The bait, then the rug-pull.
The course opens on a direct credential: four million dollars a year in profit, 2,000 students taught, and a blunt warning that this is not for beginners. What follows is three hours of systems-level instruction from someone who has made the harness layer of Claude Code into a business.
Where the time goes.

01 · Introduction
Prerequisites, tool setup in Antigravity/VS Code, and course roadmap across 10 sections.
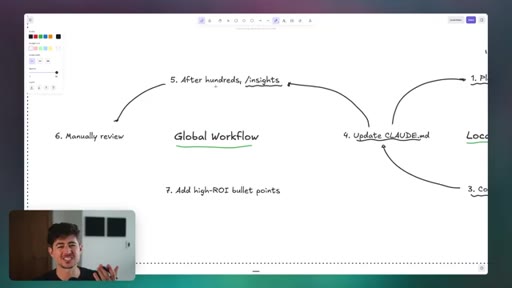
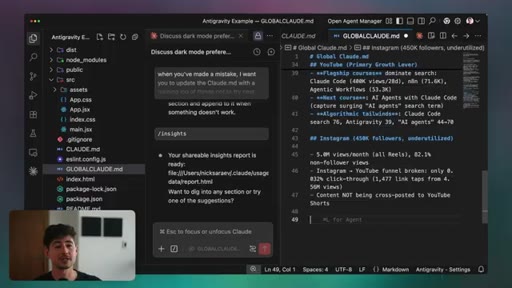
02 · Advanced System Prompts and CLAUDE.md
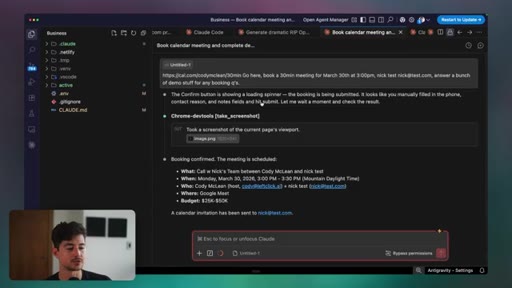
Four functions of CLAUDE.md: knowledge compression, preferences, token conservation, meta-learning. How to build global vs. project-level files and use Claude itself to distill past conversation insights into high-density rules.
03 · Agent Harnesses
Definition of a harness as everything wrapping the LLM. Comparison of Claude Code against Droid, Pydantic AI, Crew AI. Security implications of harness choice.

04 · Parallelization and Agent Teams
Fan-out architecture, stochastic consensus, debate patterns. Parent-researcher-QA system versus lean developer-QA loop. Skills vs. sub-agents structural comparison.
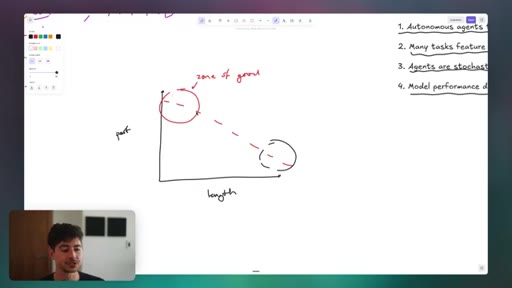
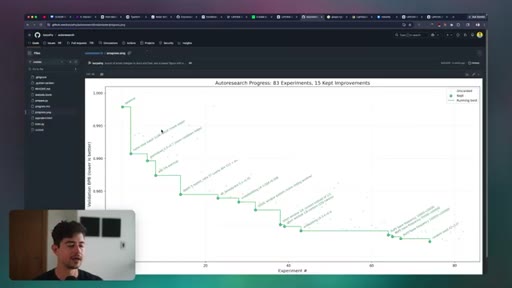
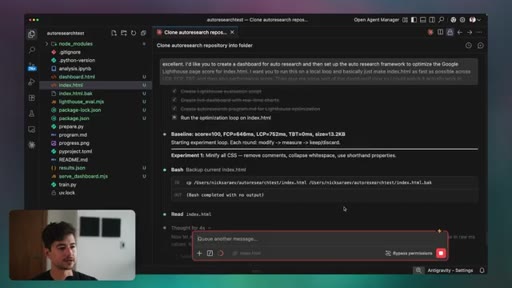
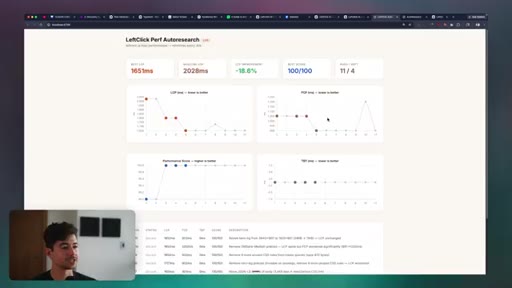
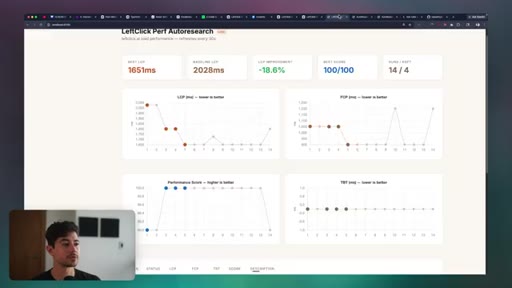
05 · Auto-Research
Karpathy hypothesis-execute-assess loop. Live demo improving leftclick.ai Lighthouse score unattended. How to configure the agent and measurement script for any measurable goal.
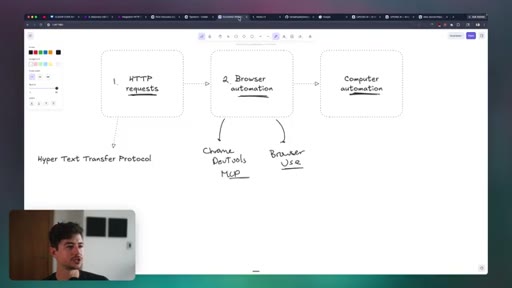
06 · Browser Automation
Three tiers: raw HTTP requests, browser automation (Browser Use, Computer Use), OS-level computer automation. Reliability, detectability, and terms-of-service risk tradeoffs.

07 · Performance Fluctuations and Model Diversification
Monoculture risk of single-model dependency. How to blend Claude, Gemini, GPT-4o, and local models. MCP server integration patterns.

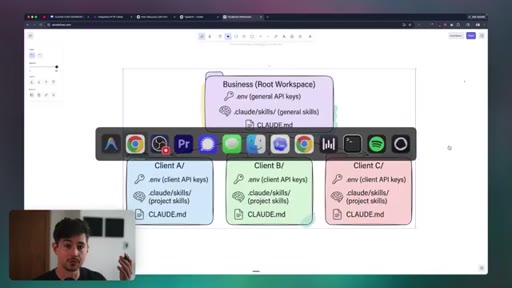
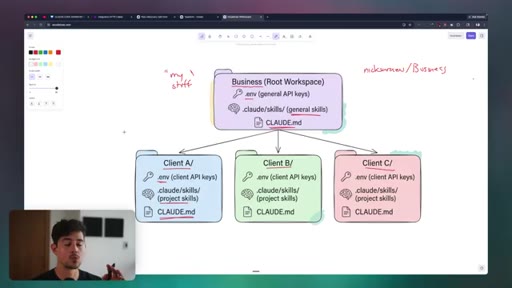
08 · Workspace Organization
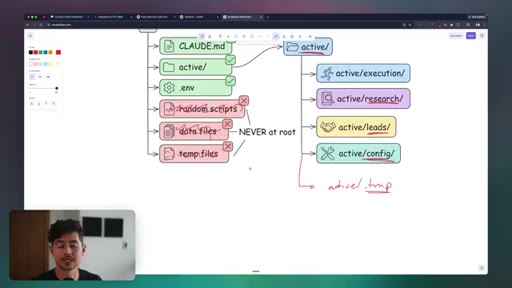
Personal, business, and client project directory structures. CLAUDE.md hierarchy across global, project, and task levels. Directory hygiene and temp file policies.

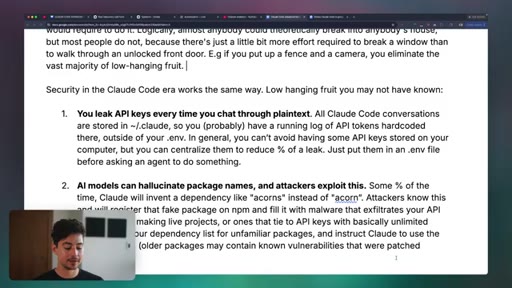
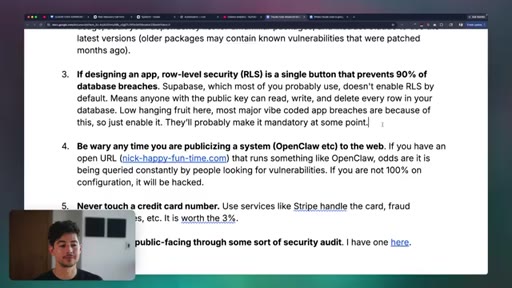
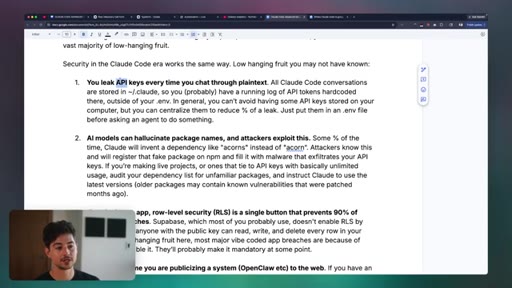
09 · Security
Eight practical security rules: API key centralization, RLS enforcement, dependency injection defense, prompt injection via web content, OAuth basics, and never touching credit card numbers directly.
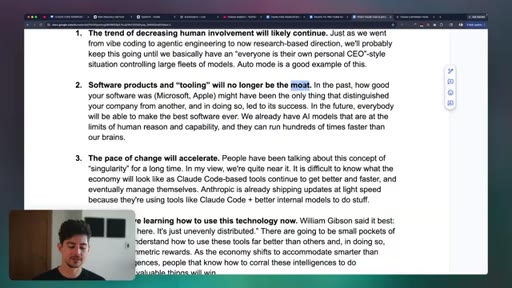
10 · The Future of Claude Code
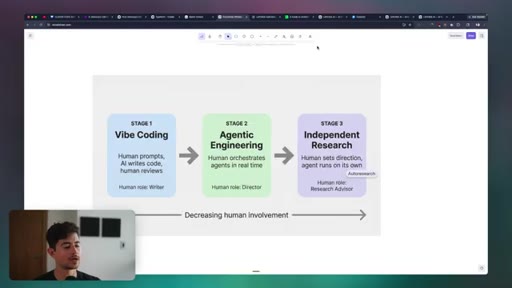
Three predictions: decreasing human involvement, tooling commoditization, accelerating pace of change. Productivity-divide thesis and the William Gibson uneven-distribution quote.
Visual structure at a glance.


Named ideas worth stealing.
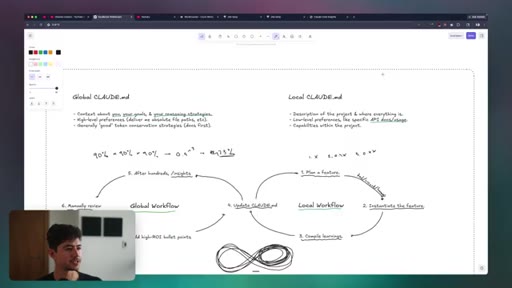
CLAUDE.md Three-Layer Stack
- Global CLAUDE.md (reasoning rules and universal preferences)
- Project CLAUDE.md (codebase map and conventions)
- Task-level context injection (one-off inline context)
Hierarchical configuration that compresses workspace knowledge and personalizes model behavior without repeating context every session.
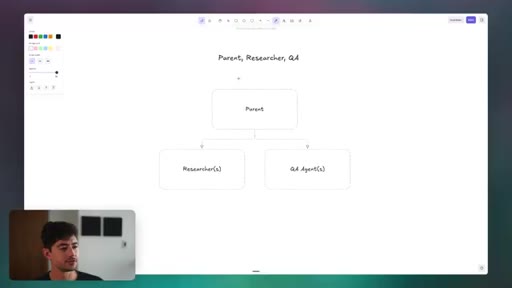
Parent-Researcher-QA Pattern
- Opus orchestrator (plans, decides, builds)
- Sonnet researchers (parallel fan-out, summarize findings)
- Fresh Opus QA agent (no prior context, pure evaluation)
The leanest multi-agent pattern that meaningfully improves output quality by separating research, development, and quality assurance into agents with appropriate context loads.
Karpathy Auto-Research Loop
- Define measurable metric
- Hypothesis: propose a change
- Execute: apply the change
- Assess: measure the metric
- Log result and repeat
An unattended iterative improvement loop for any task with a quantifiable success signal, running overnight without human intervention.
Three-Tier Web Automation Stack
- HTTP requests (fastest, most brittle, no JS rendering)
- Browser automation via Browser Use or Playwright (reliable, detectable, JS-capable)
- Computer use / OS-level GUI control (slowest, most capable)
Match the automation tier to the job. Use HTTP for APIs, browser automation for JS-heavy sites, and computer use only when the other two genuinely cannot do the task.
Lines you could clip.
"An agent harness is just everything that wraps around the LLM that is not the actual LLM itself."
"Every step along the chain that is further from you, the results and the quality is a little bit more diluted."
"You are the 1% right now. You are that group of people that other people will be raising their hands about and shaking their fist at."
"The future is here, it is just unevenly distributed."
Things they pointed at.
How they asked for the click.
"If you guys like this sort of thing, you would be doing me a big solid to subscribe to the channel. For whatever reason, something like 70% of my regular viewers are not subscribed."
Soft, self-aware ask embedded in the final section after the philosophical close. Paired with a request for comment-based video ideas and a mention of enterprise consulting services.
Word for word.
The harness layer is where Claude Code actually compounds.
Every quality and efficiency problem in Claude Code traces back to how well the harness is configured, not how smart the underlying model is.
- CLAUDE.md is not a convenience feature - it is knowledge compression that prevents Claude from re-reading your entire codebase every session and directly cuts token spend.
- A global CLAUDE.md should hold universal reasoning rules; a project-level file holds the codebase map and conventions; task-level context is injected inline and should never pollute permanent files.
- Running Claude over your own conversation history to extract high-density behavioral rules is faster than writing CLAUDE.md rules manually and produces more accurate results.
- Multi-agent delegation adds compound divergence risk at every step: the further a sub-agent is from the original intent, the more diluted the output becomes, which is why flatter architectures beat elaborate org-chart hierarchies.
- The parent-researcher-QA pattern - Opus orchestrates, Sonnet researchers fan out in parallel, a fresh context-free Opus QAs - is the minimum-viable multi-agent setup that produces measurably better output than a single-agent loop.
- Karpathy's auto-research loop - hypothesis, execute, assess, log, repeat - works for any task with a measurable outcome and can run unattended, turning overnight compute into a compounding improvement log.
- Match the web automation tier to the actual job: raw HTTP for APIs, browser automation for JS-heavy sites, computer use only when the other two genuinely fail.
- Relying on a single model for all production work is monoculture risk; routing cheaper research tasks to Sonnet and reserving Opus for orchestration and final QA cuts cost without reducing quality.
- Centralizing all API keys in an env file and never passing them through plaintext Claude Code conversations is the highest-ROI single security habit for any production project.
- Row-Level Security disabled on a database is not a configuration choice to optimize later - it is the root cause of most publicly reported AI-vibe-coded app breaches.
- Dependency injection attacks target AI tools that auto-install packages; auditing any unfamiliar package before installation and preferring pinned version numbers is the practical first-line defense.
- Prompt injection can arrive through web content, OCR output, or any external data the agent reads; treating all external input as untrusted and restricting what the agent can execute based on that input is the correct default.
- The practitioners who internalize agent harnesses now are in a productivity cohort so small that as model intelligence accelerates their economic leverage will be asymmetric relative to everyone who still treats Claude as a chat interface.
- The intelligence curve from current models to human-level is proportionally closer than most people assume and will compress faster in the next 12 to 24 months than it did in the prior five years combined.