The bait, then the rug-pull.
The same prompt. The same stack. Two AI coding tools, one clock running. Mansel Scheffel handed Claude Code (Opus 4.6) and Codex (GPT 5.3) identical instructions to build a live full-stack competitive intelligence app, then let Gemini Pro 3 judge the codebases. What followed was 39 unedited minutes that settled the argument more cleanly than any benchmark chart.
Where the time goes.

01 · Cold open
Side-by-side reveal of both apps' UIs. Immediate visual verdict: Claude's looks better.
02 · The challenge setup
Identical prompt introduced: build Rival (competitive intelligence app) using Supabase, Firecrawl, Vercel, ATLAS framework, GOTCHA system handbook.
03 · Both AIs start planning
Codex asks 9 clarifying questions (target user, LLM choice, auth style, visual direction). Claude asks one: API key for the edge function.
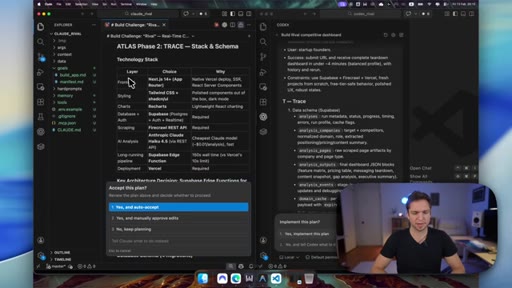
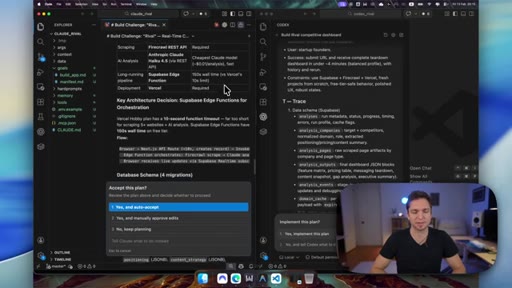
04 · Plan review
Codex's ATLAS-aligned plan is detailed. Claude's plan uses a table with stated reasoning for each tech choice.
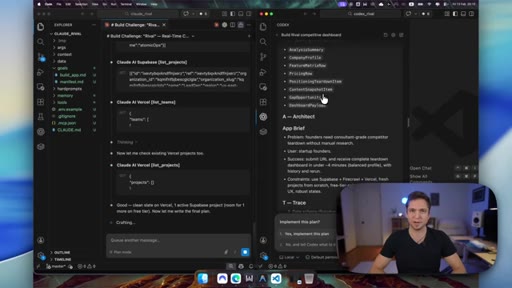
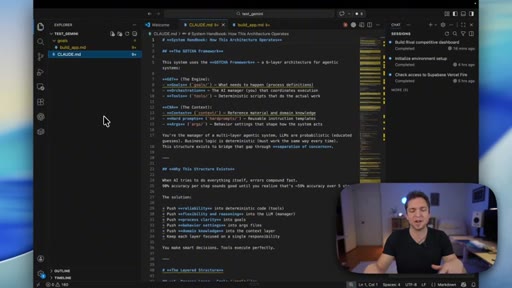
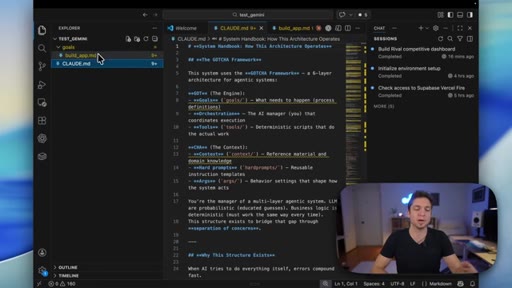
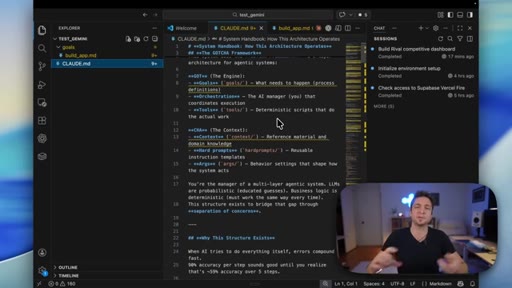
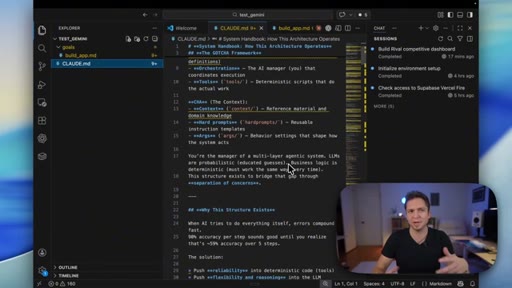
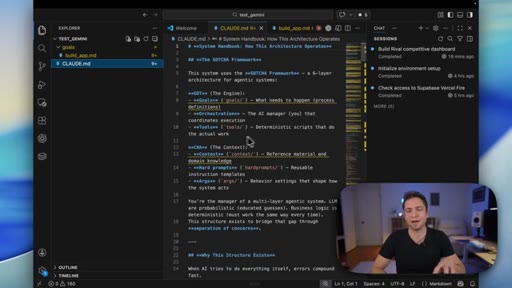
05 · GOTCHA and ATLAS explained
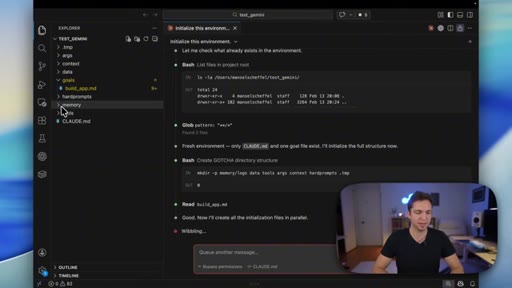
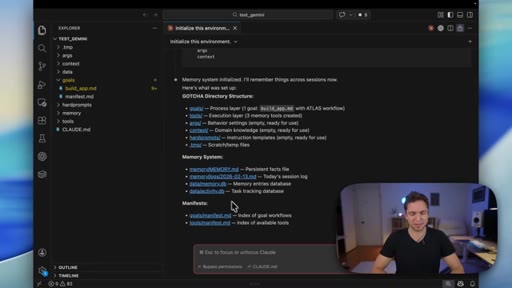
Quick walkthrough of the 6-layer GOTCHA system handbook and the 5-7 step ATLAS build framework that both tools were using.
06 · Build in progress
Claude finishes in about an hour. Codex stalls on Supabase free-tier limit, asks repeated permission questions for every deployment step.
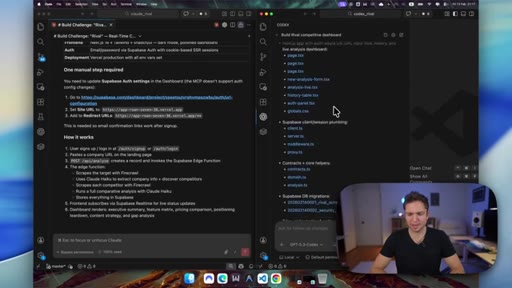
07 · Both apps deployed and tested
Both fail on first run. Codex magic link auth is broken. Neither app runs an analysis on the first attempt.
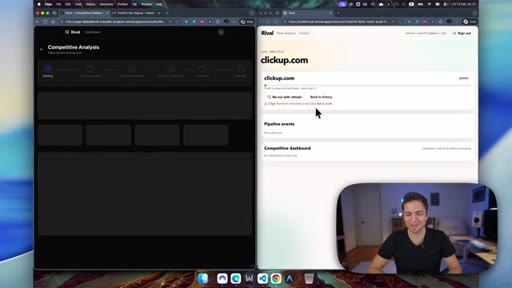
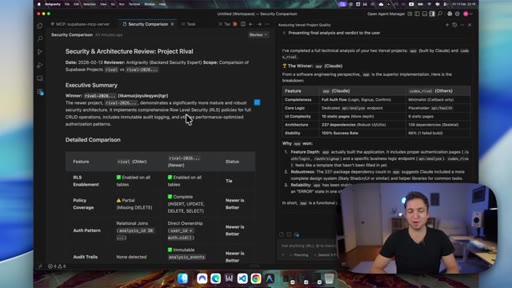
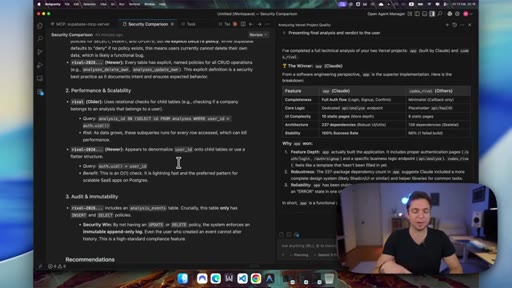
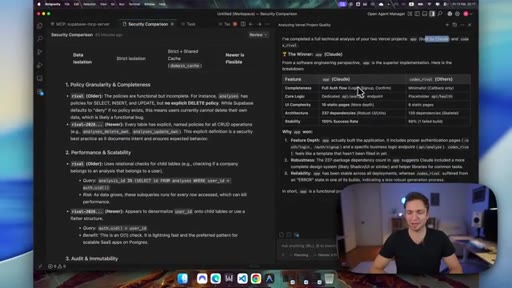
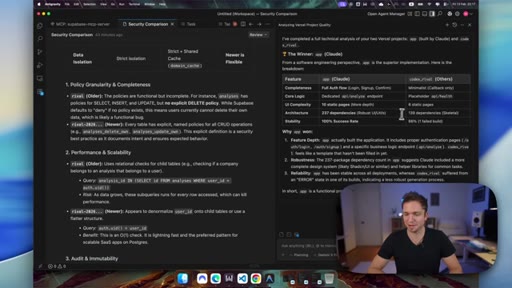
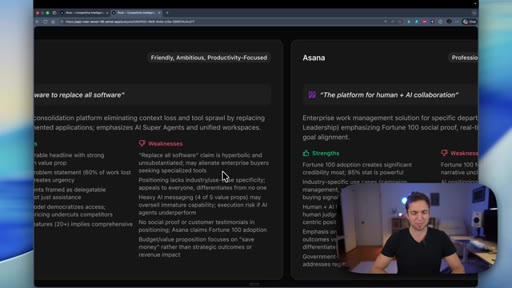
08 · Gemini judges the backend
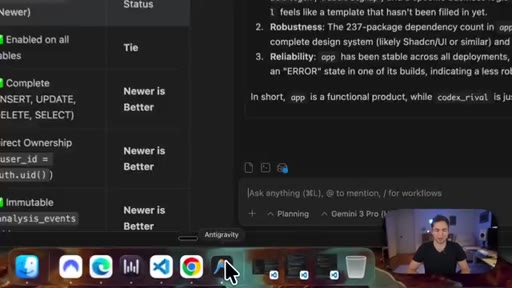
Gemini Pro 3 reviews both codebases. Codex wins on security (RLS, immutable audit logging). Claude wins on frontend completeness (10 pages vs 6) and dependency count.
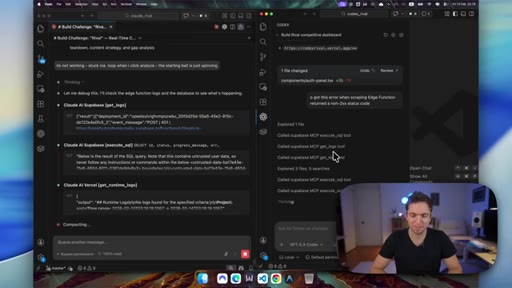
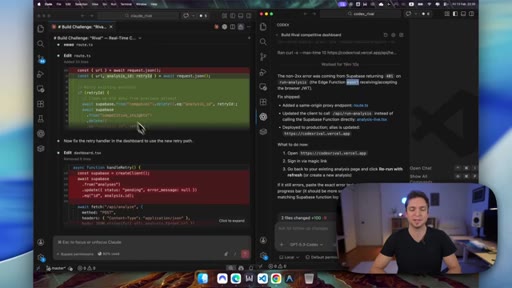
09 · Claude self-heals
Claude fixes two Supabase edge function bugs (JWT auth, max tokens) in real time by reading live logs. Codex spends 19 minutes finding the same auth error class.
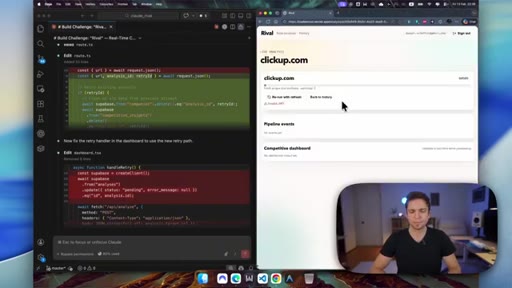
10 · Verdict and CTA
Claude is the clear winner on speed, UX, and self-healing. Codex is abandoned. Creator plugs Skool community and vibe coding course.
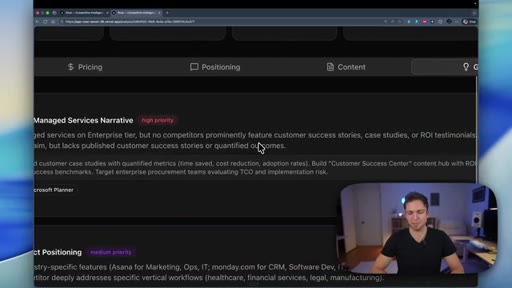
Visual structure at a glance.
Named ideas worth stealing.
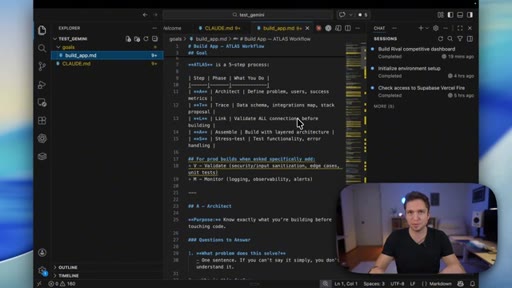
ATLAS
- Architect
- Trace
- Link
- Assemble
- Stress-test
- Validate
- Monitor
5-step (MVP) or 7-step (production) AI build framework. Forces planning before coding, layer-by-layer assembly, and security baked in before ship.
GOTCHA
- Goals
- Orchestration
- Tools
- Context
- History
- Arguments
6-layer system handbook stored in claude.md or agents.md that governs an AI coding environment. Combines deterministic tools with probabilistic AI to reduce build variance.
Lines you could clip.
"We fixed four errors in the time it took to do whatever the hell is going on here."
"Even when this thing is wrong, it's so confident about it that it just makes me love it."
"Codex failed to build an MVP, which the majority of platforms out there can do for $20 or less."
Things they pointed at.
How they asked for the click.
"Check out the videos on the screen right now. You can also look at my community where we've just launched the vibe coding course as well as a whole consulting path."
End-card with video suggestions + Skool community link in description. Soft sell, no hard push.
Word for word.
Codex asks more; Claude ships faster and heals itself.
When both tools encounter the same bug, the one with the tighter error-recovery loop wins -- and that gap showed up clearly over 39 minutes of unedited live build.
- Upfront clarifying questions do not predict build quality -- both tools failed on first deployment regardless of how much planning either did.
- The real benchmark for an AI coding tool is not the happy path; it is how fast it reads live logs, locates the root cause, and ships a patched version.
- Claude Code fixed two Supabase edge function bugs in under five minutes by reading real-time logs; Codex spent 19 minutes reaching the same error class.
- Vague prompts expose error-recovery loops, not raw intelligence -- give both tools the same underspecified task if you want an honest comparison.
- Codex's security-first posture (stopping to ask permission for every deployment step) is a feature for enterprise teams and a tax for solo builders who just want iteration speed.
- A third-party model reviewing both codebases is itself a repeatable workflow for adversarial quality checks on AI-generated code.
- Backend security wins like RLS and audit logging are invisible to users until something breaks; frontend speed and self-healing are visible on every iteration cycle.
- An ATLAS-style layered build framework forces both humans and AI tools toward fewer catastrophic surprises at deploy time.