The bait, then the rug-pull.
The workflow has changed. Not because the tools changed first, but because the experience of building complex features taught a different discipline — one where the model writes the code and an automated reviewer decides when it is good enough to ship.
Where the time goes.

01 · Workflow overview
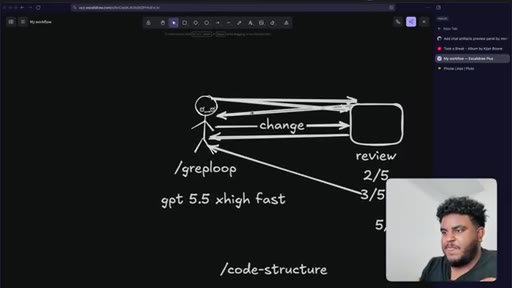
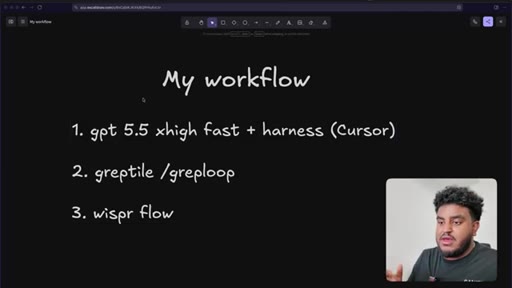
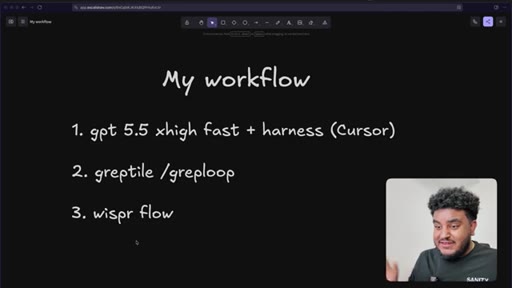
Three-tool stack introduced: GPT-4.5 xhigh fast in Cursor, Greptile /greploop for automated review, WhisperFlow for voice prompting.
02 · Pluto demo + feature goal
Tour of the Pluto app (chat, tasks, routines, files, finance, desktop computer). Feature goal stated: Claude-style artifacts panel.
03 · Prompting Cursor + plan mode
Voice prompt via WhisperFlow asks Cursor to research Claude artifacts, then generate a build plan. /code-structure skill explained. Sub-agents deployed.
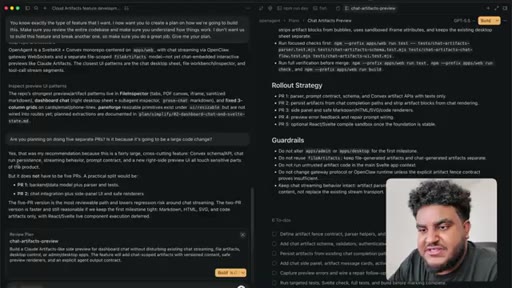
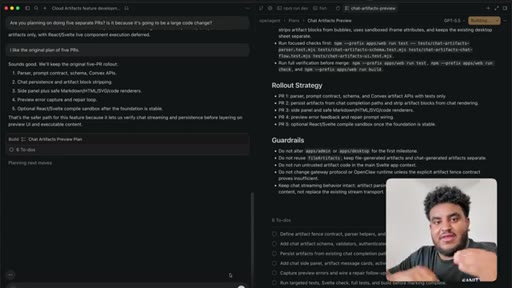
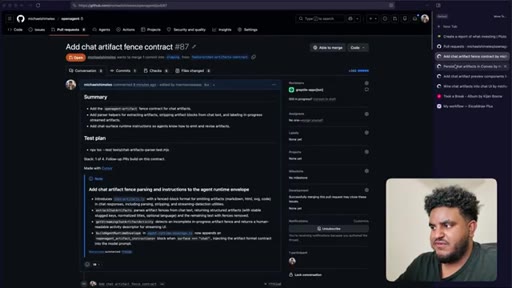
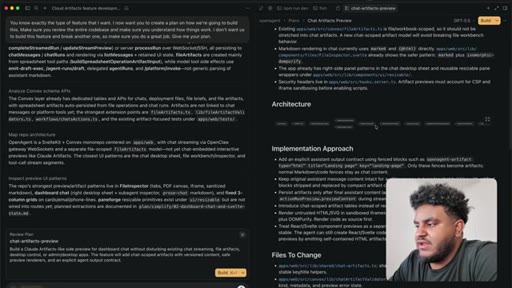
04 · Plan review + PR strategy
Five-PR rollout discussed and accepted. Red Dead Redemption interlude while agent cooks.

05 · Scrimba sponsor
Scrimba full-stack developer path sponsored segment.
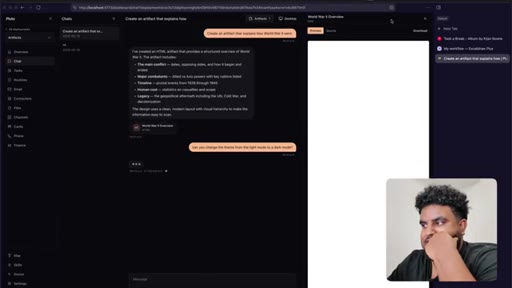
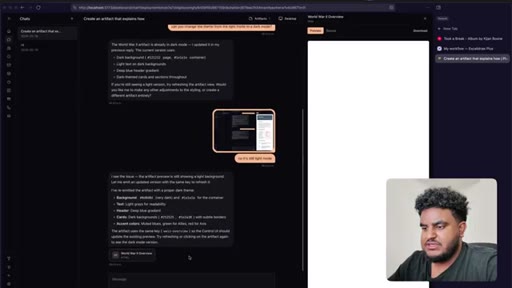
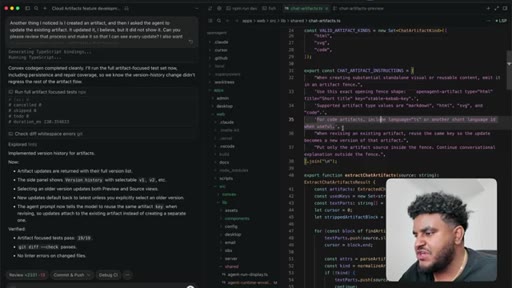
06 · First feature test
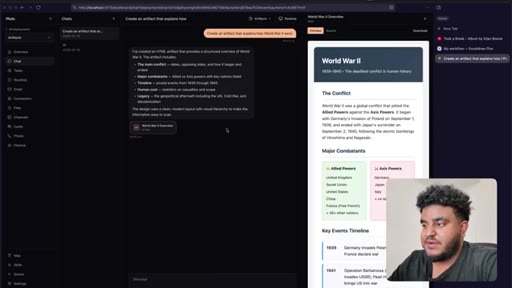
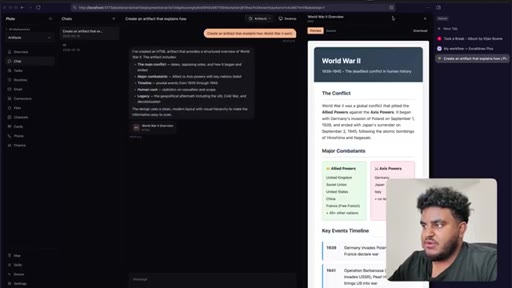
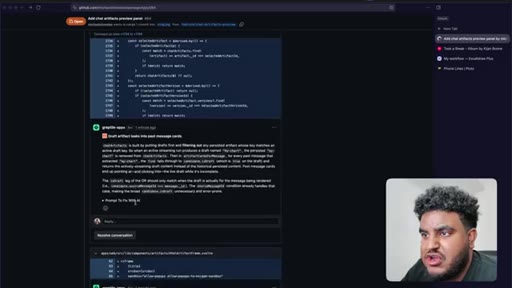
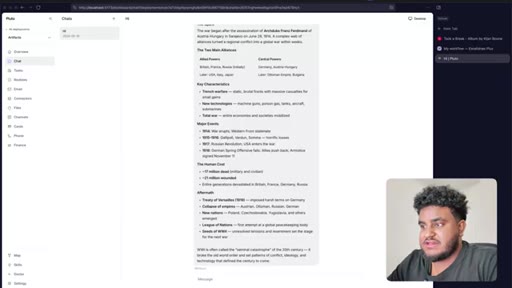
Agent finishes build. World War 2 artifact tested live — HTML preview renders in side panel. Bugs noted: streaming HTML visible, dark mode not updating.
07 · Iteration loop
Streaming suppressed (replaced with 'crafting artifact' animation), dark mode fixed, version history added, panel resize implemented. Feature declared working.
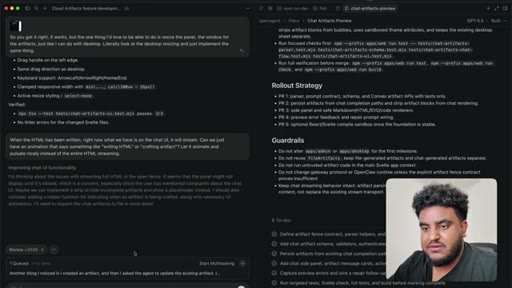
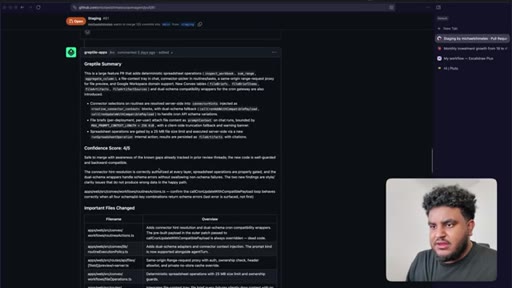
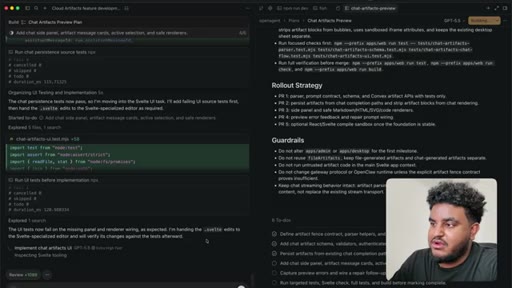
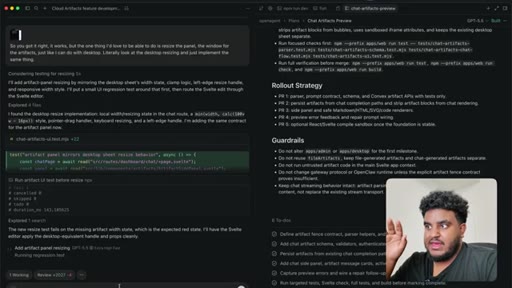
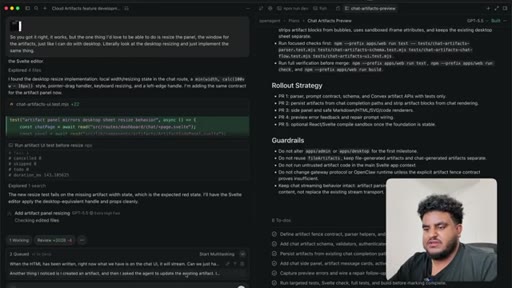
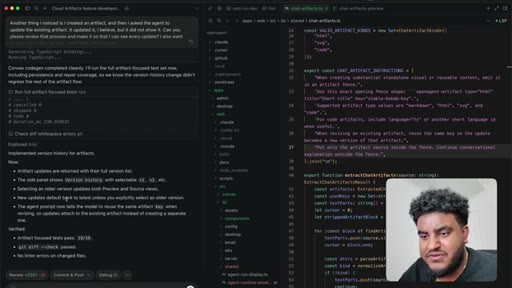
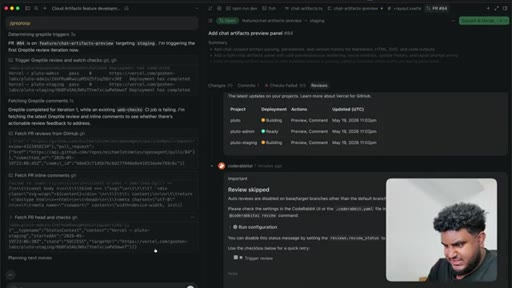
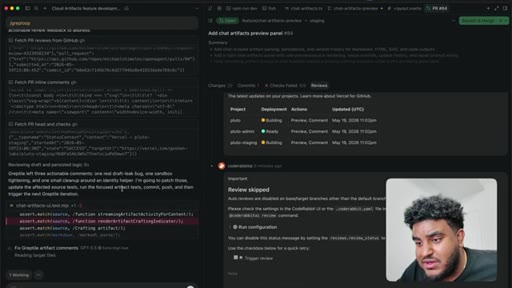
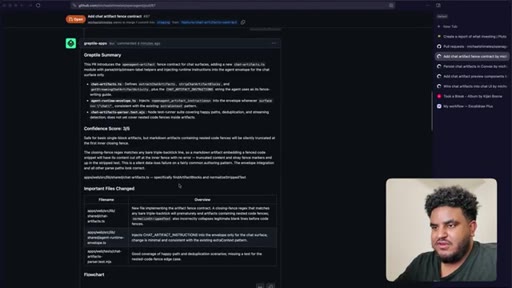
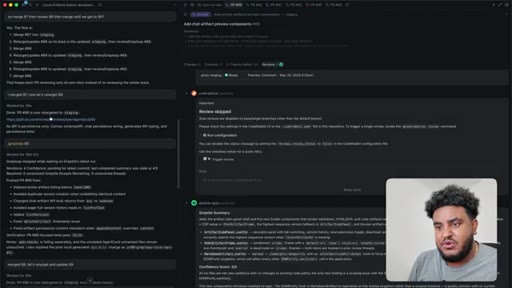
08 · PR to staging + Greptile review
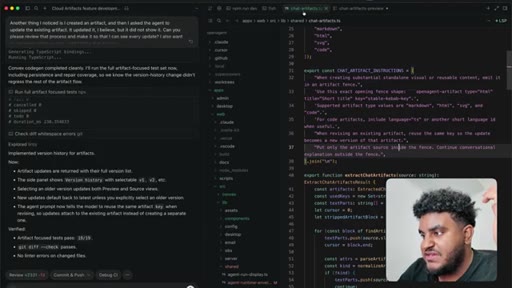
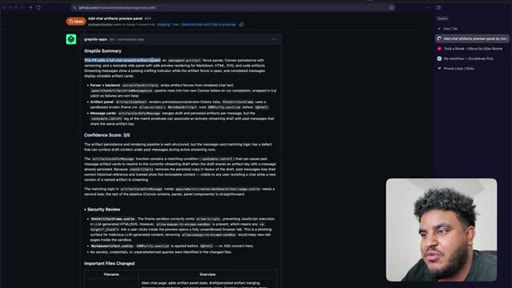
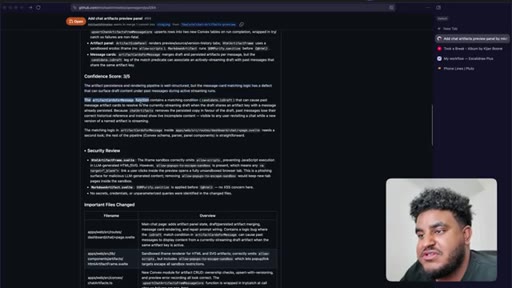
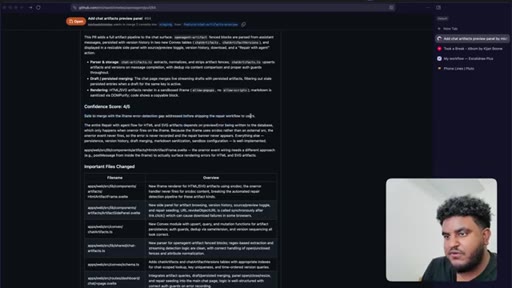
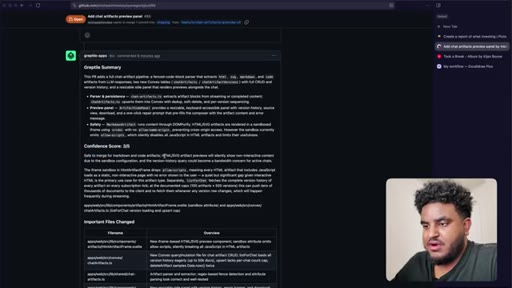
Agent pushes branch, opens PR to staging. 2,000 lines added. Greptile returns 3/5 — draft-content leak bug and security issues flagged.
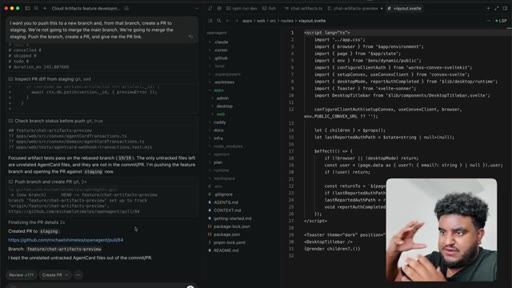
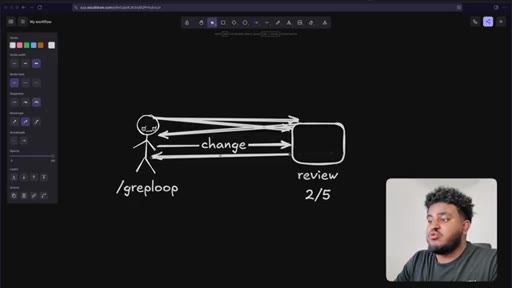
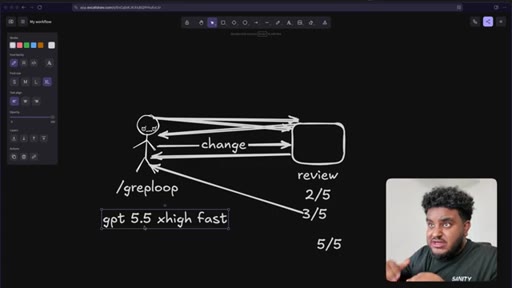
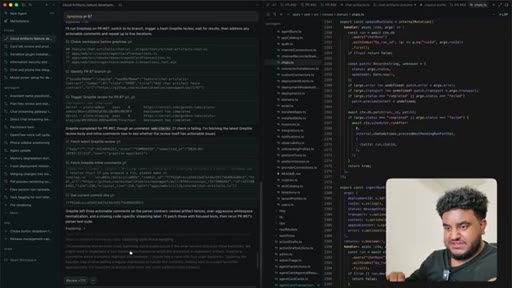
09 · /greploop cycle (3 to 4 to 3)
/greploop triggered. Score climbs to 4/5 then dips back to 3/5 as new issues surface. Decision point reached: PR is too large.
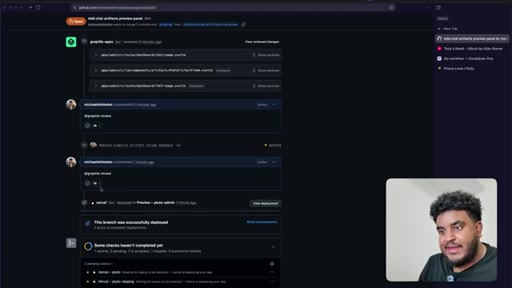
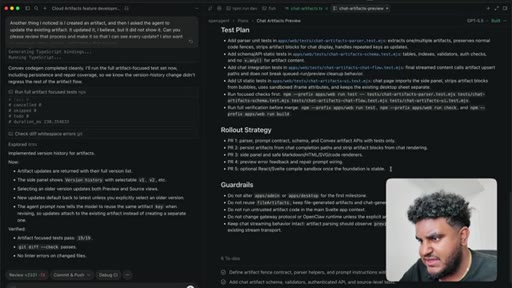
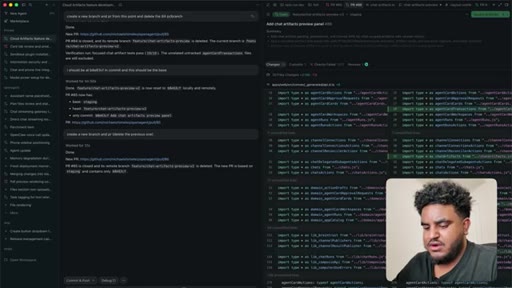
10 · Split into 4 stacked PRs
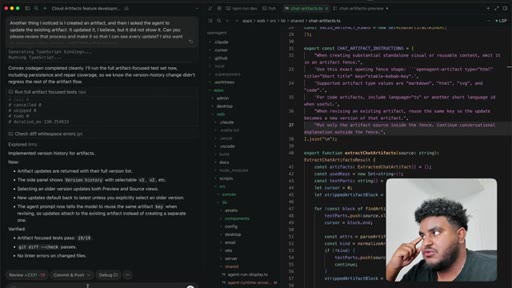
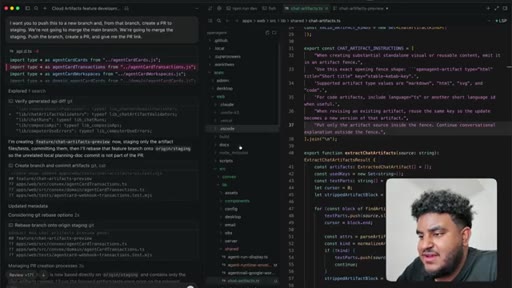
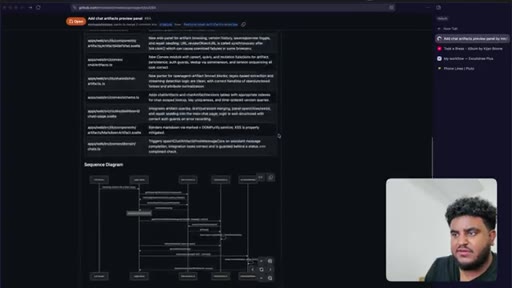
Author determines 2,000-line PR is too large for reliable review. Agent splits into four stacked PRs under 1,000 lines: fence contract, persistence, preview components, chat integration.
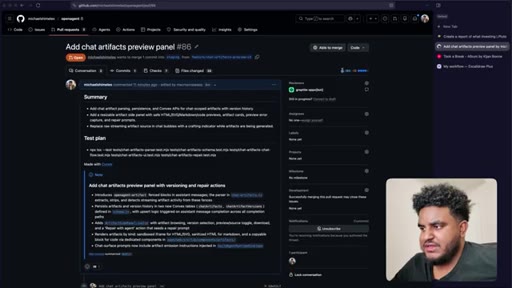
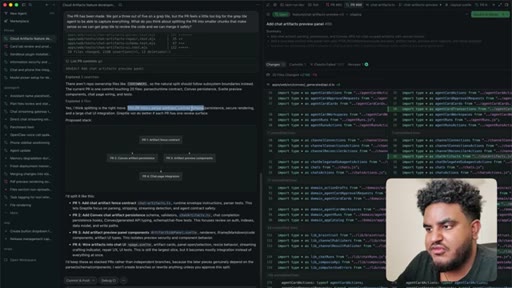
11 · Four PRs greploop'd to 5/5
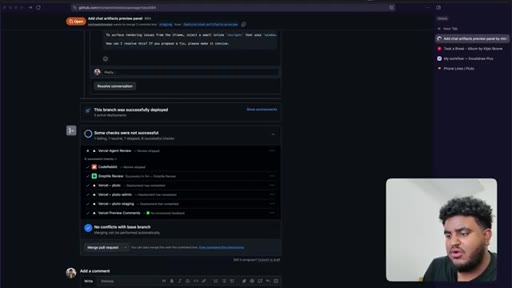
Each PR runs its own greploop. All four reach 5/5 and are merged to staging sequentially.
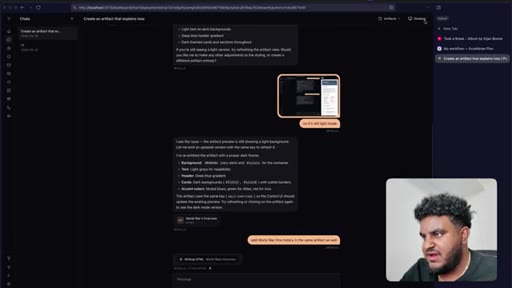
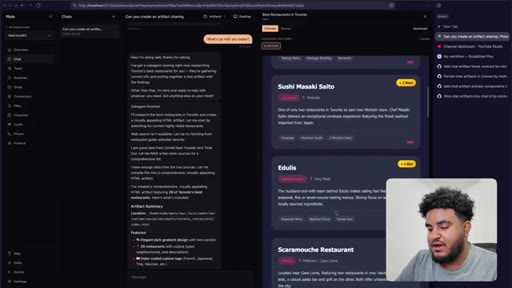
12 · Staging test + wrap-up
Final test: artifact for best restaurants in Toronto. Sub-agent spawned for research; main thread stays responsive. Feature ships. Workflow recap delivered.
Visual structure at a glance.

Named ideas worth stealing.
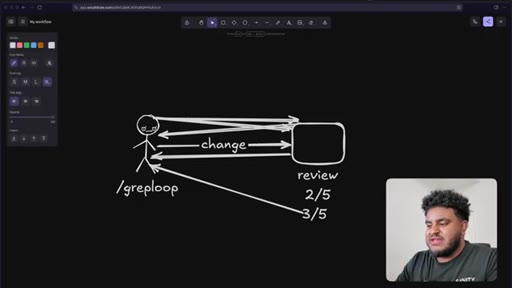
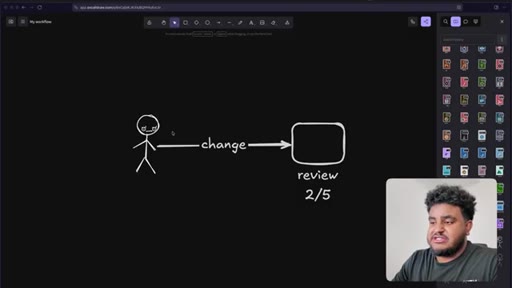
The Greploop Cycle
- Push change to PR
- Greptile reviews and scores
- If score < 5/5: agent reads comments, patches code, pushes
- Repeat up to 5 turns
- Merge when score >= 4/5 or stuck
An automated quality gate where the review tool and the coding agent form a closed loop, iterating on the same PR until a confidence threshold is met.
PR Size Rule
Keep individual PRs under roughly 1,000 lines so automated and human reviewers can cover the entire change. Split large features by concern: data model, parser, UI, integration.
Lines you could clip.
"It will keep going until it gets a five out of five."
"You don't want the agent to keep editing — it's gonna start hallucinating."
"I yap for a living. WhisperFlow just makes so much sense."
Things they pointed at.
How they asked for the click.
"Would really appreciate a like, a comment, and subscribe."
Soft ask at the very end after full value delivery. No mid-roll pitch other than the clearly labeled sponsor segment.
Word for word.
Close the loop between generation and review before merging.
The moment you treat code review as a manual step, agentic development stalls — the workflow that actually ships is one where the reviewer and the generator cycle automatically until a quality threshold is met.
- Automated review tools return a confidence score that acts as a ship or no-ship signal — treat anything below 4/5 as a reason to run another fix cycle, not a reason to merge and hope.
- PR size is a hard constraint on review quality: a 2,000-line diff causes automated reviewers to miss issues, while splitting by concern into sub-1,000-line PRs produces complete, actionable feedback.
- Voice prompting produces longer and more specific instructions than typing — the quality of the prompt is directly proportional to how much context the agent gets, and speaking removes the typing bottleneck.
- Capping an automated fix loop at five turns is a safety rule, not a quality threshold — past that point the agent begins introducing new issues rather than resolving the original ones.
- Sub-agents running on separate threads keep the main conversation responsive; the ability to continue prompting while a background task runs is a workflow multiplier, not a cosmetic feature.
- A build plan generated before starting serves the human more than the agent — it provides a re-entry document for multi-session work and a shared vocabulary for follow-up prompts.
- Service-layer code architecture makes agent context windows more efficient because the model can scope changes to a single module without reading the entire codebase.