The bait, then the rug-pull.
Jake Van Clief opens not with a question or a hot take, but with a credential drop that lands differently than most: a published methodology paper, 30,000 practitioners, and a community built entirely around folders and markdown files. The title does the provocation; the open does the credentialing. By the time he says they are not building multi-agentic frameworks, you already believe him.
What the video promised.
stated at 00:23 "What can you actually build using this methodology, and what happens when you bring in some traditional software programming into it?" delivered at 17:00
Where the time goes.

01 · The methodology and 30,000 builders
Cold open establishes ICM: folders plus markdown, not multi-agent frameworks. Community proof: 30,000 users, GitHub stars, published paper.

02 · Layer 1 — chat and copy-paste
The floor most people live on. Log in to ChatGPT or Claude, paste, copy out. Low effort, weak impact.
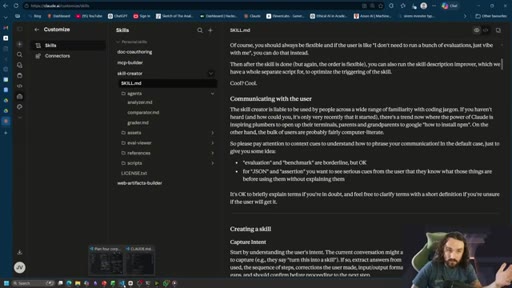
03 · Layer 2 — skills and refined prompts
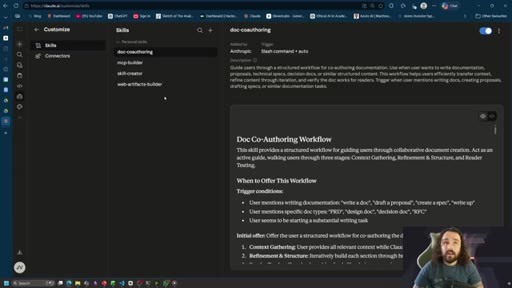
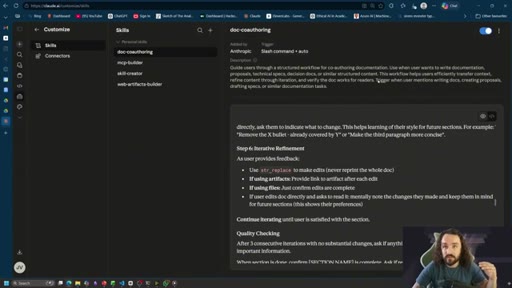
Someone packaged the L1 iteration work. Prompt libraries, chain-of-loop tools, auto-injection. Shows Claude Code skills browser.
04 · Layer 3 — folders and one agent
Skills evolve into folder structures the agent navigates on demand. No injection harnesses needed. Replaces LangChain/Semantic Kernel.
05 · The Anthropic/Karpathy connection
ICM is aligned with how frontier orgs actually build. Karpathy LLM wiki, Anthropic skill-based methodology — convergent, not contrarian.
06 · Why every workflow comes from dialogue
Dialogue contains goals, constraints, assumptions, and decisions. Kay's Divergen Assist tool extracts structured decision trees from any chat log.
07 · The NLP Logix content pipeline
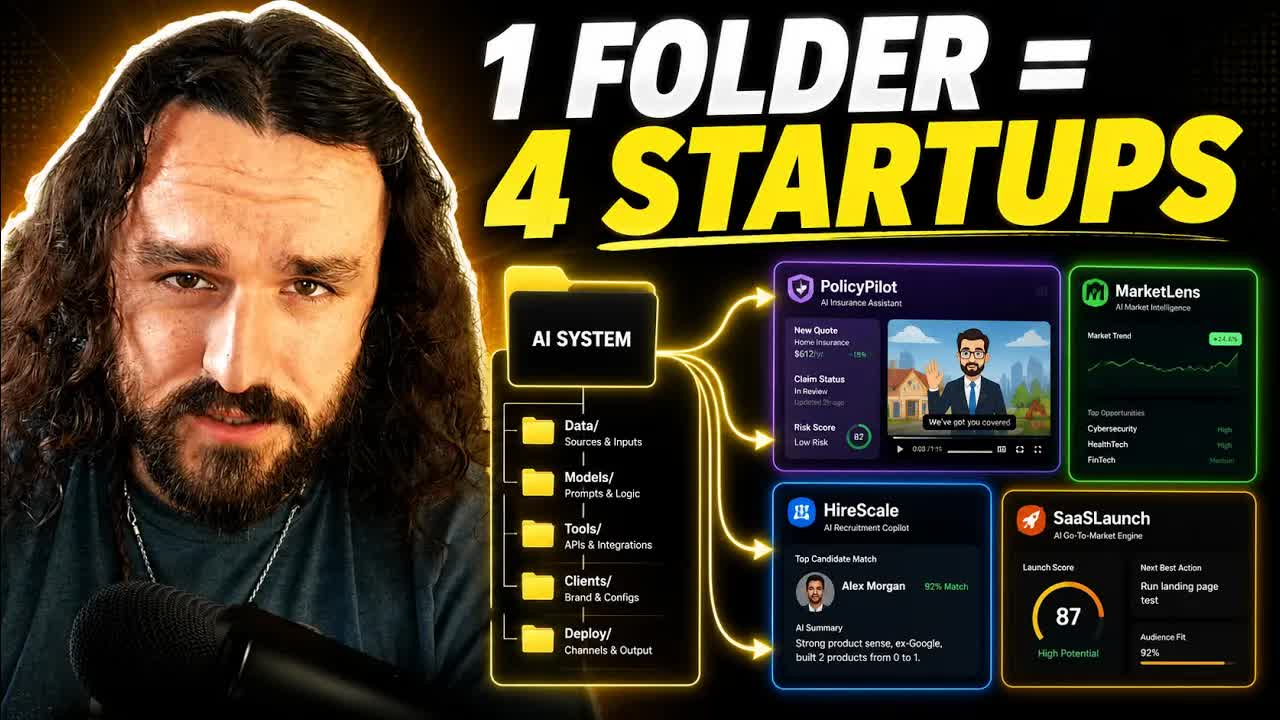
One folder, roughly 3 prompts: research to script to ElevenLabs audio to structured video animation. Claims this pipeline replaces 4-5 startups.
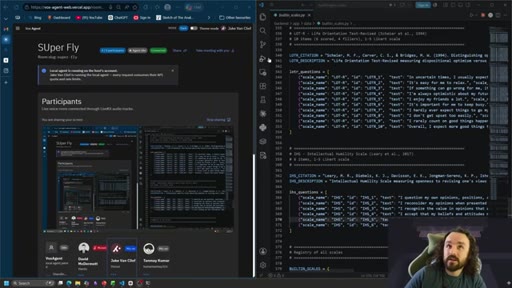
08 · Voice-controlled Claude Code in a meeting
Pre-recorded demo: Jake, David McDermott, Kay Kumar on SUPer Fly. Kay controls Jake's Claude Code by voice, adds Short Dark Triad scale to Ethics Engine. $1.20 for ~1 hour.
09 · Where this goes next
Meetings that fire structured workflows from keyword triggers. Actions before the meeting ends, delivered by agents. Teases open-source project.
Visual structure at a glance.
Named ideas worth stealing.
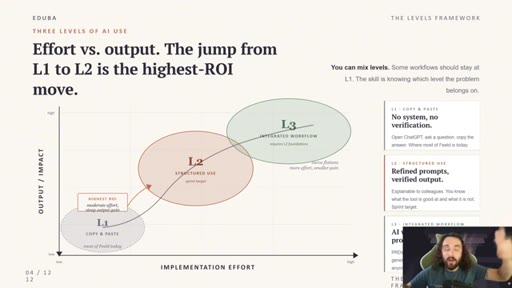
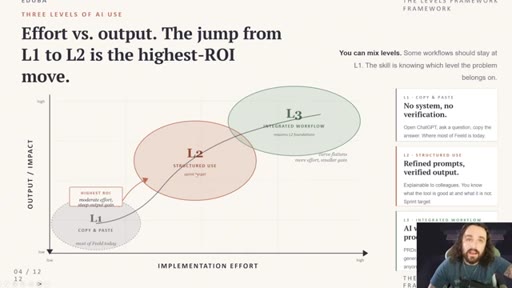
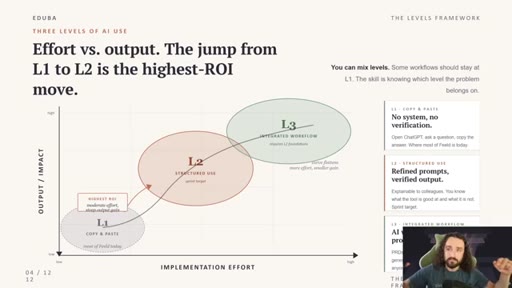
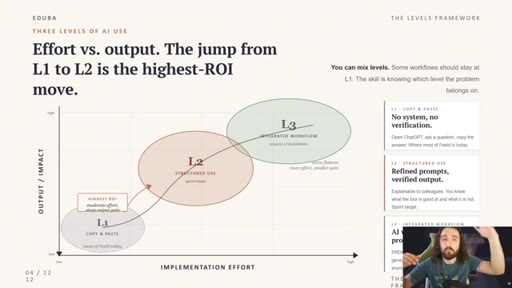
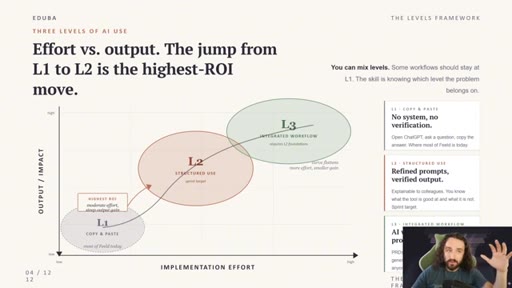
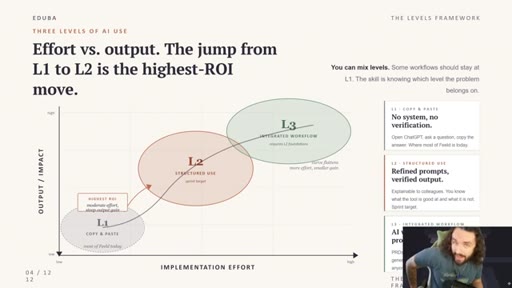
The Three Layers of AI Use
- L1 — Copy and Paste (chat, low effort, weak output)
- L2 — Structured Use (skills, prompt libraries, better output)
- L3 — Integrated Workflow (folders + one agent, highest output)
A tiered model for AI workflow maturity. Each layer is a step change in setup effort and output quality.
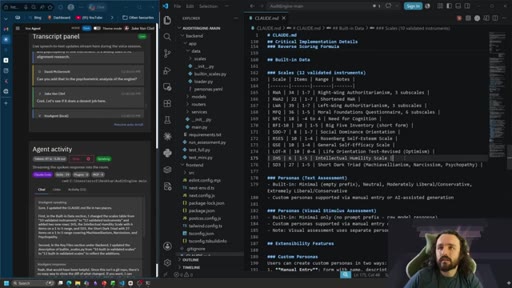
Interpretable Context Methodology (ICM)
Structure AI context through folders and markdown files rather than programmatic harnesses. The agent navigates structure on demand instead of having context injected at runtime.
Dialogue Decision Tree Extraction
Every AI chat contains extractable structure: goals, constraints, assumptions, processes. These become the markdown files that power L3 systems.
Lines you could clip.
"This entire workflow is probably four or five startups in the startup world right now, and it's all in folders and markdown files with one agent."
"Conversation has the structure we're looking for. The intent is carried in the conversation."
"Your team become the vendor."
"Instead of them being plans, they can be actions before the meeting is even done."
How they spent the runtime.
Things they pointed at.
How they asked for the click.
"If you are watching this as just a demo video for Vox... please go check out my larger thirty or forty minute video."
Soft, non-pushy. Dual CTA for two audience segments (Vox demo viewers vs YouTube subscribers). No subscribe ask, no sponsor. Clean close.
Word for word.
Stop building the harness. Build the folder.
The three-layer model is a portable positioning tool — and the $1.20/hour live demo is the proof-point format Joe should steal for every JoeFlow feature.
- The L1/L2/L3 model maps directly to Joe's stack philosophy: most people rent SaaS (L1/L2), ICM practitioners own structure (L3). JoeFlow plus the $6 Stack IS L3.
- The '$1.20 for an hour' proof point is the format to borrow: find the cheapest real demo of your wildest claim and put a dollar figure on screen.
- Dialogue extraction as a product angle: Joe's mod-watch pipeline already mines transcripts for structure — this could be positioned as Joe's own ICM for content creators.
- 'Four or five startups in one folder' is the MCN+ pitch in disguise — steal that framing for MCN+ positioning.
- Jake's dual-outro (one cut for Vox, one for YouTube) is worth borrowing: segment your CTA by audience arrival path, not just by platform.
- The no-sponsor, no-newsletter-pitch close is a deliberate CTA choice — worth noting for Joe's own long-form structure decisions.