The bait, then the rug-pull.
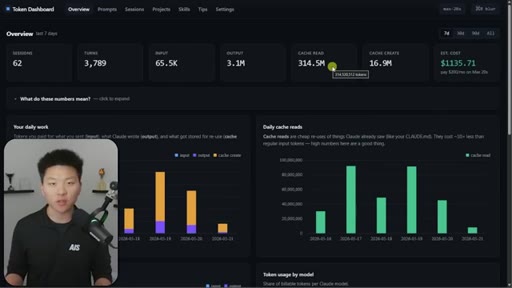
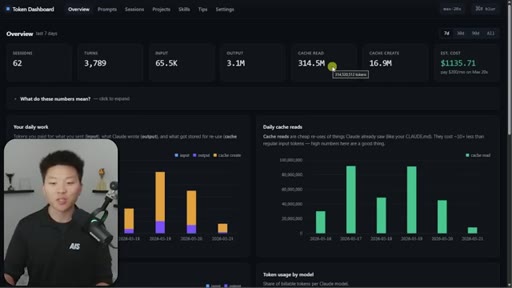
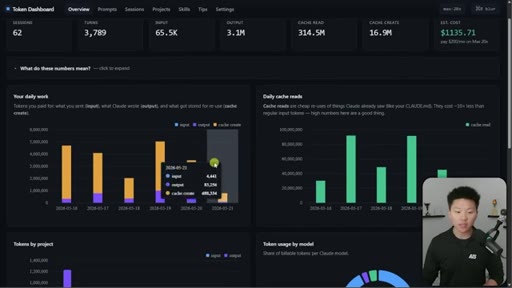
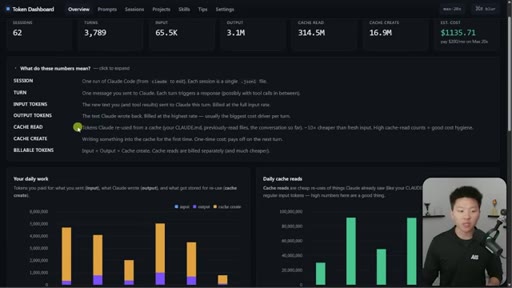
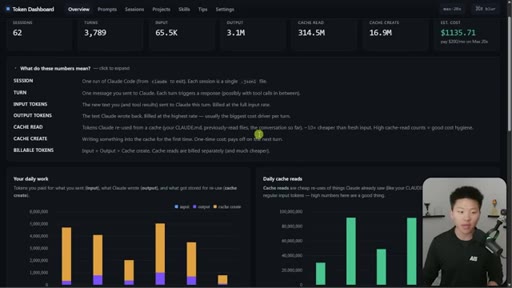
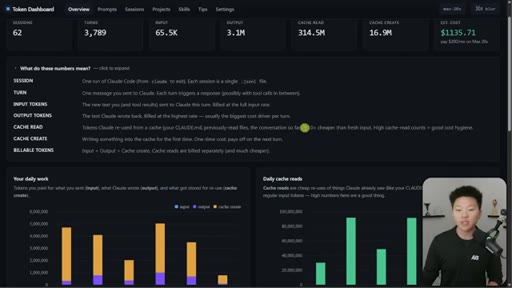
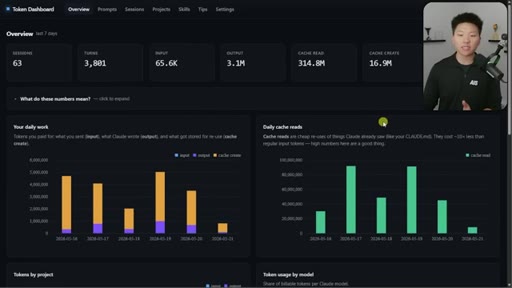
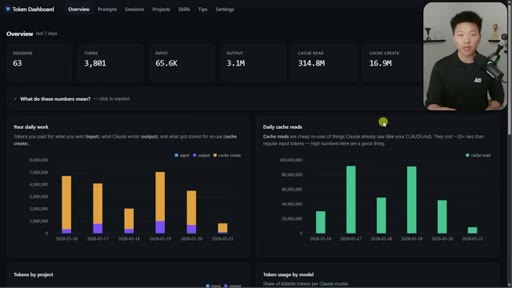
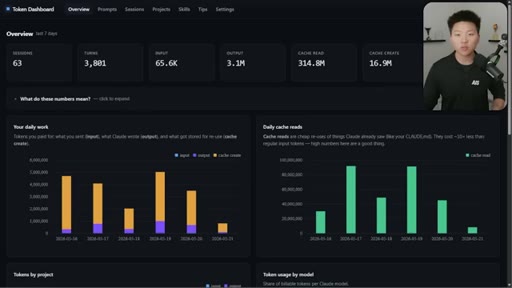
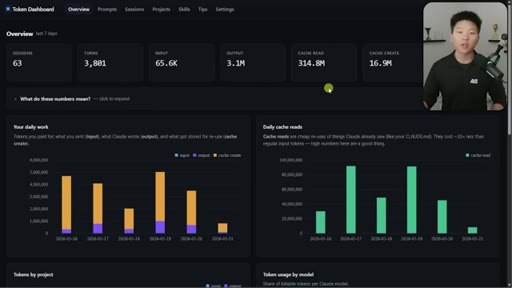
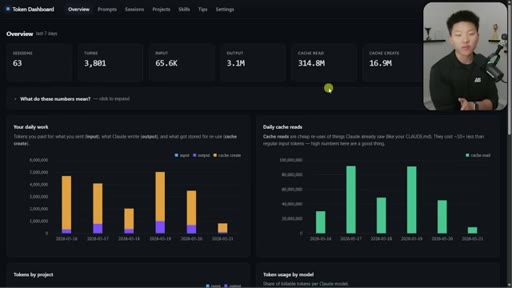
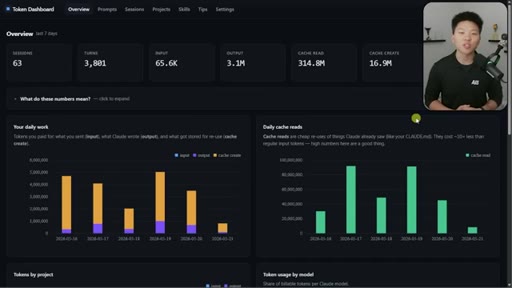
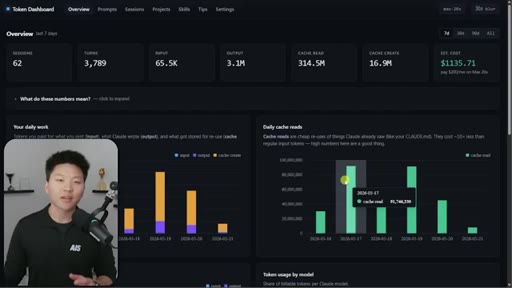
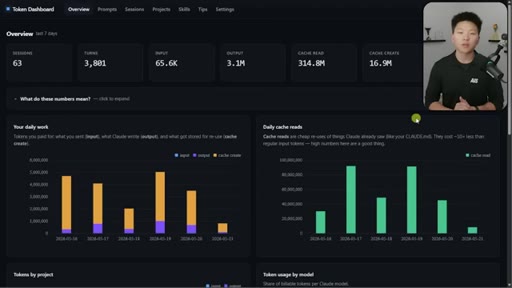
Nate Herk opens on a live token dashboard: 91 million tokens saved in a single day, 300 million in a week, all from prompt caching running silently in the background. The pitch is disarmingly simple: you do not have to change anything, but you do need to know the two or three things that can quietly blow it all up.
What the video promised.
stated at 00:18 "Im gonna make it as simple as possible and only really tell you what you need to know in order to make sure that you are saving your session limits and saving tokens." delivered at 06:12
Where the time goes.
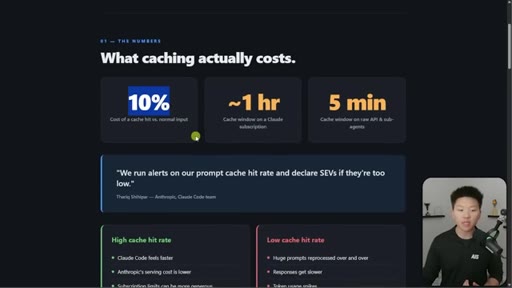
01 · What caching actually costs
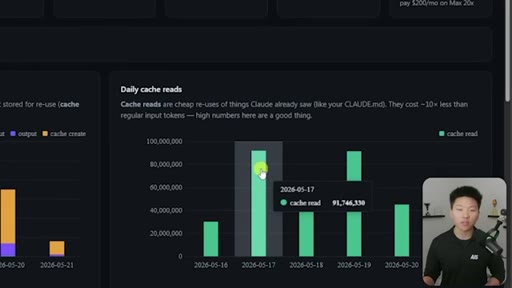
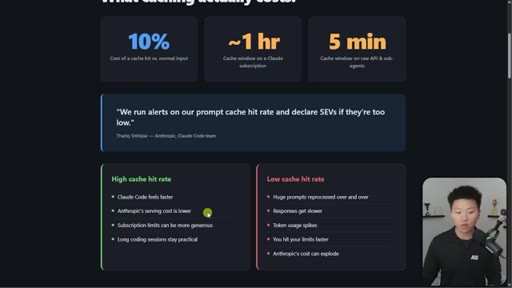
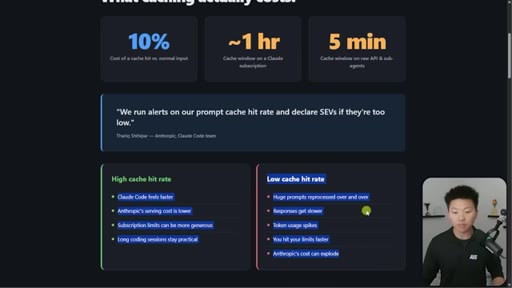
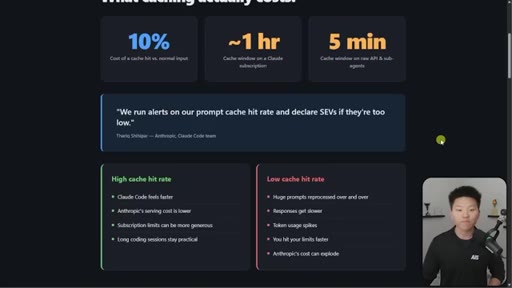
Hook on real dashboard numbers. 10% cost for cached tokens. 1hr TTL on subscription, 5min on API/sub-agents. Thoric/Anthropic quote on cache hit rate monitoring.

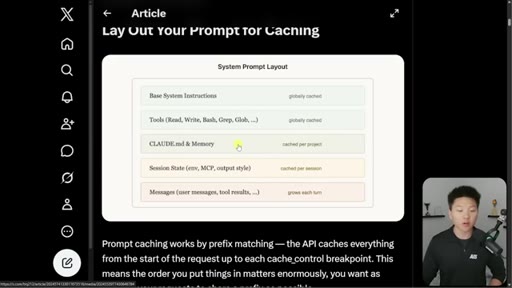
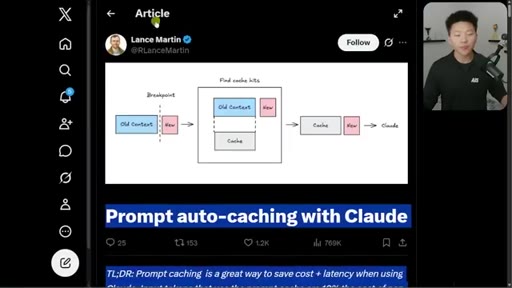
02 · How the cache grows per turn
System layer globally cached, Project layer per-project, Conversation layer grows every turn. Prefix-matching via Thoric diagram.
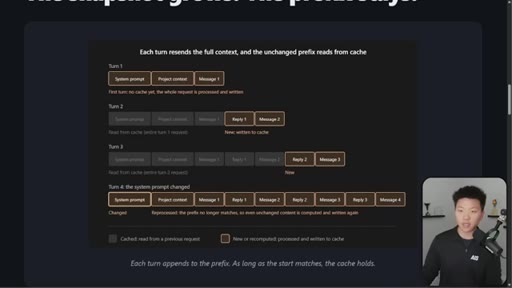
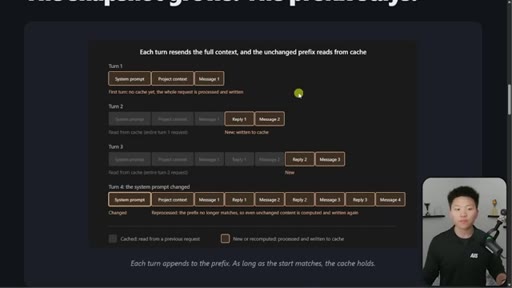
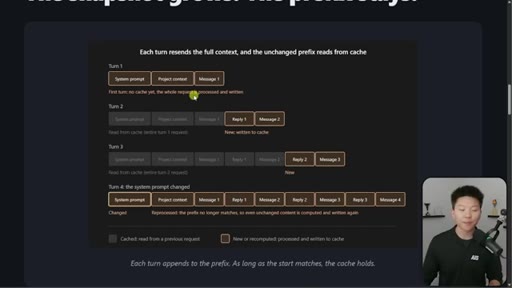
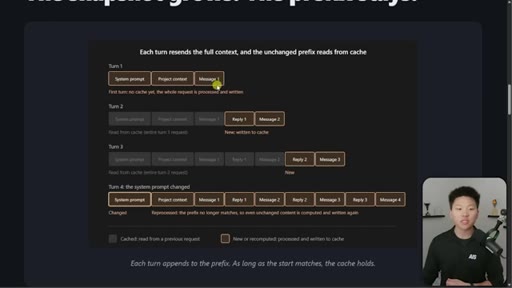
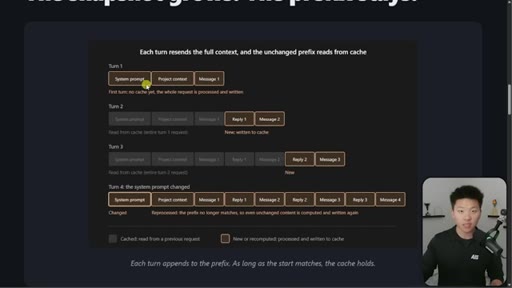
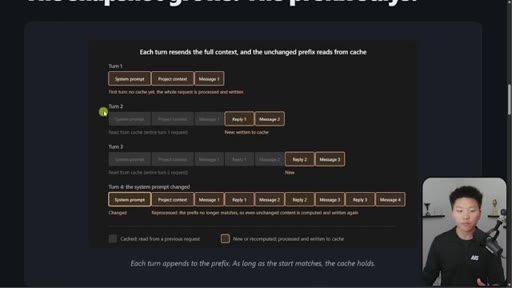
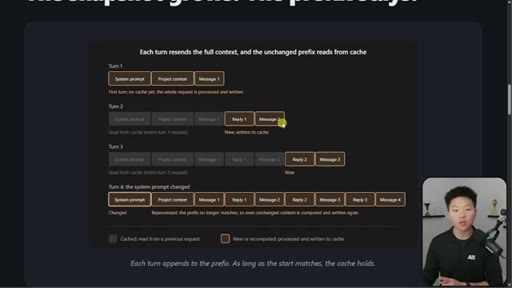
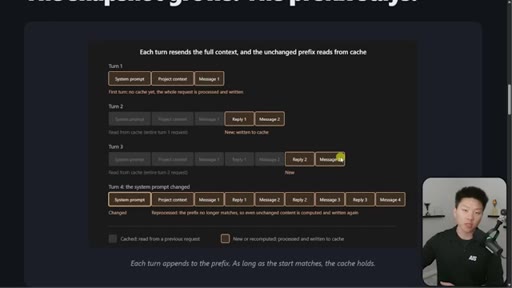
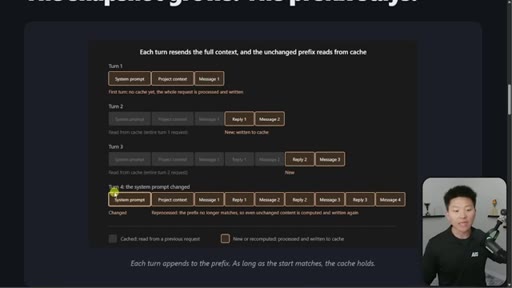
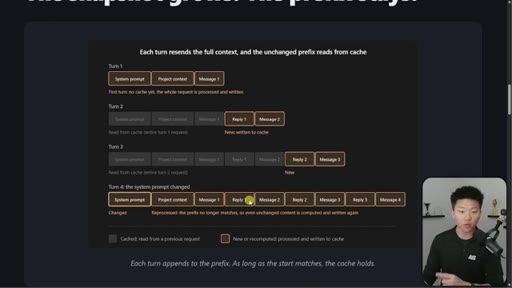
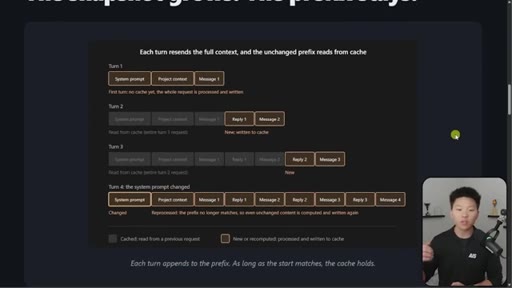
03 · The 4-turn visual example
Four-turn diagram showing what is cached vs processed fresh each turn. Danger: changing system prompt at message 16+ means full recache.
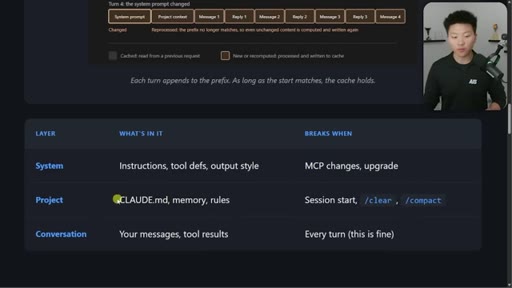
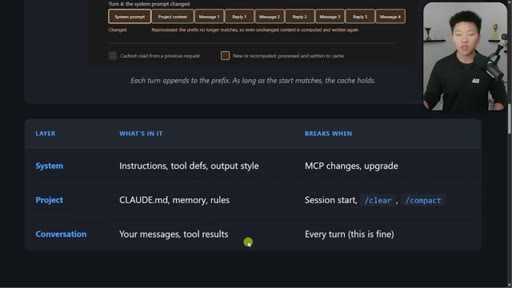
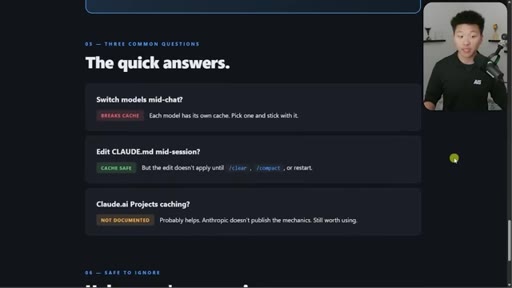
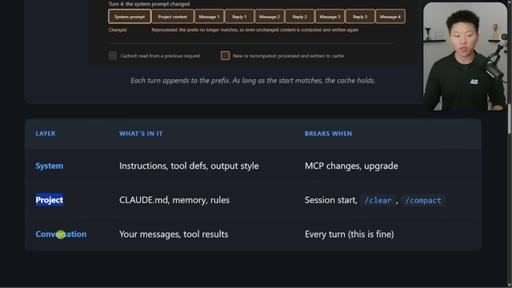
04 · Three layers and what breaks each
System / Project / Conversation table with exact events that bust each layer.
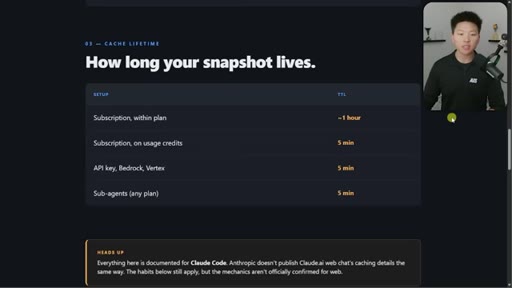
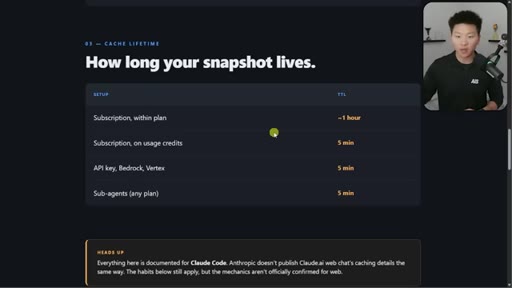
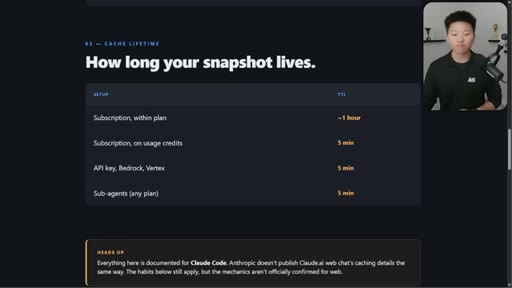
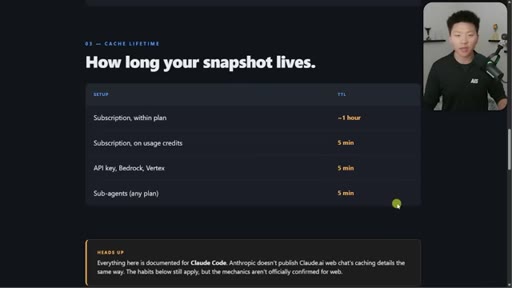
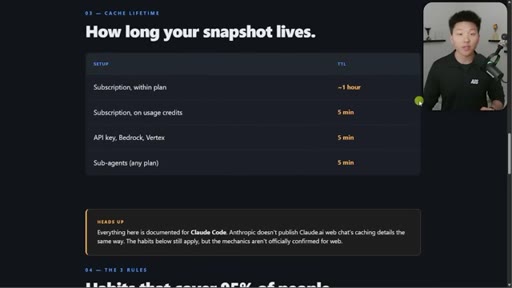
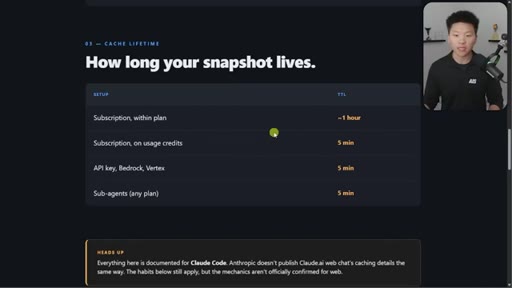
05 · Cache lifetime TTL table
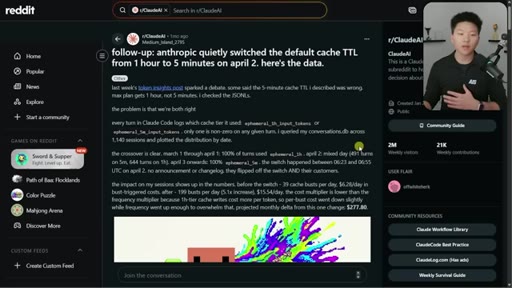
Subscription within plan ~1hr. On usage credits: 5min. API key: 5min. Sub-agents: 5min. Addresses April Reddit panic.
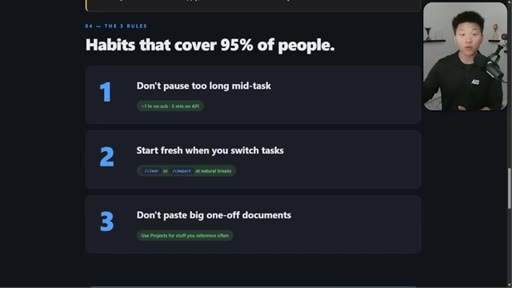
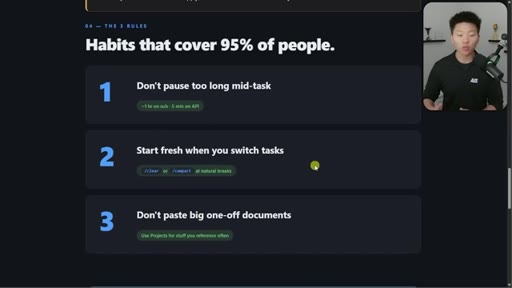
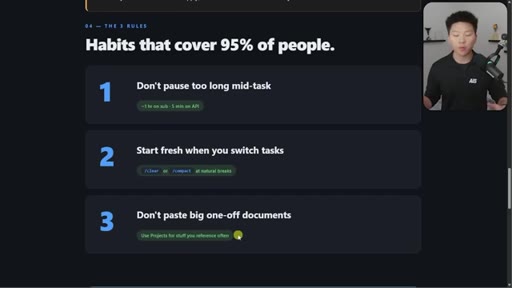
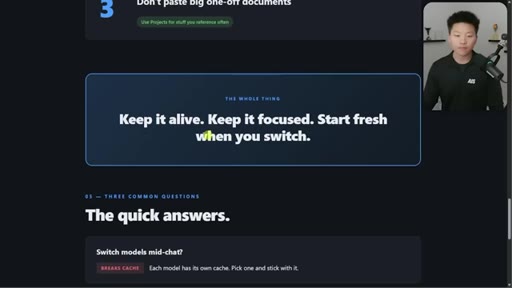
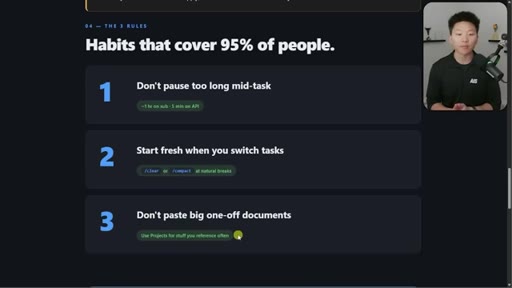
06 · Three habits that cover 95%
1. Do not pause too long. 2. Start fresh when you switch. 3. Do not paste big one-off docs. Demo of session-handoff skill.
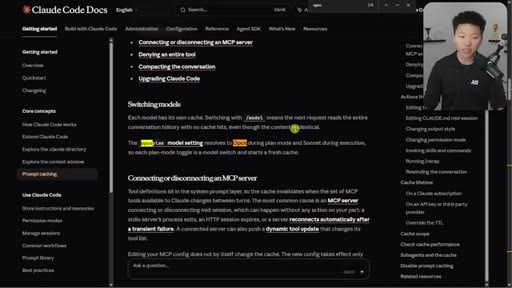
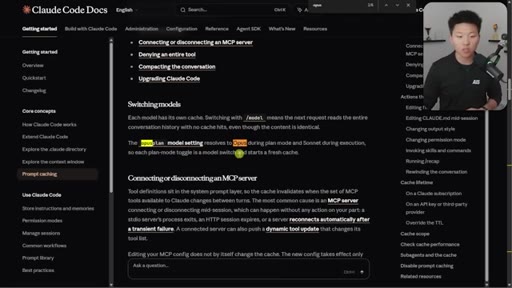
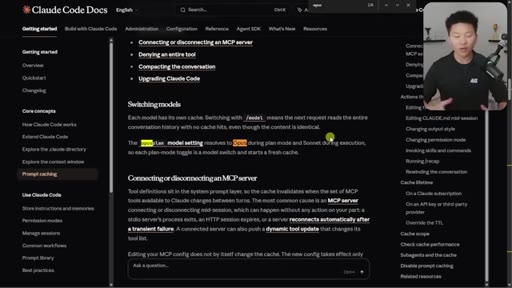
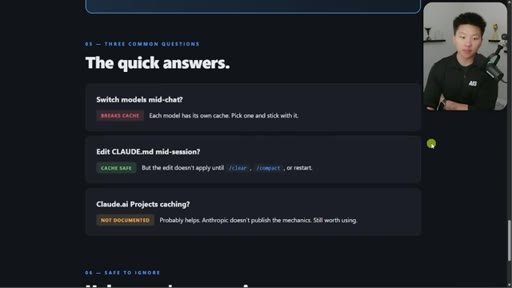
07 · What else breaks the cache
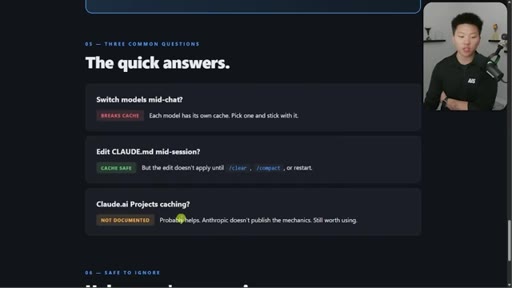
Model switching = full recache. Opus plan mode = cache-breaking on every plan/execute toggle. Editing CLAUDE.md mid-session is safe.
08 · Token dashboard and CTA
Free GitHub repo in School community. Tracks sessions/turns/tokens/cache reads/cost. Local device only. Setup via one Claude Code command.
Visual structure at a glance.

Named ideas worth stealing.
Three-Layer Cache Model
- System (globally cached)
- Project (cached per project)
- Conversation (grows each turn)
Every Claude Code session has three stacked layers with different caching rules.
Three Habits That Cover 95% of People
- Do not pause too long mid-task
- Start fresh when you switch tasks
- Do not paste big one-off documents
Opinionated 80/20 reduction of all caching complexity into three daily behaviors.
TTL Table by Setup
- Subscription within plan: ~1 hour
- Subscription on usage credits: 5 min
- API key / Bedrock / Vertex: 5 min
- Sub-agents any plan: 5 min
Definitive reference for how long a cache snapshot lives across different Claude access modes.
Lines you could clip.
"We run alerts on our prompt cache hit rate and declare SEVs if theyre too low."
"Keep it alive. Keep it focused. Start fresh when you switch."
"If you switch the model, you are recaching everything."
How they spent the runtime.
Things they pointed at.
How they asked for the click.
"You will go to my free School community. The link is in the description. Click on classroom, click on all YouTube resources."
Soft community CTA driven by giveaway perceived value. Two free tools bundled makes it feel like a package, not a pitch.
Word for word.
Teach one system, give away two tools.
Open on a real number that makes people eyes pop, frame the complexity as the 20% you actually need, then hand over two free tools that live in your community.
- Lead with your own dashboard showing real savings, not theory.
- Use the 80/20 framing explicitly: tell viewers you are skipping the parts they do not need.
- Give away two things not one: dashboard plus skill makes the CTA feel like a bundle.
- Build your explainer slides in the very tool you are teaching and say so on screen.
- End with a one-sentence mantra they can screenshot.
- The apology move (I taught this before and I was wrong) builds massive trust.
Three things you can do today to stop burning Claude tokens.
You are probably losing a significant chunk of your Claude subscription every week to preventable cache misses, and the fix takes about five minutes to learn.
- If you step away from Claude Code for more than an hour, start a new session when you return.
- When you finish one project and start something different, type /clear before beginning.
- If you paste the same long document into Claude Chat repeatedly, create a Claude Project and put the doc there instead.
- Do not switch between Claude models mid-session: pick Sonnet or Opus and stay with it.
- Editing your CLAUDE.md file mid-session is safe and will not break your cache until you restart.