The bait, then the rug-pull.
The quiet frustration nobody warns you about when you start using AI agents in the terminal: the agent that finally understood your naming style and the weird workaround you needed for that one service wakes up the next session as a total stranger. Every word of re-explaining burns tokens just to reach the starting line you were already at.
Where the time goes.
01 · The cold-start problem
Names the pain: agents forget everything between sessions, turning context re-entry into token waste. Branded slide sequence S01-S04.
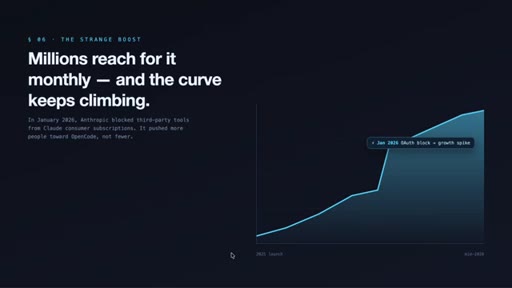
02 · OpenCode and the strange boost
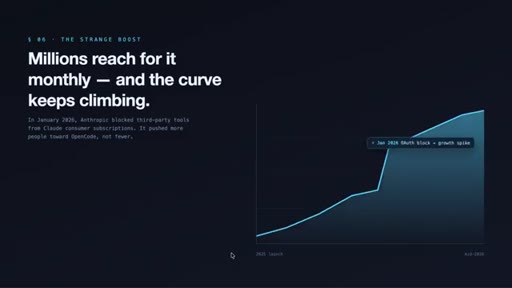
Introduces OpenCode as a provider-agnostic terminal agent. Notes the January 2026 Anthropic third-party block accelerated adoption by making provider agnosticism look like insurance.
03 · What ClaudeMem does
Silently watches agent activity (files, edits, commands, API calls), compresses to summaries, stores locally, injects relevant pieces at next session start.

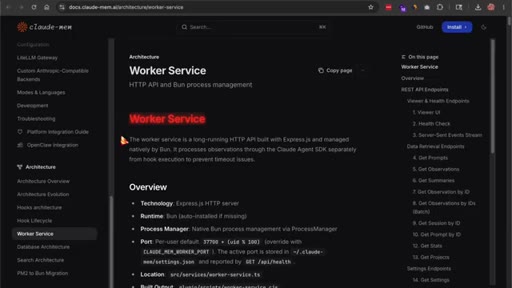
04 · Local database and vector search
Architecture: SQLite for storage plus a vector search index for semantic retrieval — plain-language queries surface memories even when phrased differently than originally recorded.

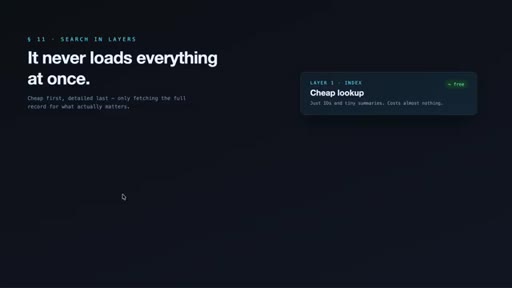
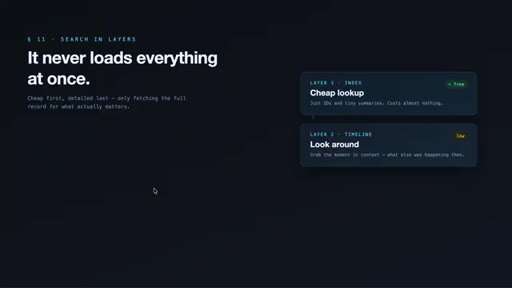
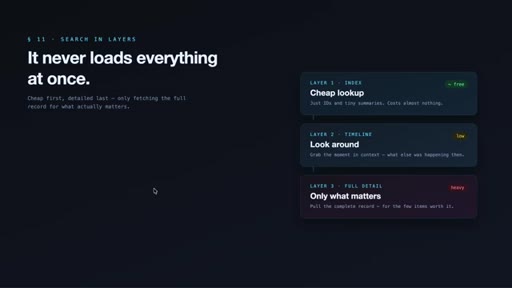
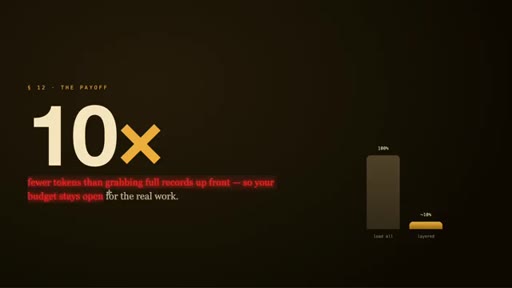
05 · The 3-layer retrieval design
Cheap index first (~50-100 tokens), timeline context second, full detail last and only for specific items. Claimed 10x token savings vs. loading full records.
06 · Lifecycle hooks
How capture is automated: hooks fire at session start, prompt sent, tool run, session end. No manual input required.
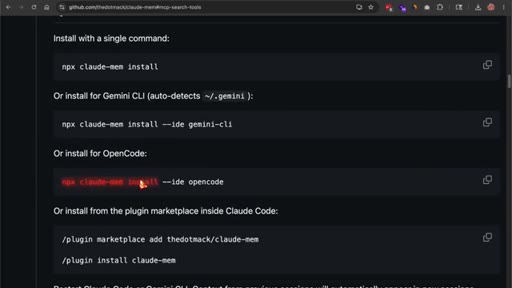
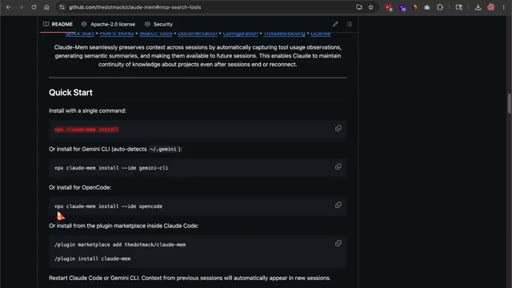
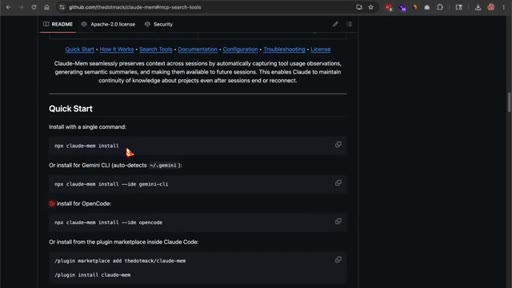
07 · One-line install on OpenCode
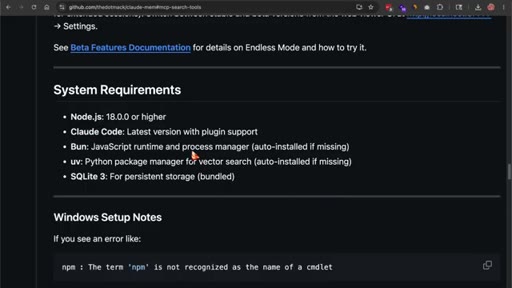
npx claude-mem install --ide opencode. Installer handles Bun and uv if missing. Requires Node 20+ and OpenCode pre-installed.
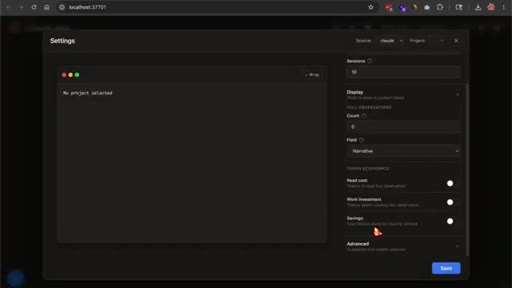
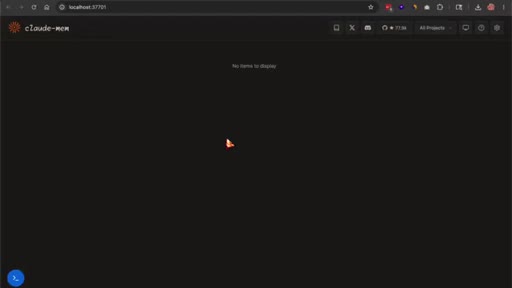
08 · Web viewer and first-session reality
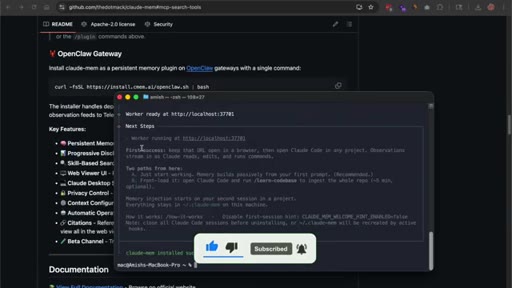
Worker runs at localhost:37701. Dashboard shows no items on fresh install by design. Memory builds as sessions accumulate.
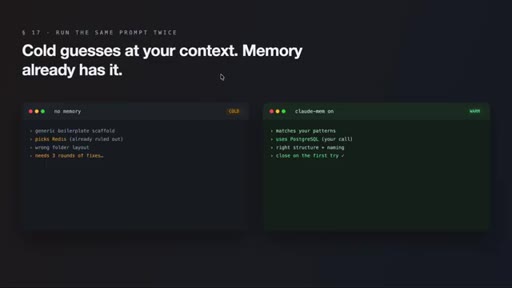
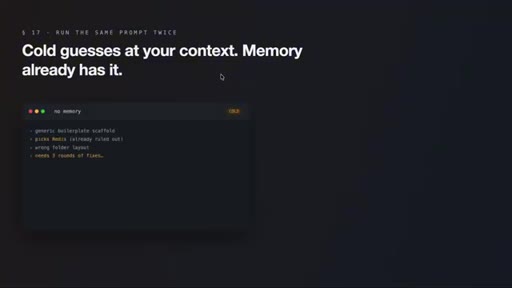
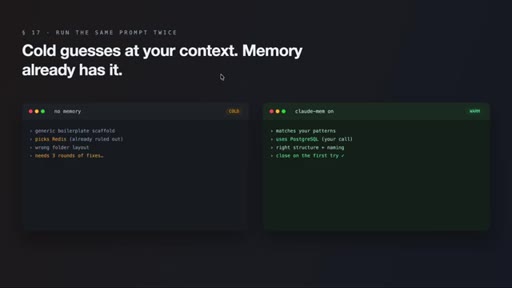
09 · What actually changes
Session two onwards: agent stops re-pitching ruled-out options, remembers bug patterns, matches code style. Cold vs. warm prompt comparison illustrates the gap.

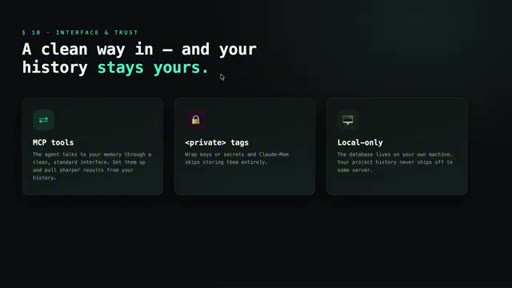
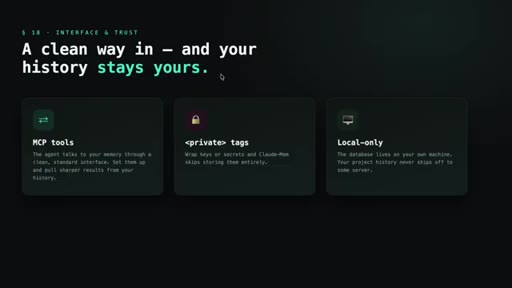
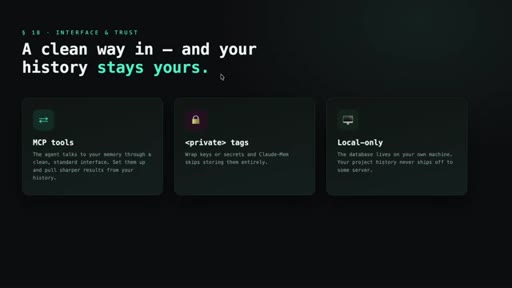
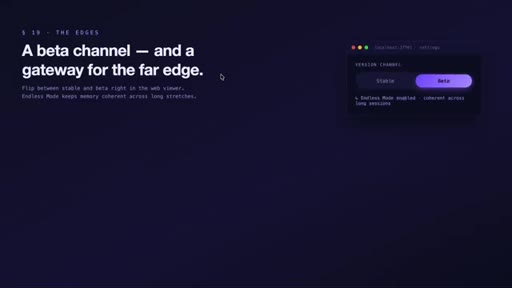
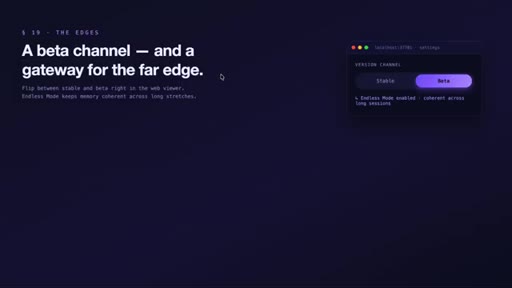
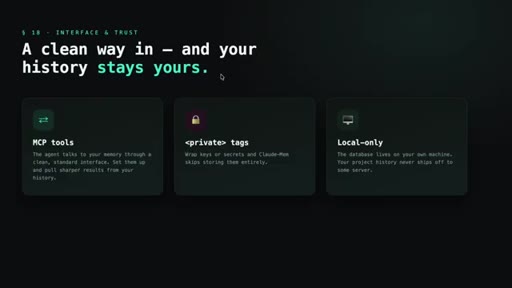
10 · Interface, privacy, and edge features
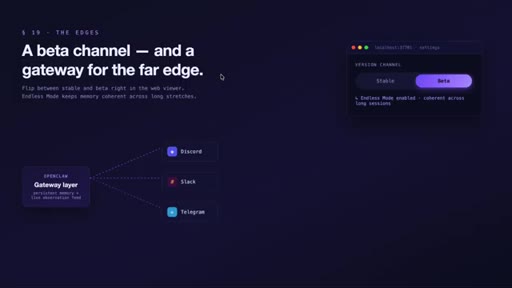
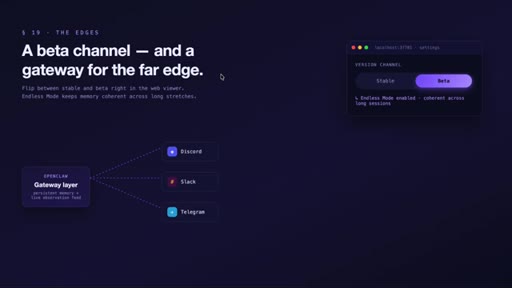
MCP tools expose search to the agent. Private tags exclude secrets from capture. Data stays local. Beta: endless mode + OpenClaw gateway for Slack/Discord/Telegram.
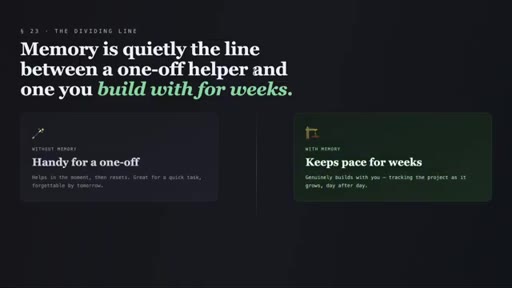
11 · The honest part and the bigger picture
Caveats: wrong assumptions get persisted; pause during throwaway sessions; prune stale memories. Closing argument: persistent memory is the line between a one-off helper and a weeks-long build partner.
Visual structure at a glance.






Named ideas worth stealing.
The 3-Layer Memory Retrieval Workflow
- search — compact index, IDs + tiny summaries (~50-100 tokens)
- timeline — chronological context around interesting observations (low cost)
- get_observations — full detail only for filtered IDs (~500-1,000 tokens)
ClaudeMem's token-efficient memory lookup applies three sequential filters before fetching expensive full-detail records, claiming ~10x savings vs. naive full-record loading.
Lines you could clip.
"Every word of re-explaining is burning tokens just to get back to the starting line you were already at."
"Persistent memory is quietly becoming the line between an agent that's handy for a one-off task and one you can actually build with over weeks."
"Treat it like a tool you steer, not one you set loose and forget."
Things they pointed at.
How they asked for the click.
"If you did, please like this video and subscribe to the channel, and I'll see you in the next video."
Minimal single-sentence close after the main content. No product pitch, no newsletter, no sponsor.
Word for word.
Why every agent session starting cold is a compounding tax.
Re-explaining project context to a fresh agent session is not just friction — it is a measurable token cost that compounds across every day of development on the same codebase.
- Every session that starts cold forces the agent to guess at decisions you already made — the corrections you give it are tokens spent going backwards, not forwards.
- A three-layer retrieval pattern — cheap index first, timeline context second, full detail only for specific items — keeps memory injection from cannibalizing the context window you need for actual work.
- Vector search on past session observations means you can describe a prior decision in plain language and surface the right memory even if the phrasing is completely different from how it was originally captured.
- The quality of persistent memory is bounded by the quality of what the agent did during sessions — a wrong assumption that gets compressed and saved becomes a persistent false belief that requires deliberate correction.
- Local-only storage removes the cloud dependency that would make a background memory service a single point of failure for production workflows, and it is the privacy default, not an opt-in.
- The compound effect of memory only becomes visible after the second session — expecting immediate results from a fresh install is the wrong mental model for evaluating whether the tool works.
- Pausing memory capture during throwaway or experimental branches is not optional hygiene — it prevents the permanent library from accumulating dead-end context that will mislead future sessions.