The bait, then the rug-pull.
Claude Code default memory is losing information you cannot afford to lose. Simon Scrapes spent time digging through the most advanced open-source setups -- Hermes and MemSearch -- and found that the core ideas underneath all the complexity are actually simple. This is the teardown that shows you exactly what is missing and how to fix it.
What the video promised.
stated at 00:35 "I am gonna show you what Claude Code memory looks like today, what the newest systems are actually doing differently, and then the setup I would actually recommend if you want Claude Code to stop forgetting things." delivered at 19:04
Where the time goes.

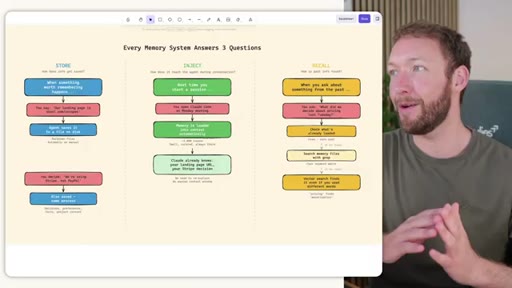
01 · Cold Open -- 3 Questions Every Memory System Must Answer
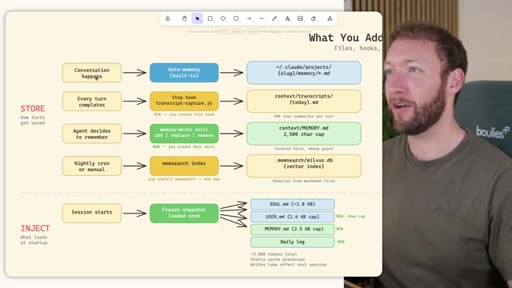
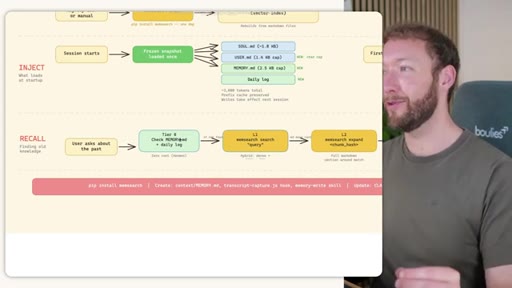
Frames the whole video around Store, Inject, and Recall. Introduces MemSearch and Hermes as the two strongest open-source challengers. Sets expectation: this is not about more context -- it is about the right context.
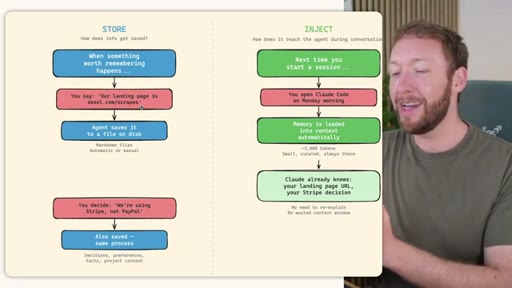
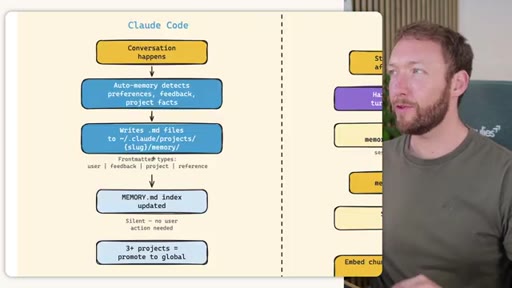
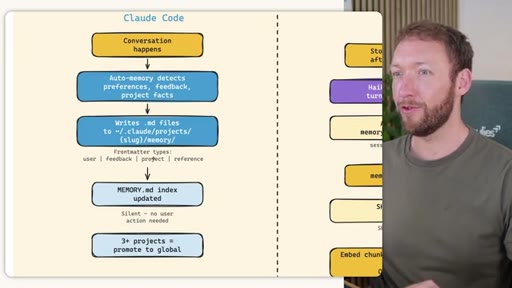
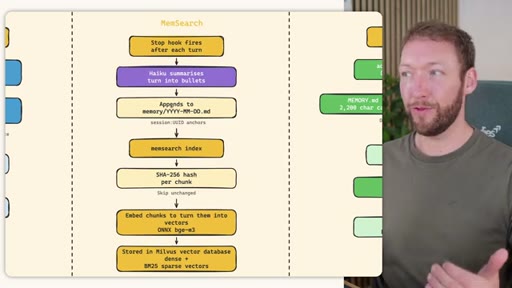
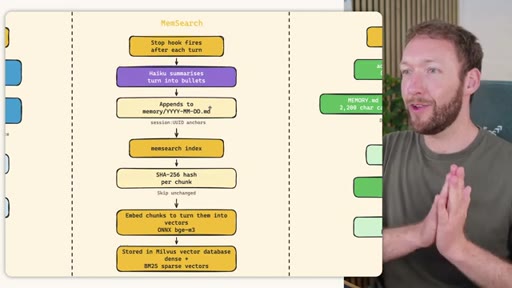
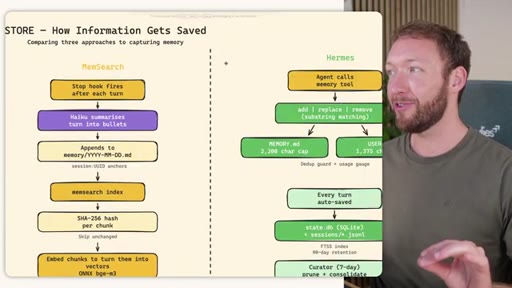
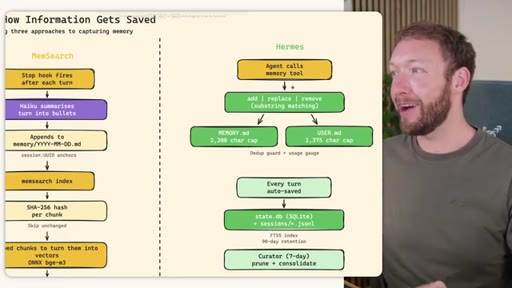
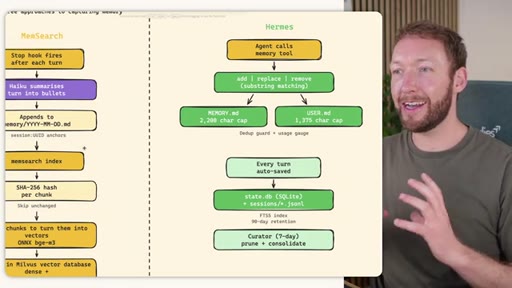
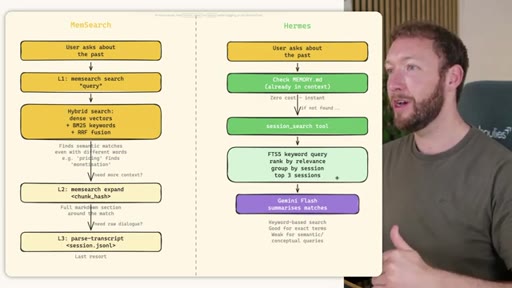
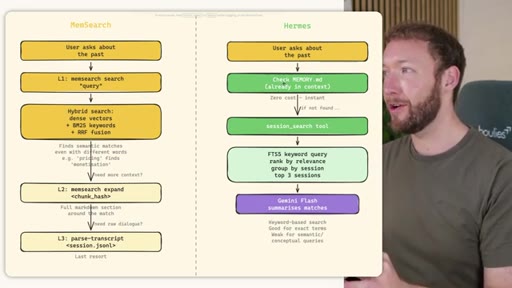
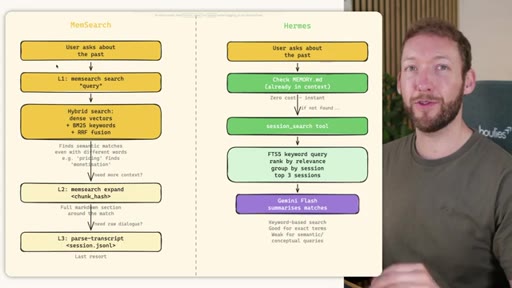
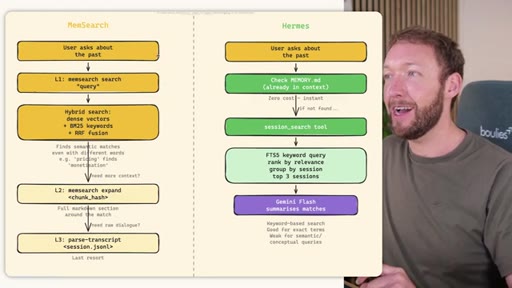
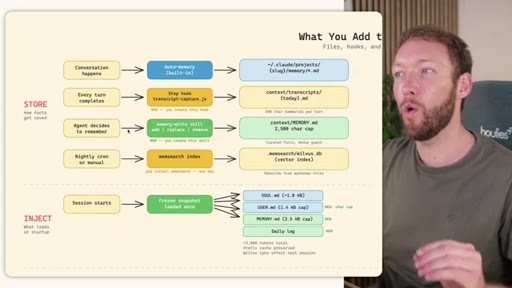
02 · STORE -- How the Three Systems Capture Information
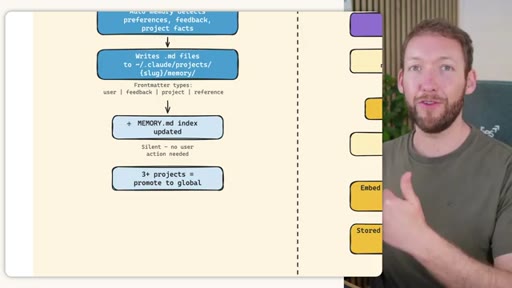
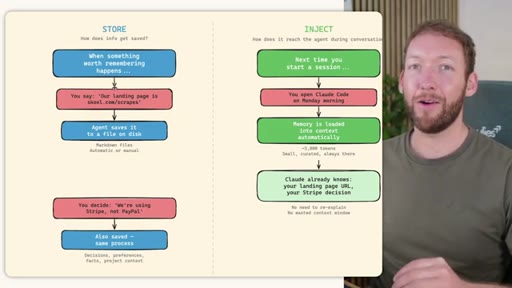
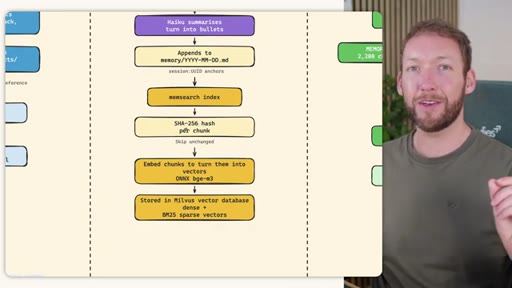
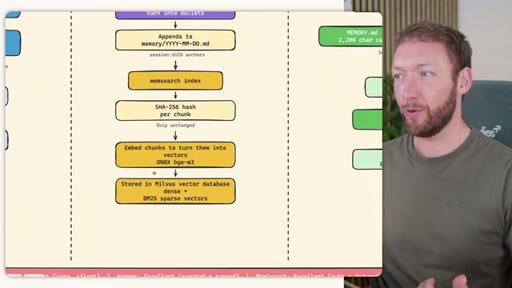
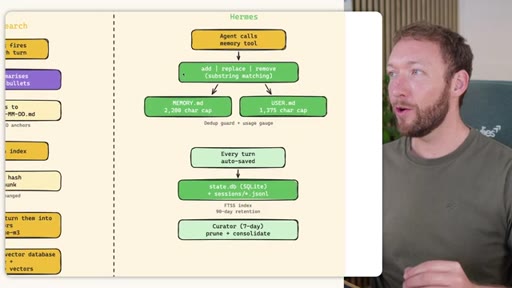
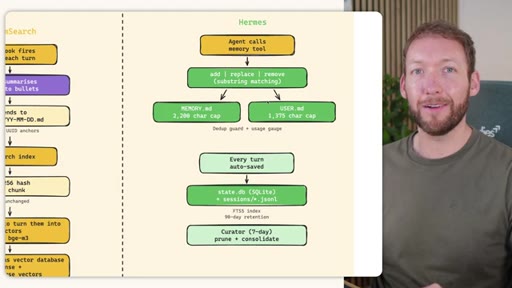
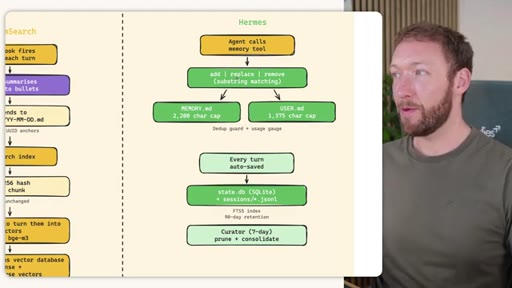
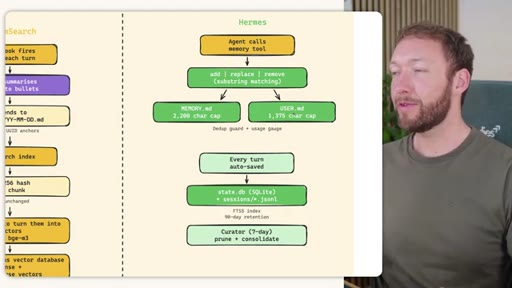
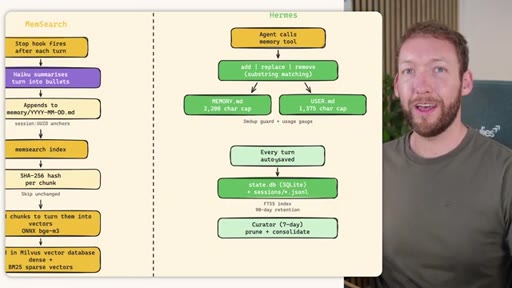
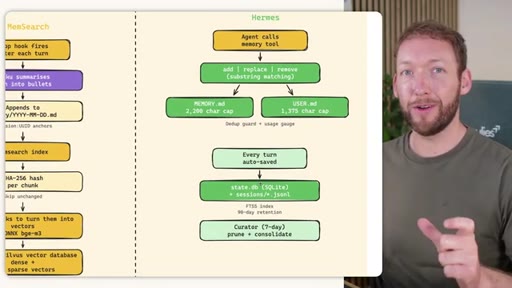
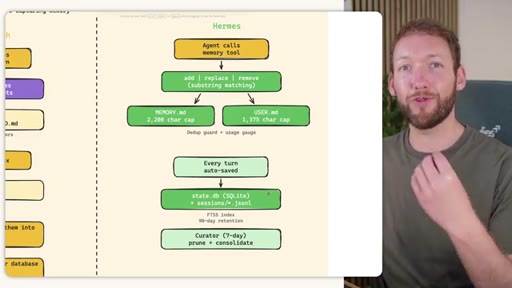
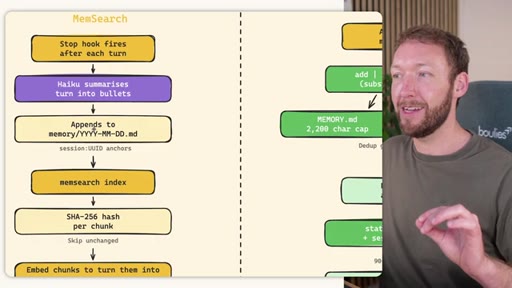
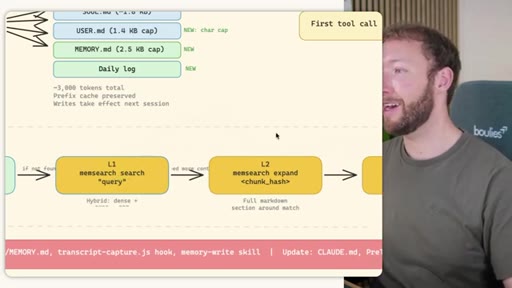
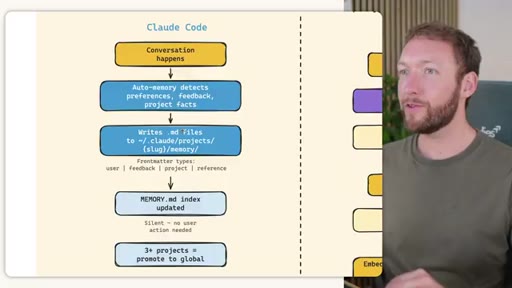
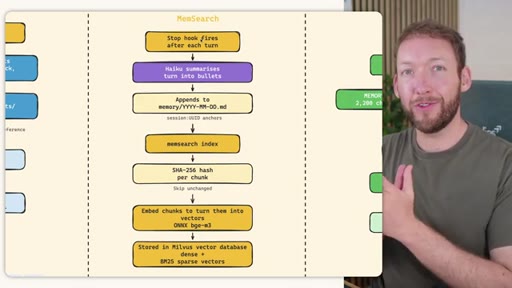
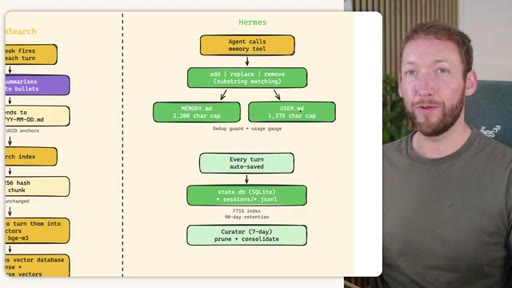
Side-by-side comparison. Claude Code: auto-memory, sparse, promotes to global after 3+ repeats. MemSearch: stop hook after every turn, Haiku bullets, Milvus vector DB (local CPU, zero cost). Hermes: agent-driven add/replace/remove, MEMORY.md (2200 char) + USER.md (3375 char) + SQLite raw transcript + 7-day curator.

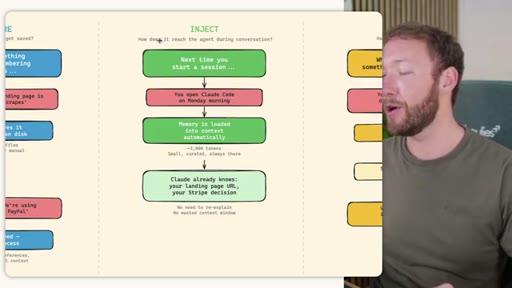
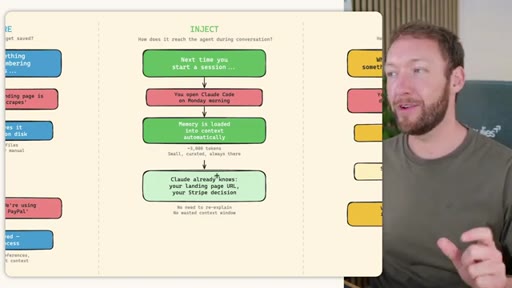
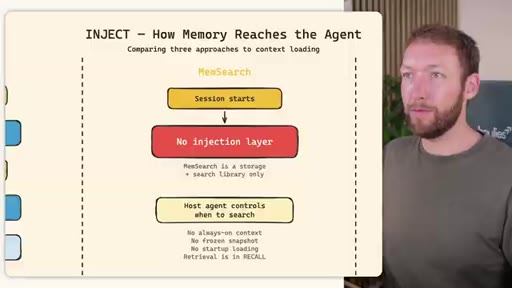
03 · INJECT -- How Memory Reaches the Agent at Session Start
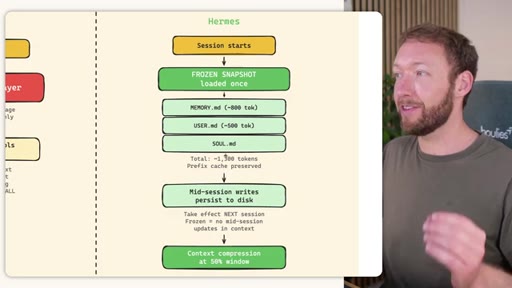
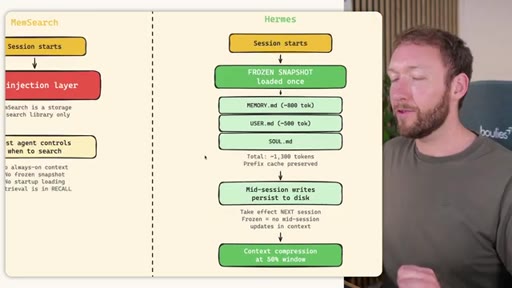
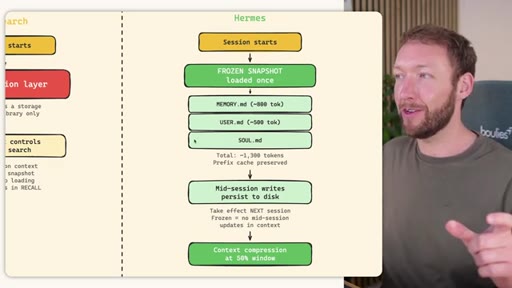
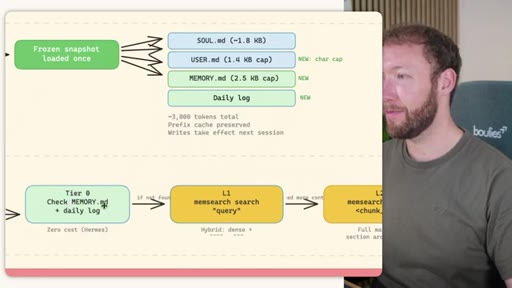
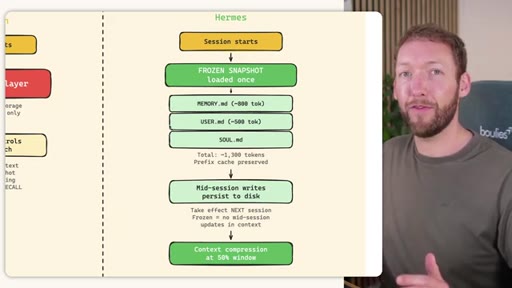
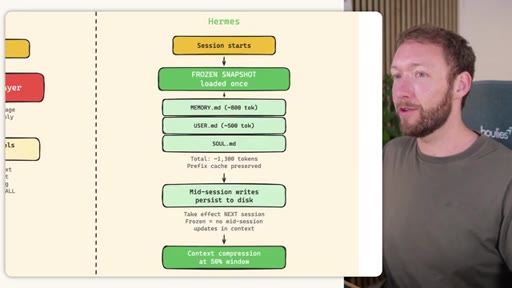
Claude Code loads CLAUDE.md + conditional memory file injection via pre-tool-use hook. MemSearch has NO injection layer. Hermes loads a frozen snapshot of SOUL.md + USER.md + MEMORY.md (~1300 tokens, prefix-cached) once per session.
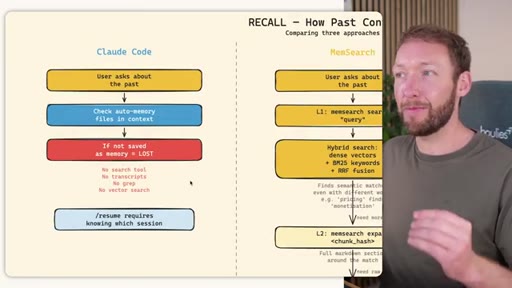
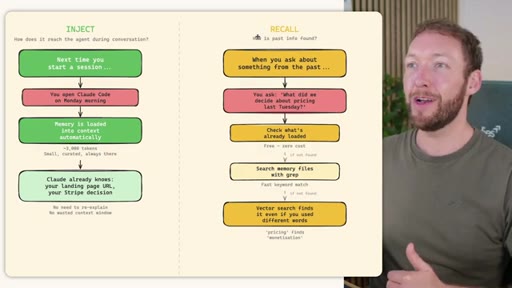
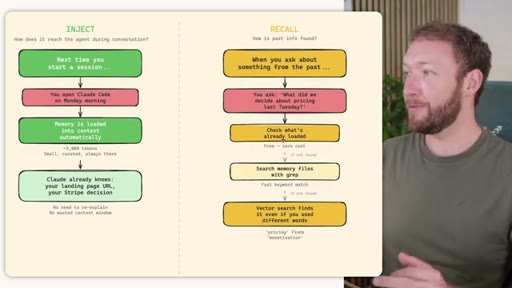
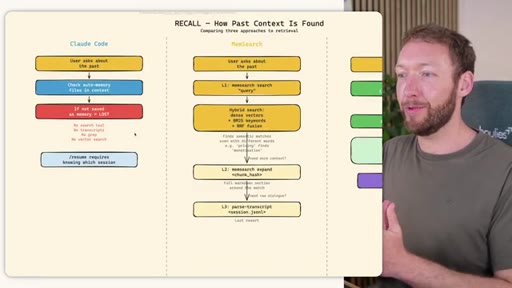
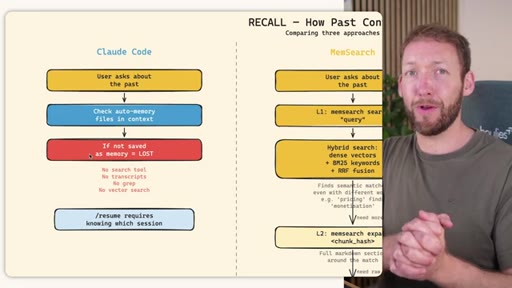
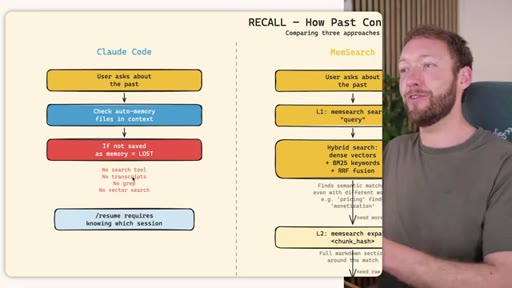
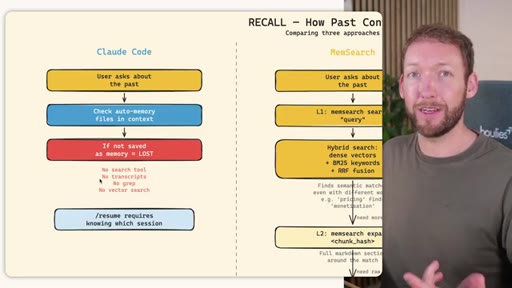
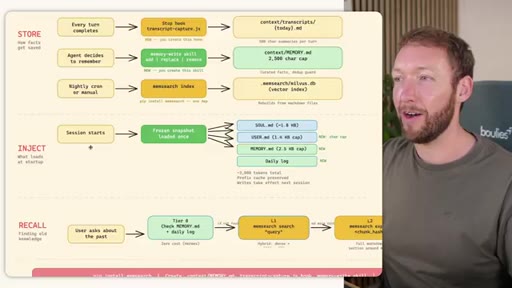
04 · RECALL -- How the Agent Retrieves Past Information
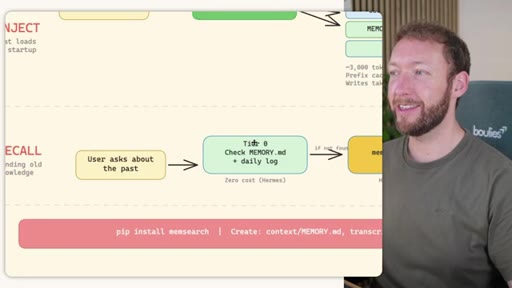
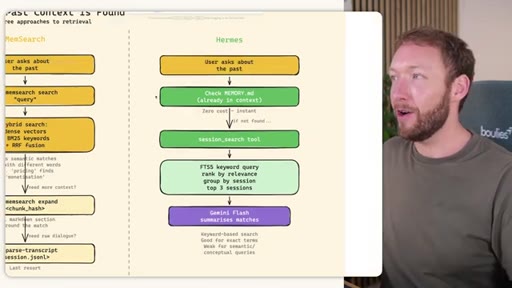
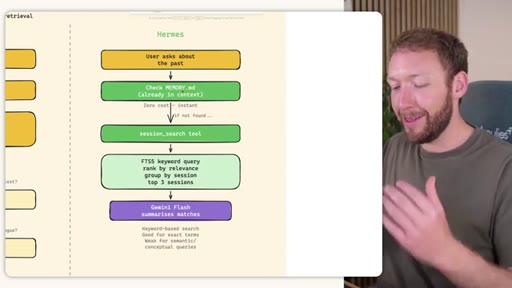
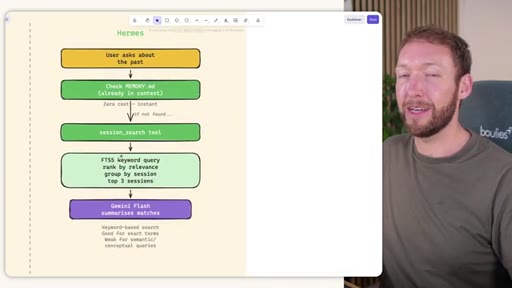
Claude Code: checks auto-memory files, if not saved it is lost -- no search, no grep, no vectors. MemSearch: 3-tier retrieval (L1 hybrid vector+keyword search, L2 expand chunk context, L3 raw session transcript). Hermes: Tier-0 in-context MEMORY.md check, FTSS keyword query, Gemini Flash summarisation of top 3 sessions.

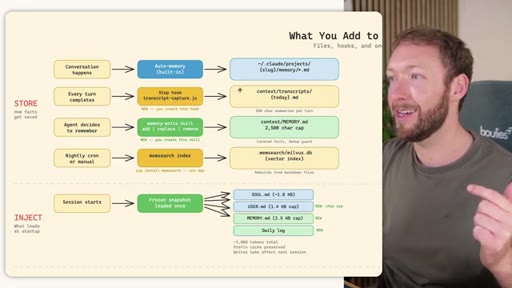
05 · Recommended Hybrid Setup -- Taking the Best of All Three
Store: auto-memory + MemSearch stop hook + agent writes MEMORY.md/USER.md + nightly memsearch index cron. Inject: Hermes frozen snapshot (~3000 tokens cached). Recall: Tier-0 in-context, L1 MemSearch hybrid, L2 expand, L3 raw transcript. Free plan.md available.
Visual structure at a glance.

Named ideas worth stealing.
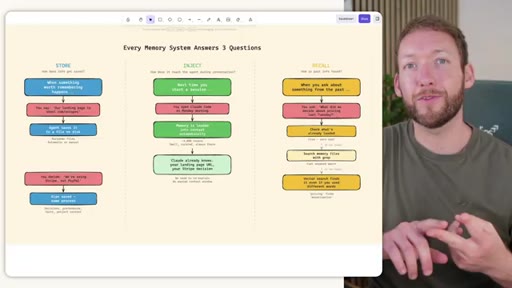
Store / Inject / Recall
- Store -- how does info get written to memory?
- Inject -- how does it reach the agent during a session?
- Recall -- how does the agent find old info when asked?
Three-question framework for evaluating any agentic memory system. Every decision about memory architecture maps to one of these three verbs.
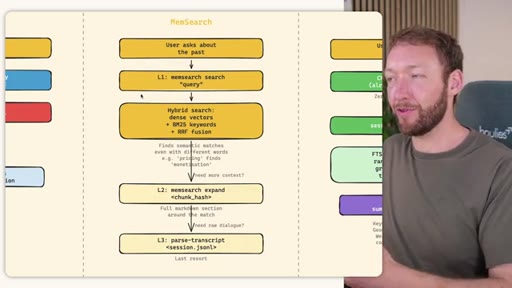
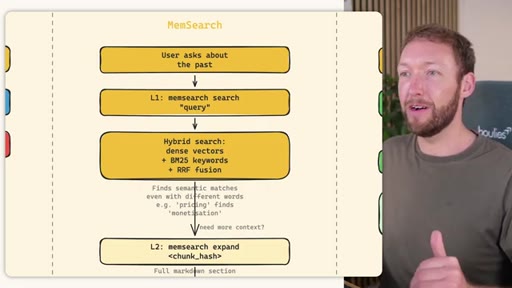
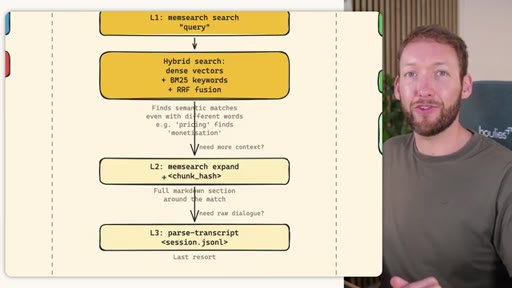
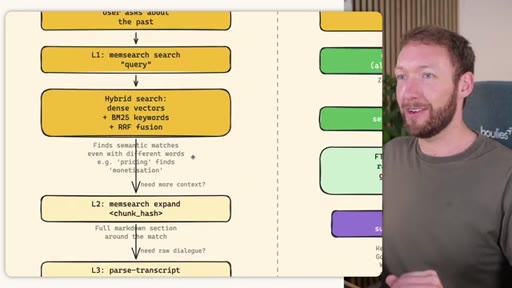
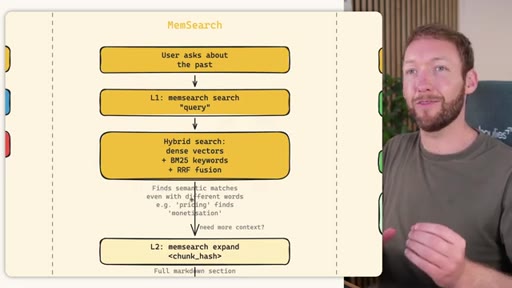
MemSearch 3-Tier Retrieval
- L1: memsearch search -- hybrid dense vectors + BM25 keywords + RRF fusion
- L2: memsearch expand chunk_hash -- full markdown section around match
- L3: parse-transcript session.json -- raw dialogue as last resort
Progressive disclosure retrieval: only go deeper when needed. Semantic search means pricing finds monetization without exact keyword match.
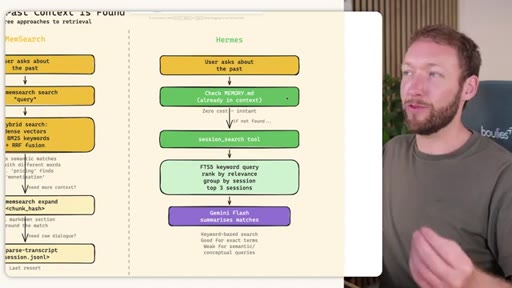
Hermes Frozen Snapshot Injection
- SOUL.md (~1.8 kB) -- agent identity / operating principles
- USER.md (1.4 kB cap) -- user profile, preferences, working style
- MEMORY.md (2.5 kB cap) -- curated project facts, decisions, context
- Daily log -- optional, today session context
~3000 tokens loaded once at session start, prefix-cached. Mid-session writes persist to disk but take effect NEXT session (frozen snapshot principle).
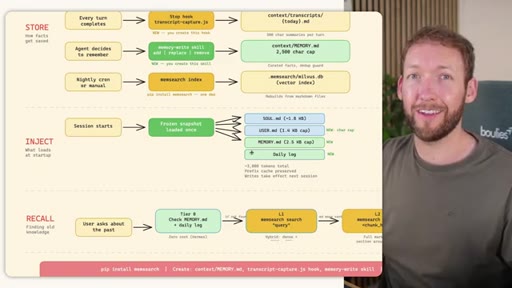
Hybrid Memory Architecture
- STORE: auto-memory + MemSearch stop hook + agent MEMORY.md/USER.md writes + nightly cron index
- INJECT: Hermes frozen snapshot (~3000 tokens cached per session)
- RECALL: Tier-0 in-context, L1 MemSearch hybrid, L2 expand, L3 raw
Combines completeness (MemSearch captures everything) with quality (Hermes curates what matters most) and speed (in-context check before any DB query).
Lines you could clip.
"It is not about loading more context in. It is about loading the right context at the right time only."
"If you can store as much information as you want, but if you cannot get it out at the right time, then it is not worth having a good storage mechanism in the first place."
"MemSearch and Hermes go 10 x further than the basic claw code out the box."
"Right now it is far, far behind what you can get from systems that are currently open source and free to access."
How they spent the runtime.
Things they pointed at.
How they asked for the click.
"I will link below a completely free plan.md document for you to pass into Claude and set it up for yourself."
Soft lead-in referencing the paid agentic OS, then free plan.md as the accessible on-ramp. Clean two-tier CTA: free DIY vs done-for-you community.
Word for word.
Steal the three-verb framework.
Every memory decision in any agent system maps to just three questions: Store, Inject, Recall -- and Claude Code out of the box fails at two of them.
- Add the MemSearch stop hook today -- it captures everything your auto-memory misses with zero extra cost (Haiku is cheap).
- Split your CLAUDE.md into SOUL.md / USER.md / MEMORY.md right now -- the frozen snapshot injection pattern gives you Hermes recall quality for free.
- Build the Tier-0 check: before any vector DB query, check what is already in context -- instant and free.
- The free plan.md at scrapeshq.notion.site/claude-memory-systems is a paste-in blueprint -- hand it to Claude Code and let it self-install.
- Frame any AI memory content you create around Store / Inject / Recall -- it is the clearest mental model for this category and Joe could own it in the creator space.
Why Claude keeps forgetting things -- and what to do about it.
If Claude Code forgets what you told it last week, that is not a bug -- it is a design gap you can close yourself in an afternoon.
- Your CLAUDE.md is only the start -- think of it as the always-there facts layer, not the full memory system.
- The two free tools worth installing: MemSearch (captures everything) and the Hermes injection pattern (loads the right slice at session start).
- The free plan.md at scrapeshq.notion.site/claude-memory-systems walks you through the whole setup -- paste it into Claude Code and it installs itself.
- Pricing and monetization are the same concept to a vector search -- semantic recall means you do not have to remember the exact words you used.
- You do not need to understand Milvus or embedding models -- the open-source tools handle all of that; you just run the stop hook and the nightly index.