The bait, then the rug-pull.
Every AI influencer channel dropped an AIOS video this week. The problem, according to this practitioner, is that nearly all of them are wrong -- not on the technical concepts, but on the fundamental question of whether any of it will work inside an actual business.
Where the time goes.

01 · Cold open: the noise problem
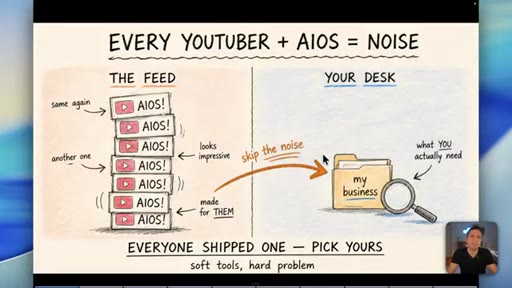
Every influencer just dropped an AIOS video. Most are technically correct but operationally wrong for businesses.

02 · The three pillars and the Michelin analogy
Reliable, accurate, predictable -- the backbone of any AI operating system. The Michelin star kitchen analogy: a small menu means consistent output. Simplicity is the meta-rule.

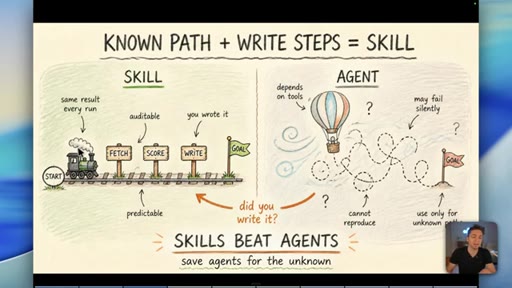
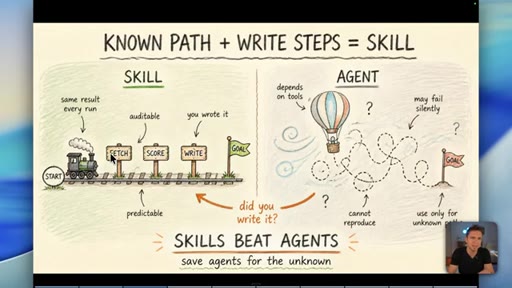
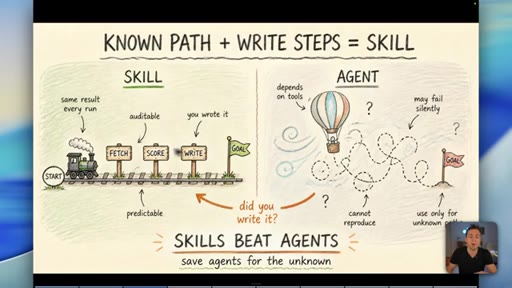
03 · Myth 1: You don't need agent front-ends
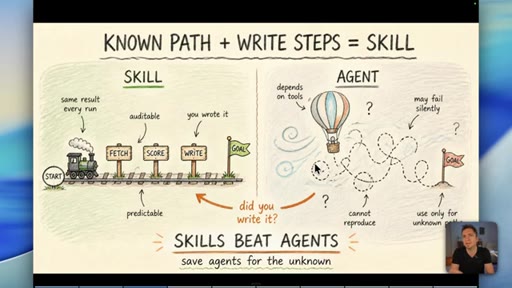
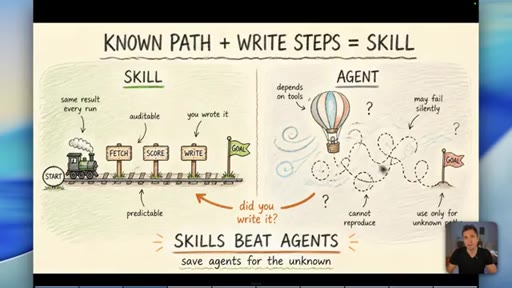
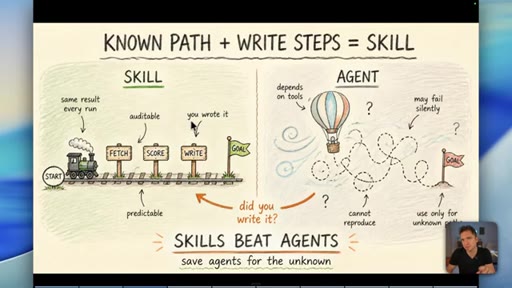
Skills (known-path workflows) beat agents for anything where you can write down the steps. Agent front-ends exist to look impressive on YouTube, not to serve business outcomes.
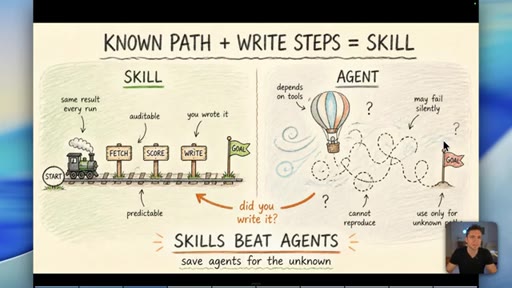
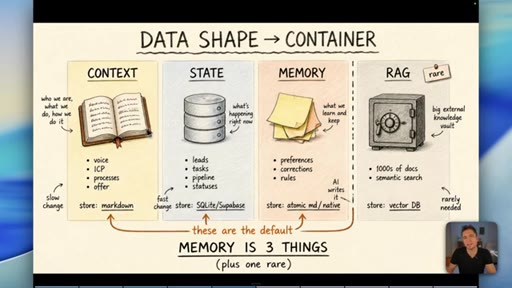
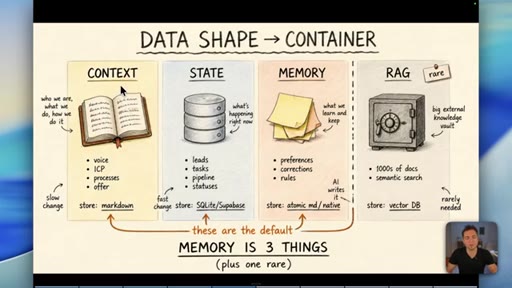
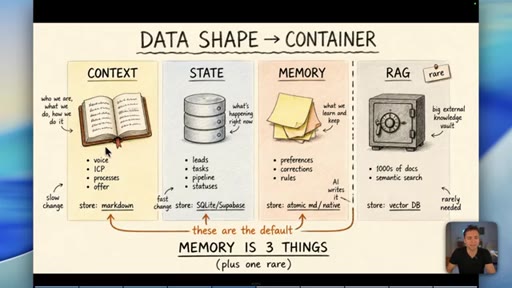
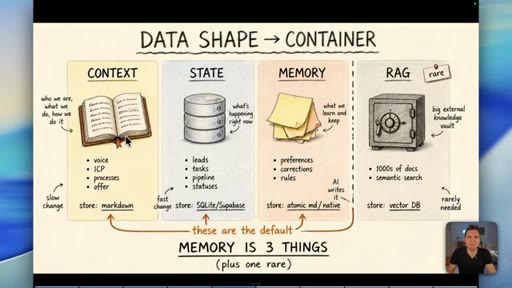
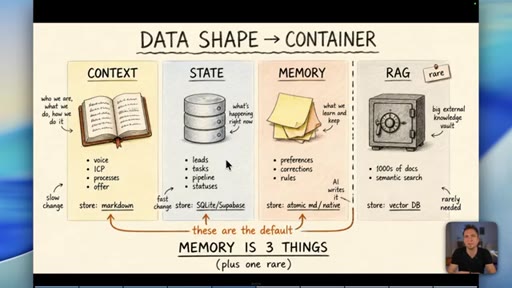
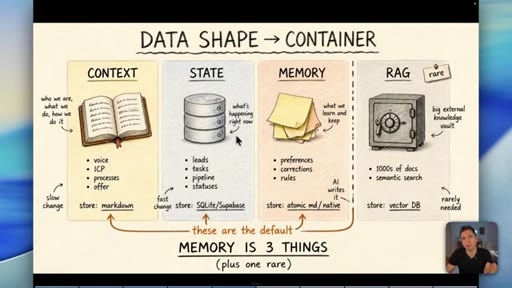
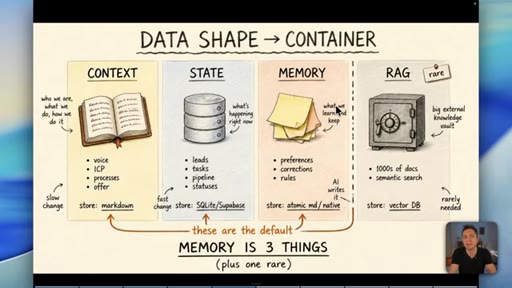
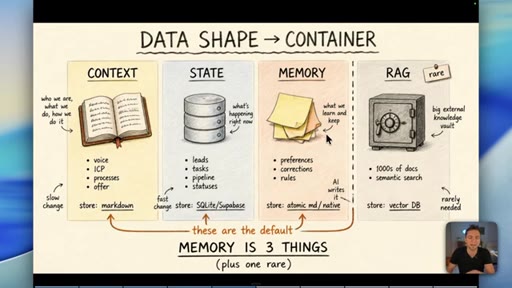
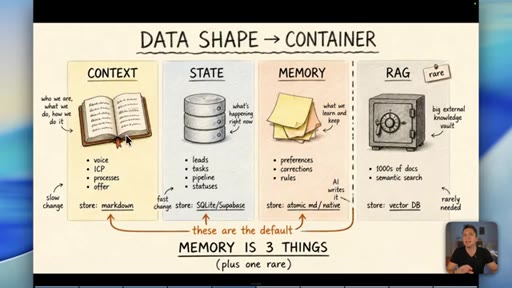
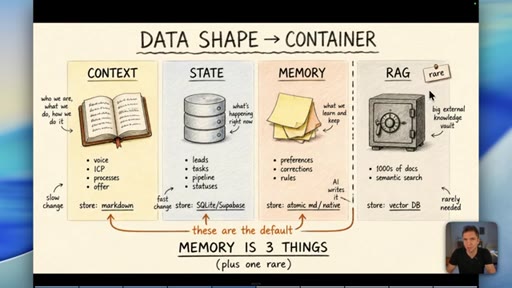
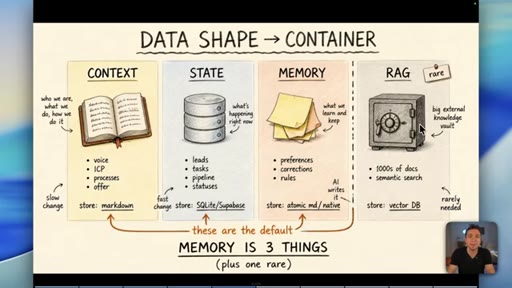
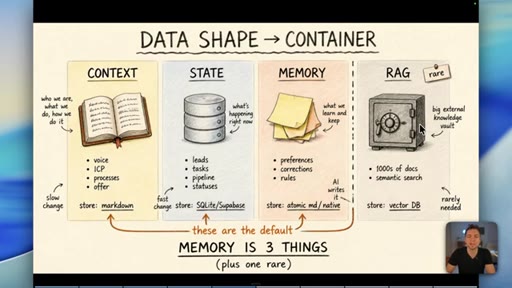
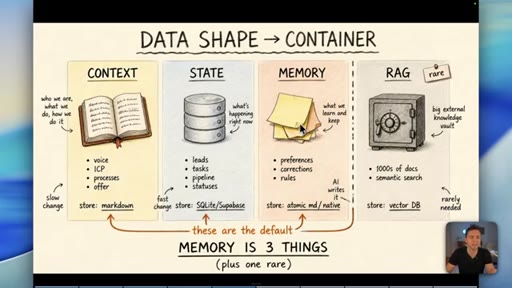
04 · Myth 2: Memory is three things, not one
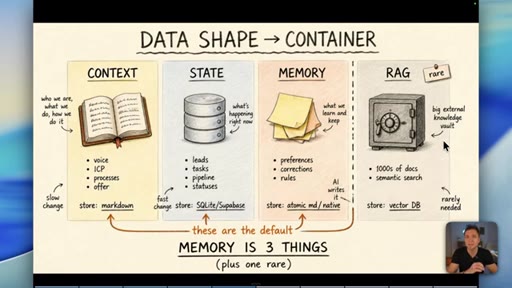
Context/knowledge (markdown), state (database), and learned memory (atomic/native) are different containers. Conflating them is where most builds fail.
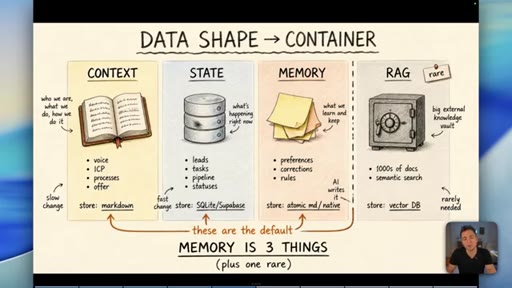
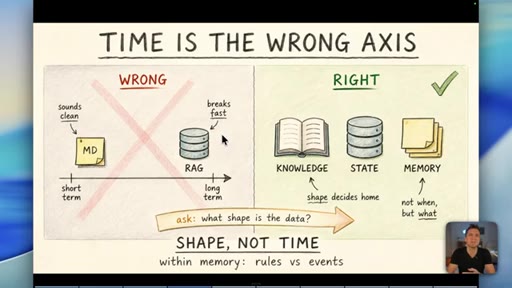
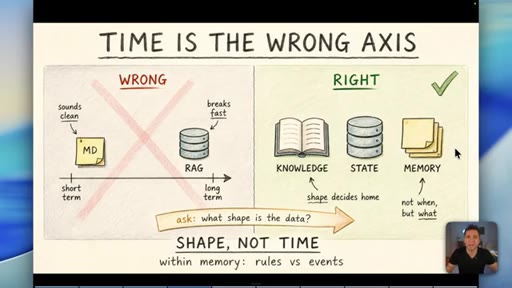
05 · Why RAG is the wrong default for memory
Short-term vs long-term memory is the wrong axis. Data shape decides the container, not time. RAG is for thousands of documents -- most businesses never need it.

06 · Myth 3: Stop migrating everything to Obsidian
Claude cannot use Obsidian semantic search or backlinks -- those are human features. Skill portability: context lives with the skill folder. The 20K demo problem.
07 · Human layer vs AI layer
Will a human read it? is the right decision framework. Notion beats Obsidian for team collaboration. Apps are for humans; files last, apps change.

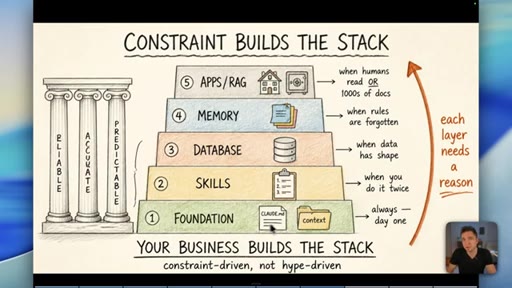
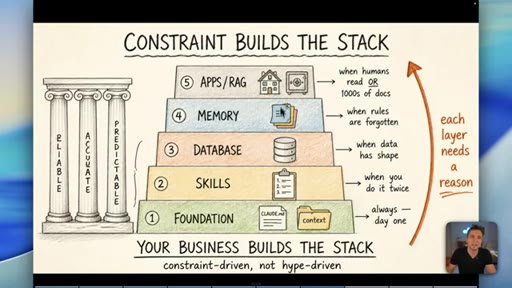
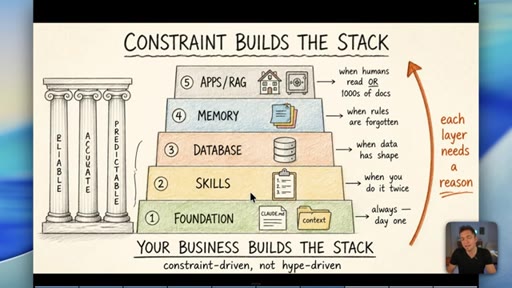
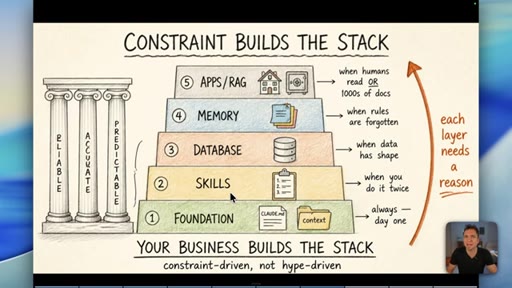
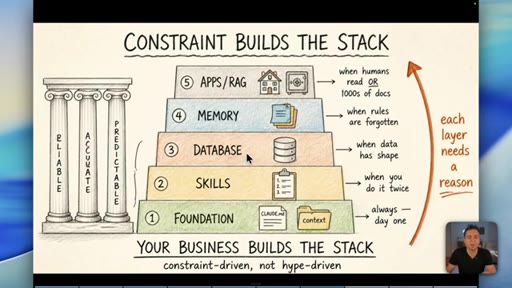
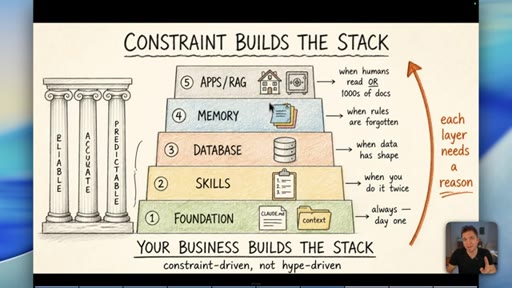
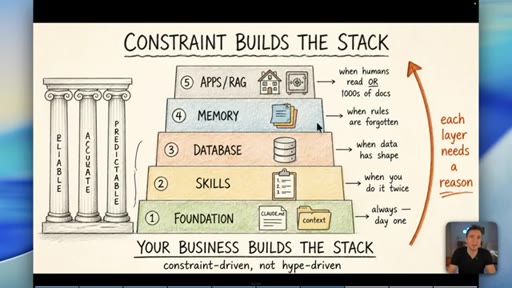
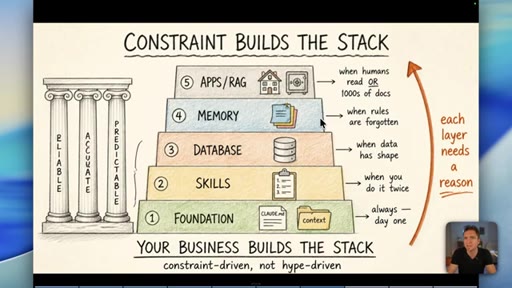
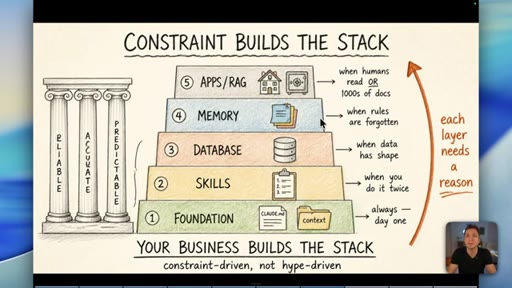
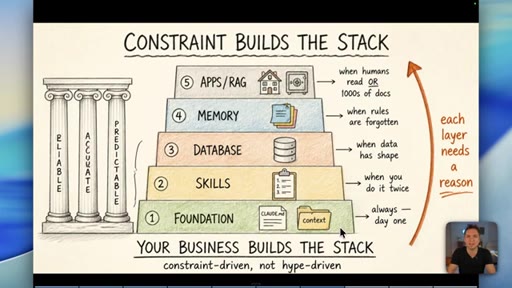
08 · The Constraint-Build-Stack
Five-layer pyramid: Foundation, Skills, Database, Memory, Apps/RAG. Each layer earns its place when the constraint demands it. Constraint-driven, not hype-driven.
Visual structure at a glance.


Named ideas worth stealing.
Reliable + Accurate + Predictable
The three non-negotiable pillars of a business AI operating system. Every architectural decision should be measured against these three criteria.
Skill vs Agent Decision Rule
- Known path? Write a skill.
- Unknown path? Use an agent.
- Can you write down the steps? Always start there.
A binary decision rule for when to use a defined workflow versus an open-ended AI agent. If the path is predictable, it should be a skill.
Data Shape Determines Container (Memory is 3 Things)
- Context/Knowledge: slow-changing business info -> markdown
- State: fast-changing operational data -> database
- Memory: AI-learned preferences/rules -> atomic md / native
- RAG: semantic search across 1000s of docs -> vector DB (rare)
A four-container memory model replacing the oversimplified short-term/long-term split. The data shape -- not its age -- determines which container it belongs in.
Will A Human Read It?
The single question that determines whether you need an app with a human-facing UI versus a plain file in a skill folder.
Constraint Builds The Stack
- 1. Foundation (CLAUDE.md, context)
- 2. Skills (when you do it twice)
- 3. Database (when data has shape)
- 4. Memory (when rules are forgotten)
- 5. Apps / RAG (when humans read it or 1000s of docs)
A bottom-up five-layer pyramid where each layer is only added when a real operational constraint demands it. Your business problems build the stack -- not YouTube trends.
Lines you could clip.
"You absolutely do not need to be running agents if the path you have is predictable."
"There is almost no point in having this agent front end apart from having something flashy to show on YouTube."
"Databases were made for state."
"Time is the wrong axis."
"Claude does not use RAG in here. Even if you have the plugins that allow you to use semantic search, that is for you, the human."
"Your business builds the stack. Constraint-driven, not hype-driven."
Things they pointed at.
How they asked for the click.
"Check out the videos on the screen. They'll definitely help you."
Soft end-screen CTA with linked deeper dives in description. Primary offer (Skool community) referenced in description, not verbally during video.
Word for word.
Your constraints should build your stack, not the trends.
The most expensive AI automation mistake is adding a layer before the constraint that justifies it actually exists in your business.
- A skill -- a written, step-by-step workflow -- is always more reliable than an agent when you already know the correct path. Agents are for genuinely unknown territory, not for familiar tasks dressed up as autonomous.
- Memory is not one container. Context belongs in markdown; state belongs in a database; learned preferences belong in native AI rules. Mixing them causes the failures most builders blame on AI.
- RAG is a tool for semantically searching thousands of documents -- it is not a general-purpose memory upgrade. Most businesses will never have a use case that justifies it.
- The question of whether a human will read the output is the only decision framework you need to choose between a file, a database, or an app. Apps are for humans; the AI layer works fine with plain files.
- Obsidian's semantic search and backlinks are human features -- Claude cannot use them. Building your AI operating system around a tool's human-facing features is a category error.
- Starting from your constraints, not from tutorial recommendations, is the fastest path to a reliable system -- because your constraints make the correct tool selection obvious.
- Each layer of a well-built AI stack should exist because a specific operational problem demanded it, not because it looked good in a YouTube thumbnail.