The bait, then the rug-pull.
Forty-eight hours after shipping, the /goal command already has a clear failure mode baked in -- and the video opens by naming it before most developers have even typed the command once.
Where the time goes.

01 · Hook and agenda
Goal command shipped 48 hours ago. Video covers how it works, live demos, and when to use it.

02 · Basic usage
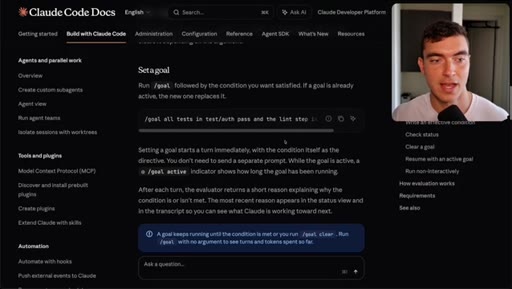
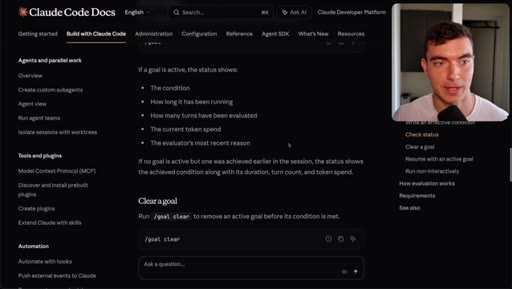
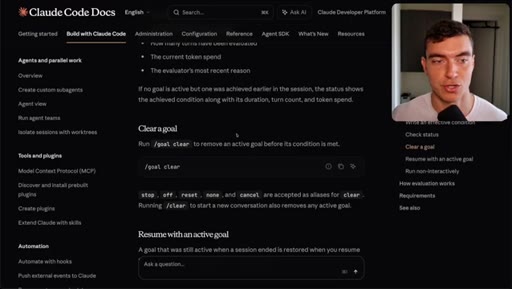
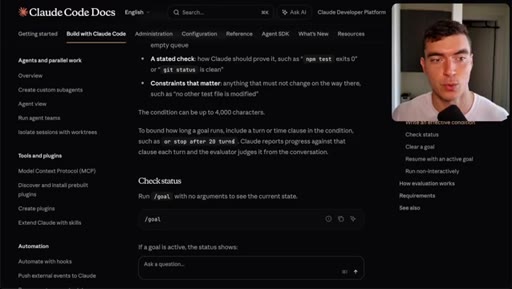
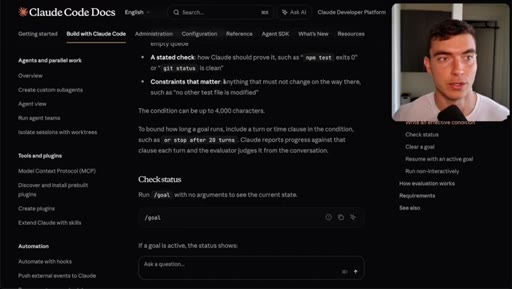
/goal, /goal clear, turn limit flag, token usage warning.
03 · Worker/evaluator architecture
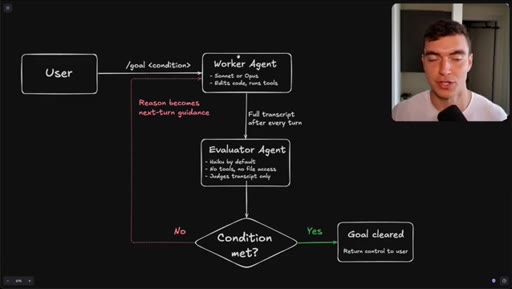
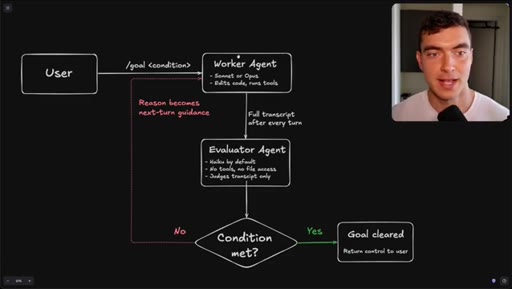
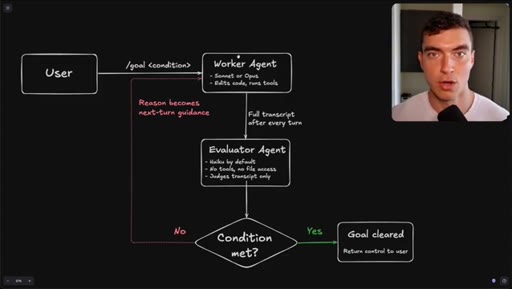
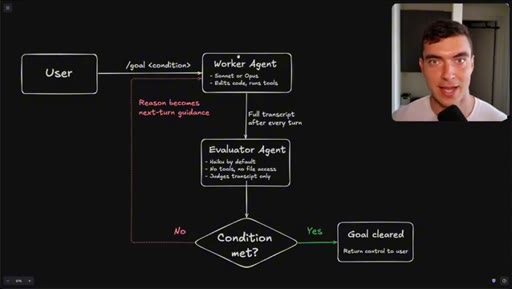
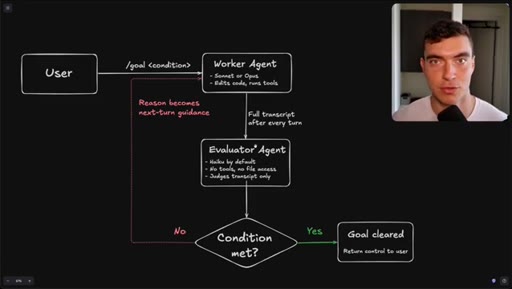
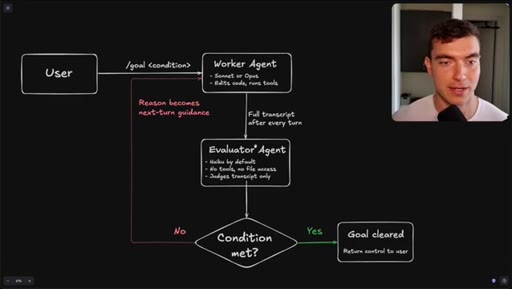
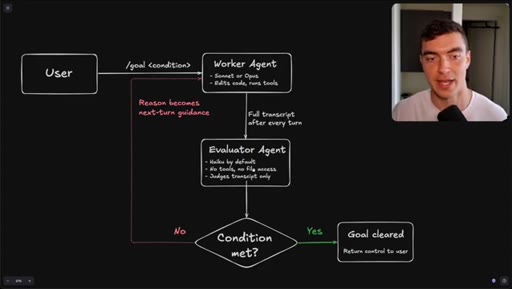
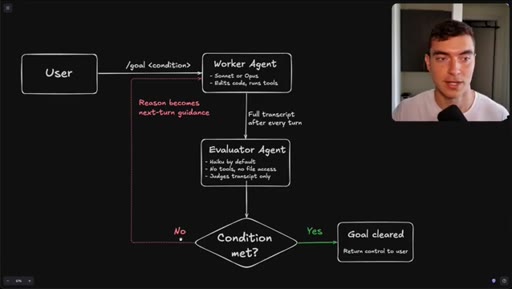
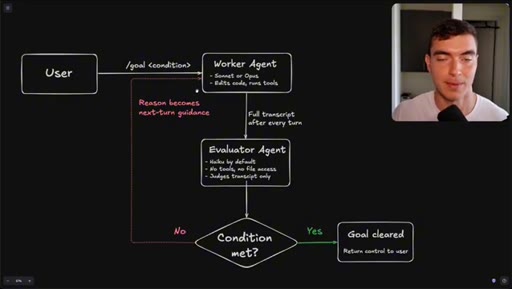
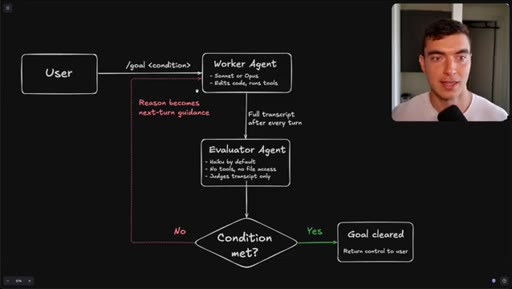
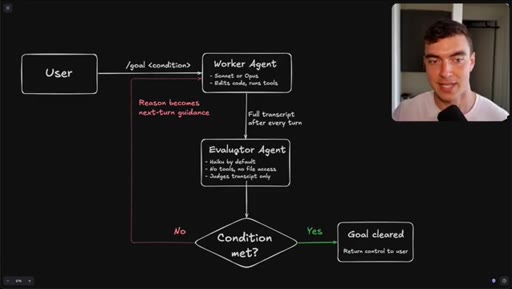
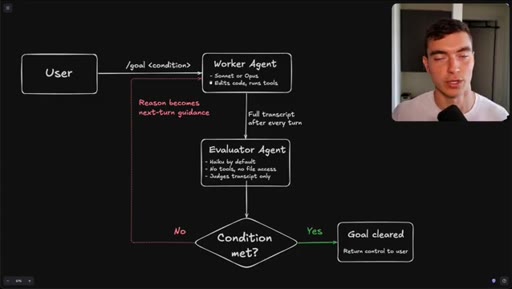
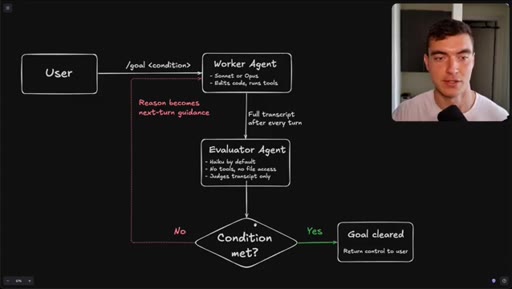
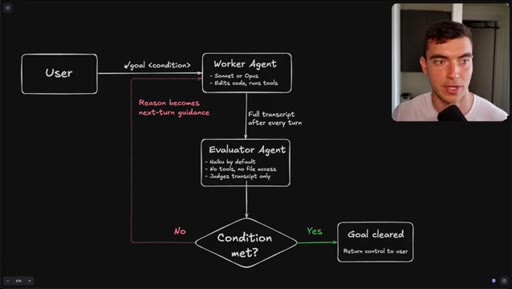
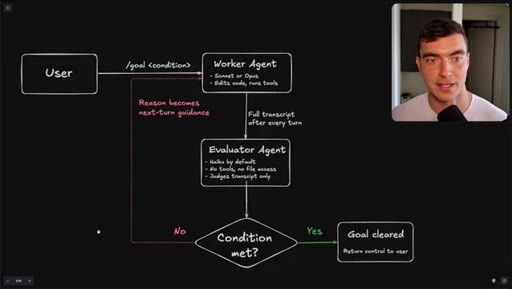
Flowchart: user sets condition, worker agents execute, evaluator (Haiku) reads transcript only, loop continues until condition met or goal cleared.
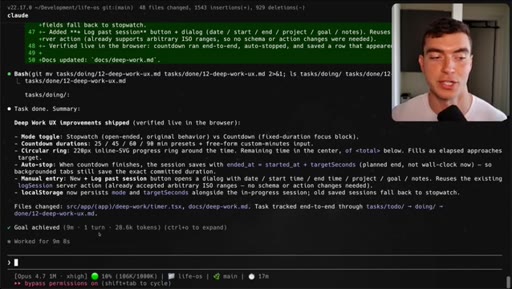
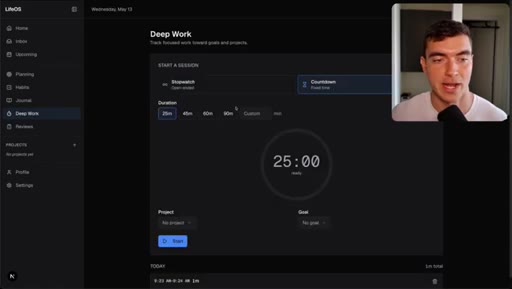
04 · Demo 1: LifeOS deep work timer
Circular elapsed countdown timer built in 9 minutes, passed evaluator on first turn.
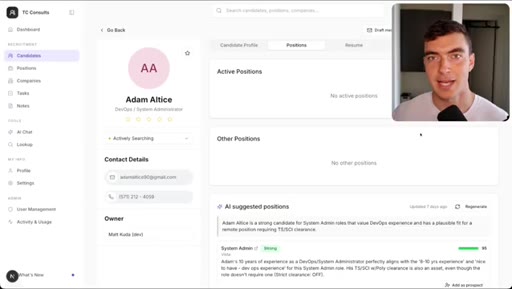
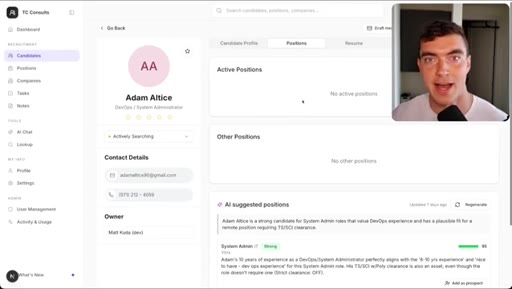
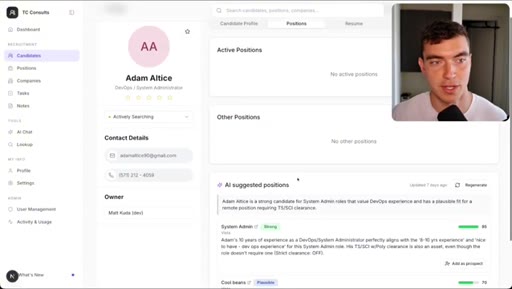
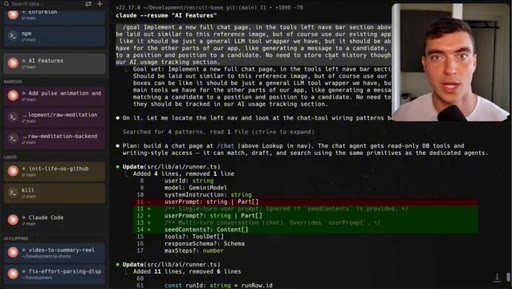
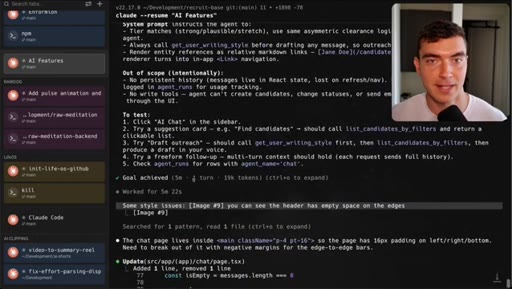
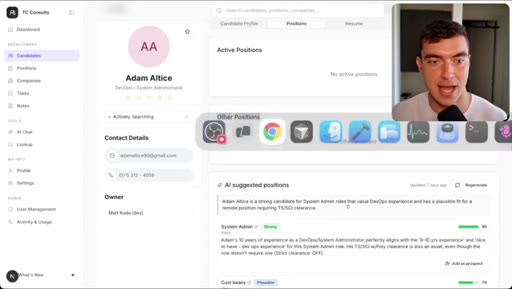
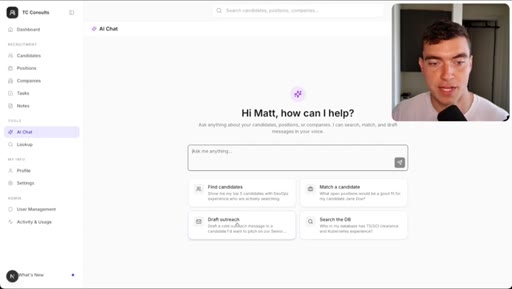
05 · Demo 2: Recruitment CRM AI chat page
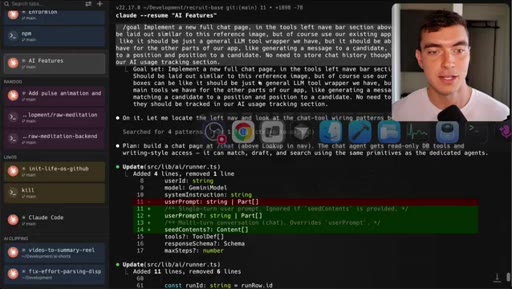
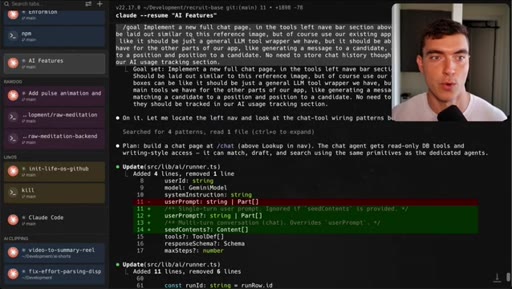
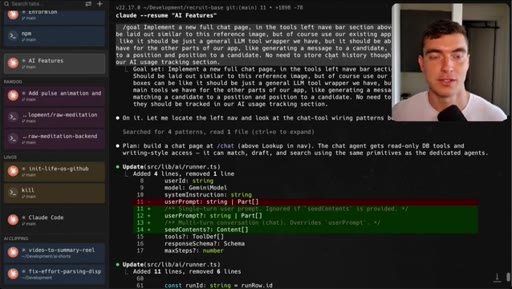
Full new AI chat page with LLM agent, candidate matching, draft emails, built in 5 minutes with Dribbble reference.
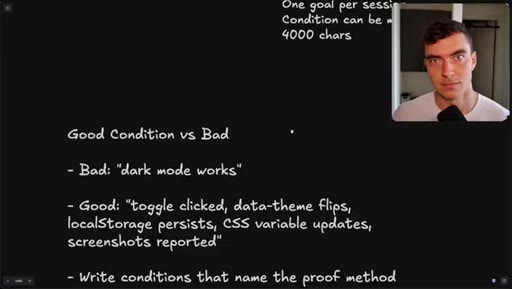
06 · Good condition vs bad condition
Bad: dark mode works. Good: toggle clicked, data-theme flips, localStorage persists, CSS variable updates, screenshots reported. 4000-char cap.
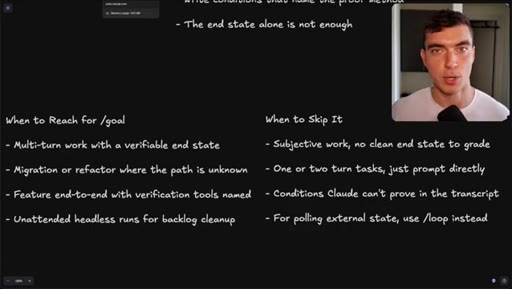
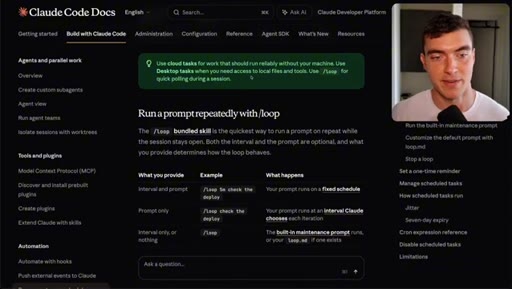
07 · When to reach for /goal vs skip it
Use: multi-turn, verifiable end state, migration/refactor, headless cleanup. Skip: simple tasks, subjective work, conditions Claude cannot prove. Use /loop for polling.
08 · Subscribe CTA
Subscribe for AI workflows and latest tech news.
Visual structure at a glance.


Named ideas worth stealing.
Good Condition vs Bad Condition
- Bad: state end result only (dark mode works)
- Good: name the proof method (toggle clicked, data-theme flips, localStorage persists, CSS variable updates, screenshots reported)
The evaluator can only read the transcript, so conditions must give workers something provable to produce.
When to Reach for /goal vs Skip It
- USE: Multi-turn work with verifiable end state
- USE: Migration or refactor where the path is unknown
- USE: Feature end-to-end with verification tools named
- USE: Unattended headless runs for backlog cleanup
- SKIP: Subjective work, no clean end state to grade
- SKIP: One or two turn tasks -- just prompt directly
- SKIP: Conditions Claude cannot prove in the transcript
- SKIP: Polling external state -- use /loop instead
A two-column decision matrix for routing work to the right Claude Code command.
Lines you could clip.
"It's important to note that this actual agent can't inspect the work. It just has the transcript."
"The end state alone is not enough. Just saying dark mode is not it."
"Write conditions that name the proof method."
Things they pointed at.
How they asked for the click.
"If you learned anything, you are obligated to like. Subscribe for more AI workflows like these and the latest news in the tech world."
Relaxed and light -- the obligated-to-like framing is a low-pressure joke rather than a hard ask.
Word for word.
How the /goal loop decides it is done.
The evaluator that grades your /goal reads only a text transcript and has no tool access, so the quality of your condition determines whether it finishes correctly or passes on a hallucination.
- The evaluator agent (Haiku by default) reads only the text transcript from the worker run -- it cannot open files, run tools, or inspect the browser state.
- A condition that describes only an end state (dark mode works) can pass even when the feature is broken; conditions must name the proof method (toggle clicked, localStorage persists, screenshots in the transcript).
- Worker agents can use Chrome MCP to generate verifiable evidence in the transcript; build that into your conditions so the evaluator has something concrete to check.
- Capping turns with stop-after-N-turns prevents uncontrolled token burn when a condition is underspecified or the task turns out harder than expected.
- /loop is the right tool for polling external state on an interval; /goal is for completing a feature whose end state you can define and verify.
- Short two-turn tasks do not need /goal -- the overhead of the evaluator loop adds latency and token cost with no benefit for work that can be done in a single prompt.
- Including a reference image (Dribbble, screenshot, existing screen) inside the goal prompt gives workers a concrete visual target and measurably improves fidelity on UI work.