The bait, then the rug-pull.
Brad opens by naming the exact gap most AI-forward builders hit: a second brain full of context is not the same as a business that ships work. The promise is tight — two layers, you've only built one, here's the other — and he backs it with a working demo before the minute mark.
What the video promised.
stated at 00:32 "I wanna show you what that looks like, how to build one without locking yourself into Claude or OpenAI forever, and how to share it across your team so every new hire and every agent works at your level on day one." delivered at 07:00
Where the time goes.

01 · The Missing Layer
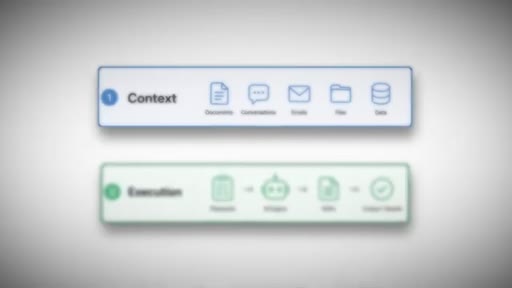
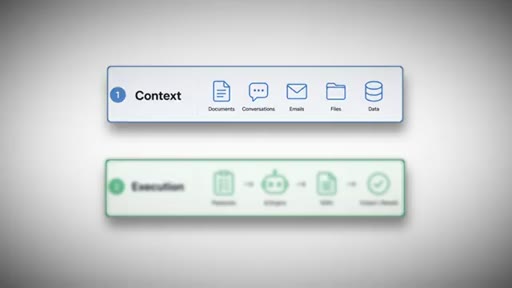
Cold open: two-layer model introduced (context + execution). Hook: 'Building a second brain isn't enough.' Sets up the whole video premise.

02 · Inside My Company Brain
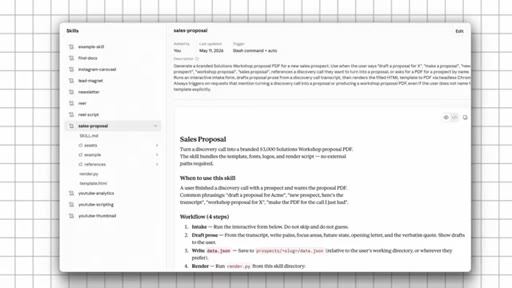
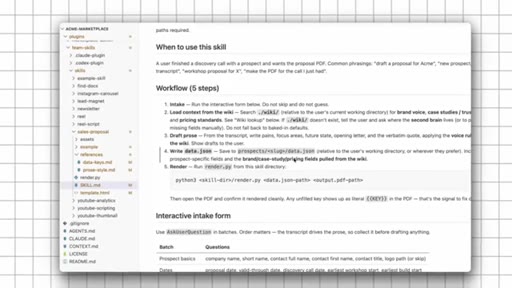
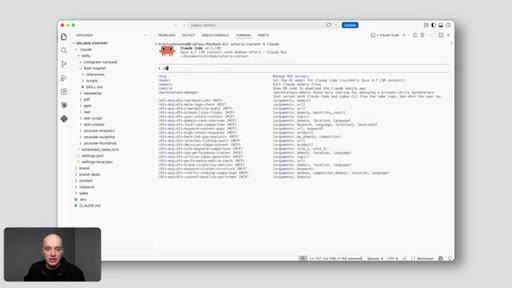
Obsidian demo. Shows /generate-proposal skill pulling live call transcript + pricing playbook. Brain holds context; skill ships the work.

03 · Why Local Skills Break for Teams
The drift problem — Slack, Drive, org skills all fail when team is split across Claude Code and Codex. Every copy diverges.
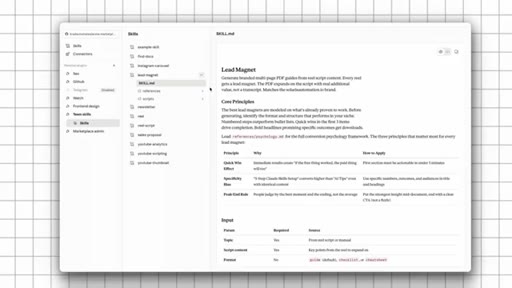
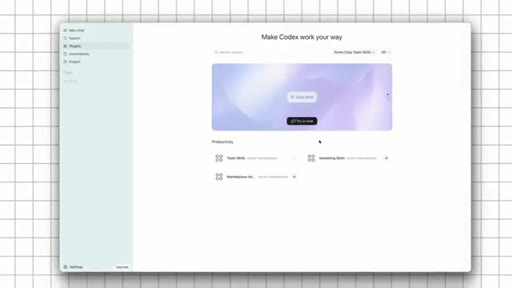
04 · The Private Team Marketplace
One install command, auto-sync, tool-agnostic. 'Five person team shipping like a 50 person team.' Execution + context = leverage.

05 · Two More Problems It Fixes
Teaser: baseline quality problem and documentation adoption. Resolved later in the PR-back loop section.

06 · Hard-Code vs. Reference Context
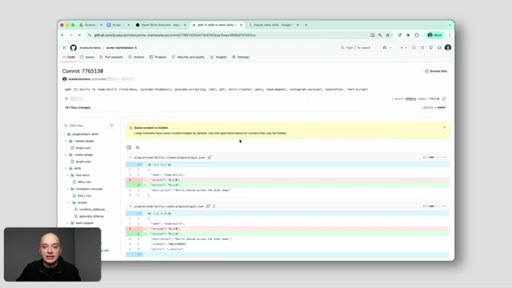
Core pattern: hard-coding context in skills = fragile. Referencing from the brain = single source of truth. Every skill that points at a live file gets the update automatically.

07 · Why Skills Decay on One Machine
You build a skill, get busy, file goes stale. Personal productivity up, team output flat. Team marketplace fixes the decay loop.
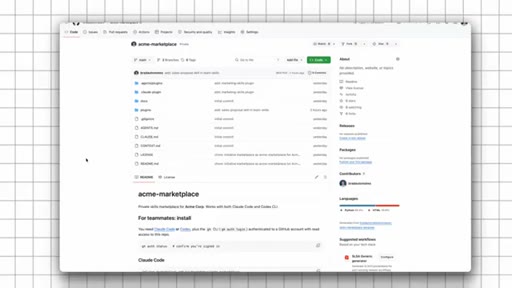
08 · Why It Works Across Every AI Tool
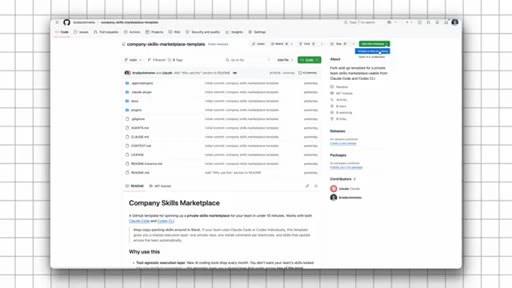
Just a private GitHub repo. Agent skills are an open standard — Claude Code, Codex, and whatever ships next all read the same .md format natively.
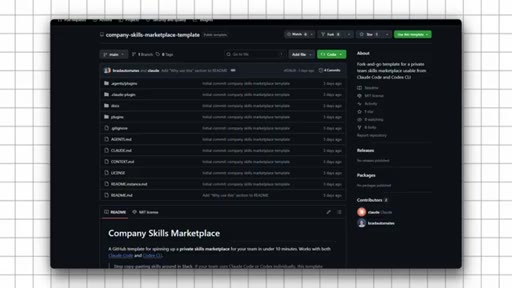
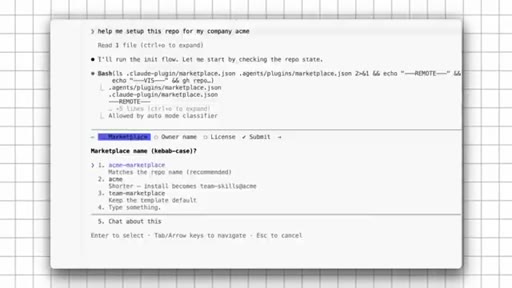
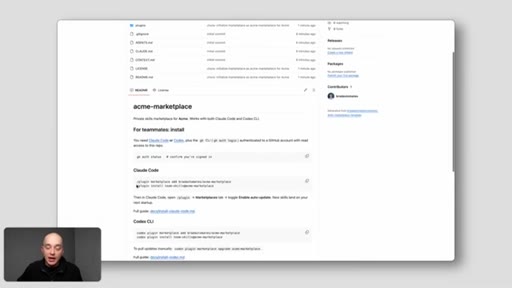
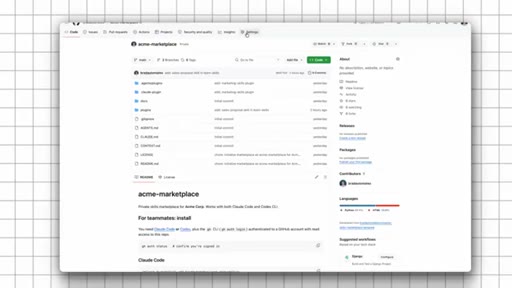
09 · Set Up the Free Template
Use template on GitHub, set private, name it, clone locally, ask Claude to read README and run setup, push to GitHub, copy install commands.
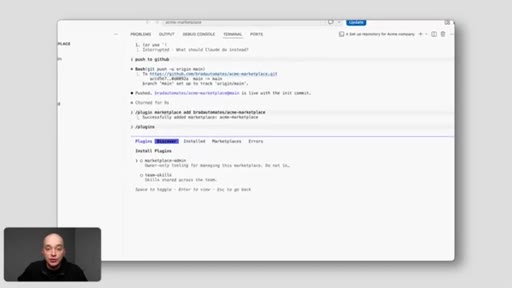
10 · Browsing and Installing Plugins
/plugins, marketplaces, Acme is there. Install team skills + marketplace admin. Fresh Claude session.
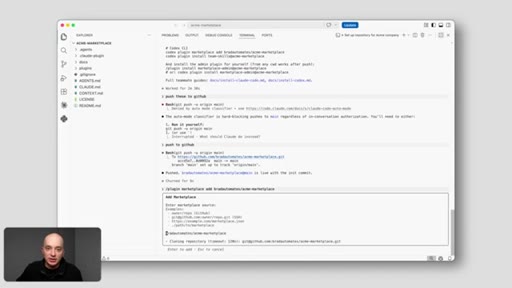
11 · Pushing Your Own Skills In
Marketplace manager skill copies skills from anywhere on machine. Point and say 'add this.' Plugin version bumped automatically.

12 · Scaling to Sub-Plugins
Sales, ops, CS plugins in the same marketplace but separate. Teammates install only what's relevant. Scales as the org grows.

13 · The PR-Back Loop
Correction in the field, push to marketplace, baked in for everyone next run. New hire runs on every lesson ever taught. Quality lottery gone.

14 · CTA + Watch Next
Watch Next card for the brain-build video. Free template and skills marketplace waitlist in description.
Visual structure at a glance.
Named ideas worth stealing.
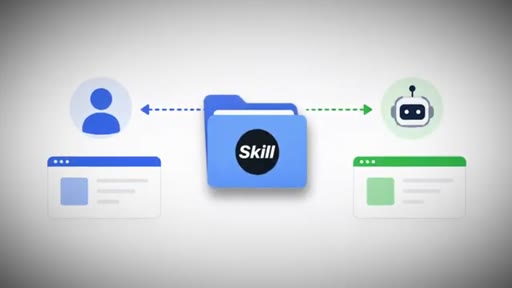
The Two-Layer Brain
- Context Layer (Obsidian docs, transcripts, emails)
- Execution Layer (skills/.md files that run playbooks and return finished work)
A second brain needs two layers to actually run a business. Most people only build the context layer.
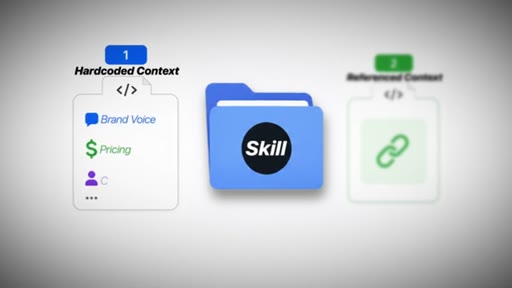
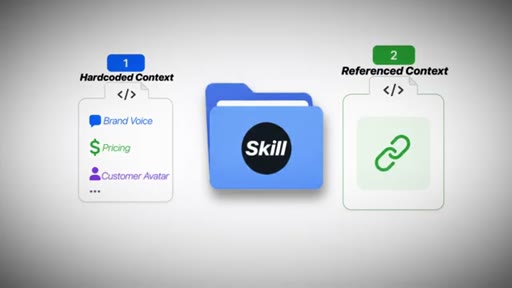
Hard-Code vs. Reference Context
- Option 1: Hard-code context (brand voice, pricing) into each skill — fragile, drifts
- Option 2: Reference context from the brain — single source of truth, auto-updates
Referencing beats hard-coding. One update propagates everywhere. Hard-coding compounds as skill count grows.
The Decay Loop and the Fix
- Local skills decay: built, used, gets busy, goes stale
- Team marketplace breaks the loop: used, correction found, pushed, baked in for everyone
Team skills are self-sharpening because they are the thing actually doing the work, so every run is a chance to improve them.
Tool-Agnostic Marketplace
- Private GitHub repo = the marketplace
- Agent skills (.md format) are an open standard
- Claude Code, Codex, future tools all read the same files natively
- You own the layer; the tools are replaceable
Building on the open agent skills standard means your IP is portable and not locked to any one AI vendor.
Lines you could clip.
"Building a second brain for your business isn't enough."
"That's how a five person team starts shipping like a 50 person team."
"You own the layer, which means the tools you run it in are replaceable."
"Every new hire inherits every lesson learned. Every agent runs at the same level as your best operator."
How they spent the runtime.
Things they pointed at.
How they asked for the click.
"If you don't have the brain side built out yet, that should be your next watch."
Clean soft CTA — links to complementary video (the context layer build), plus template link and waitlist in description. No hard sell.
Word for word.
Steal the execution layer frame.
The gap isn't missing context — it's missing the layer that turns context into shipped work.
- Frame every AI workflow tutorial around the two-layer model: context + execution. It names the gap people feel but can't articulate.
- Build skills that reference live context from the brain, not hard-code it — one brain update propagates everywhere.
- The GitHub-as-marketplace idea is free, self-hosted, and tool-agnostic. This is the MCN+ pitch for team AI workflows in a box.
- The PR-back loop is the most under-explained idea in the video — every correction a team makes improves the skill for everyone. Mine it for a Killing Excuses or LFB episode.
- 'The quality lottery is gone' and 'the new hire inherits every lesson learned' are steal-worthy hook angles worth building content around.
What this means if you use AI tools at work.
The problem isn't that AI tools don't work — it's that everyone on your team is running a slightly different version of the playbook.
- If you have one AI workflow that works great for you, the next step is turning it into a shared file your teammates can install in one command.
- Don't paste your brand voice or pricing into every AI prompt — put it in one shared file and point every prompt at it. Change it once, update everywhere.
- A private GitHub repo is free, takes five minutes to set up, and doesn't care whether your team uses Claude Code, Codex, or something that doesn't exist yet.
- Every time someone on your team improves a workflow, have them push the fix back to the shared repo. One correction becomes a permanent upgrade for everyone.