curator
Auto-running 7-day skill pruning agent, ranked skill list, zero config
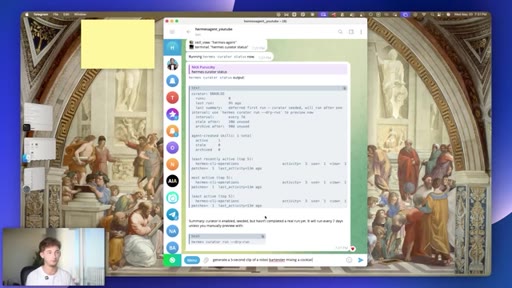
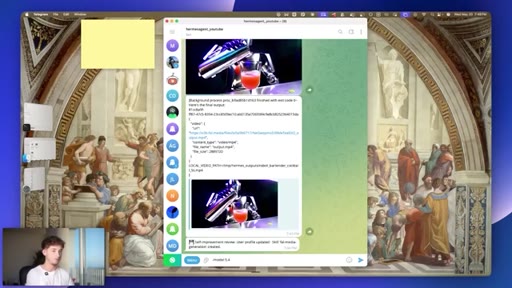
10 · #7: Native video generation
Text-to-video via Grok or Fal.ai natively in Telegram, robot bartender demo

11 · #8: Slash model
Mid-conversation model swap, preserve full context, auto-selection by task complexity
12 · #9: Codex as a worker
Route coding to ChatGPT/Codex CLI -- Opus plans, Codex builds, Anthropic API untouched, landing page demo
13 · Top 4 + CTA
Host ranks slash goal, curator, slash model, native Codex as the four most slept-on; community plug
Visual structure at a glance.
Named ideas worth stealing.
Ralph loop
An agent lock-on pattern where the stated goal persists pinned across every conversation turn until explicitly cleared, with a judge model checking progress each turn.
Opus plans, Codex builds
A two-specialist stack where the high-reasoning model handles architecture and planning, and the coding agent handles line-by-line execution on the user's ChatGPT subscription.
Lines you could clip.
"The recall, the cache, the tool call history, all of it -- it is going to be on by default. It just works."
"From my phone, I was able to just text Hermes and told it to mark it as done. I didn't have to pull up my laptop or anything like that."
"Most of the stuff that you are doing, it's probably just clean up, or formatting, or quick look ups, or like simple summaries. Tasks that a much cheaper model could handle just as well."
"Opus, it should be your strategist. Codex, it should be your builder. And you don't even have to pick which one does what part."
"The goal that you write is what makes or actually breaks it. Something as simple as build me an application -- that is far too fundamental, far too broad."
Things they pointed at.
How they asked for the click.
"It's the first link in the description. It's completely free. Come drop a comment when you are in."
Soft community plug at end. Secondary CTA for a live webinar placed mid-video at minute 1:34 with higher pressure framing (not recorded, miss it if absent).
Word for word.
Nine ways to stop babysitting your AI agent.
The core failure mode of every local AI agent is drift -- losing the goal, losing the context, blocking you while it works -- and these nine updates address all three at once.
- Pinning a goal with an explicit success criterion and a judge model is structurally different from just typing instructions -- the judge creates an independent review loop that catches when the agent wanders.
- Cross-session memory recall costs nothing to configure; the value comes from being specific enough in your original requests that the indexed history is actually retrievable later.
- Running parallel background tasks requires thinking in queues: fire multiple jobs simultaneously rather than waiting for each one to complete before starting the next.
- A raw idea dropped into an auto-orchestrated Kanban only produces useful subtasks if the original brief is tight -- vague inputs produce vague specs, regardless of how sophisticated the Specifier agent is.
- Model-switching mid-conversation makes economic sense only if you audit which tasks in your workflow actually require high-reasoning models versus which ones are cleanup, formatting, or lookup.
- Routing code generation to a CLI worker rather than the primary agent changes the cost structure of building: planning tokens are cheap, but execution tokens on premium models add up fast across long builds.
- A self-maintaining skill library compounds over time -- skills you use daily rise to the top, dead weight gets pruned, and the agent response quality on frequent tasks improves without manual intervention.
- Computer use gains most of its practical value not from obvious demos but from the edge case: completing a task on your machine while you are physically away from it.